Los datos de series temporales se pueden ver en todas partes y, para realizar un análisis de series temporales, primero debemos preprocesar los datos. Las técnicas de preprocesamiento de series temporales tienen un impacto significativo en la precisión del modelado de datos.
En este artículo, discutiremos principalmente los siguientes puntos:
Definición de datos de series temporales y su importancia.
Pasos de preprocesamiento para datos de series temporales.
Cree datos de series temporales, encuentre valores faltantes, elimine características y encuentre valores atípicos presentes en el conjunto de datos.
Primero, entendamos la definición de una serie de tiempo:
Una serie de tiempo es una serie de observaciones distribuidas uniformemente registradas durante un intervalo de tiempo específico.
Un ejemplo de una serie de tiempo es el precio del oro. En este caso, nuestras observaciones son el precio del oro recolectado durante un período de tiempo después de un intervalo de tiempo fijo. La unidad de tiempo puede ser minutos, horas, días, años, etc. Pero la diferencia de tiempo entre dos muestras consecutivas es la misma.
En este artículo, veremos pasos comunes de preprocesamiento de series temporales y problemas comunes relacionados con datos de series temporales que deben realizarse antes de sumergirse en la parte de modelado de datos.
Preprocesamiento de datos de series temporales
Los datos de series temporales contienen mucha información, pero a menudo es invisible. Los problemas comunes asociados con las series de tiempo son marcas de tiempo desordenadas, valores faltantes (o marcas de tiempo), valores atípicos y ruido en los datos. De todos los problemas mencionados, tratar con los valores perdidos es el más difícil porque los métodos de imputación tradicional (una técnica de tratar los datos perdidos reemplazando los valores perdidos para conservar la mayor parte de la información) no son aplicables cuando se trata de series de tiempo. datos Para analizar este análisis preprocesado en tiempo real, utilizaremos el conjunto de datos Air Passenger de Kaggle.
Los datos de series de tiempo generalmente existen en un formato no estructurado, es decir, las marcas de tiempo pueden mezclarse y no ordenarse correctamente. Además, en la mayoría de los casos, las columnas de fecha y hora tienen un tipo de datos de cadena predeterminado, y debe convertir la columna de datos y hora en un tipo de datos de fecha y hora antes de aplicarle cualquier operación. Implementemos esto en nuestro conjunto de datos:
import pandas as pd
passenger = pd.read_csv('AirPassengers.csv')
passenger['Date'] = pd.to_datetime(passenger['Date'])
passenger.sort_values(by=['Date'], inplace=True, ascending=True)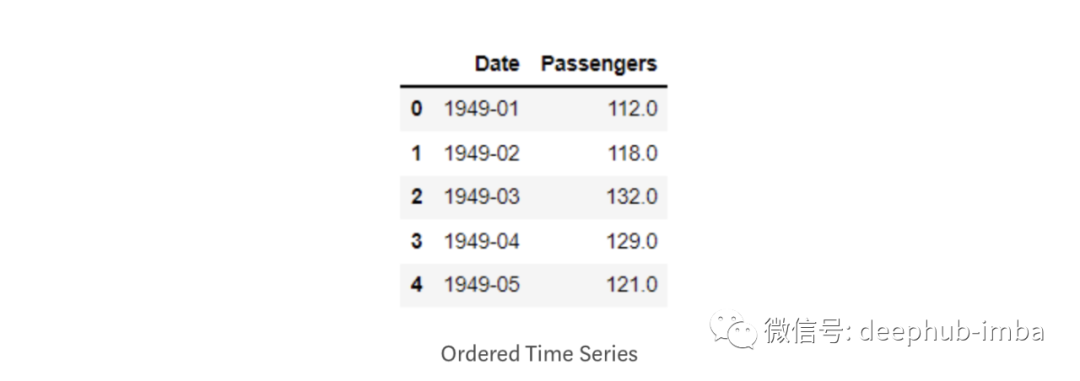
Valores faltantes en series de tiempo
Manejar valores faltantes en datos de series de tiempo es una tarea desafiante. Las técnicas de imputación tradicionales no son adecuadas para datos de series temporales porque el orden en que se reciben los valores es importante. Para resolver este problema, tenemos los siguientes métodos de interpolación:
La interpolación es una técnica de imputación de valores perdidos de series de tiempo comúnmente utilizada. Ayuda a estimar el punto de datos que falta utilizando los dos puntos de datos conocidos circundantes. Este método es simple y el más intuitivo. Los siguientes métodos se pueden utilizar cuando se trabaja con datos de series temporales:
interpolación basada en el tiempo
interpolación spline
Interpolación linear
Veamos cómo se ven nuestros datos antes de la imputación:
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
figure(figsize=(12, 5), dpi=80, linewidth=10)
plt.plot(passenger['Date'], passenger['Passengers'])
plt.title('Air Passengers Raw Data with Missing Values')
plt.xlabel('Years', fontsize=14)
plt.ylabel('Number of Passengers', fontsize=14)
plt.show()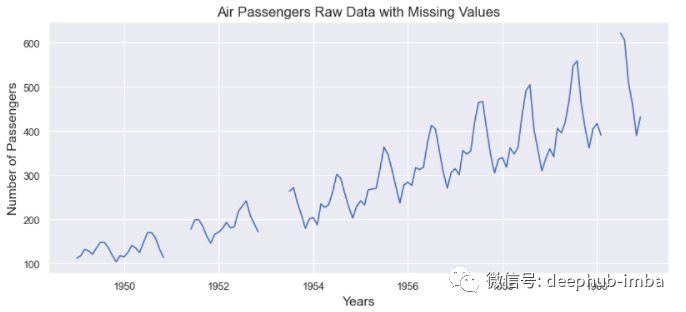
Veamos los resultados de los tres métodos anteriores:
passenger[‘Linear’] = passenger[‘Passengers’].interpolate(method=’linear’)
passenger[‘Spline order 3’] = passenger[‘Passengers’].interpolate(method=’spline’, order=3)
passenger[‘Time’] = passenger[‘Passengers’].interpolate(method=’time’)
methods = ['Linear', 'Spline order 3', 'Time']
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
for method in methods:
figure(figsize=(12, 4), dpi=80, linewidth=10)
plt.plot(passenger["Date"], passenger[method])
plt.title('Air Passengers Imputation using: ' + types)
plt.xlabel("Years", fontsize=14)
plt.ylabel("Number of Passengers", fontsize=14)
plt.show()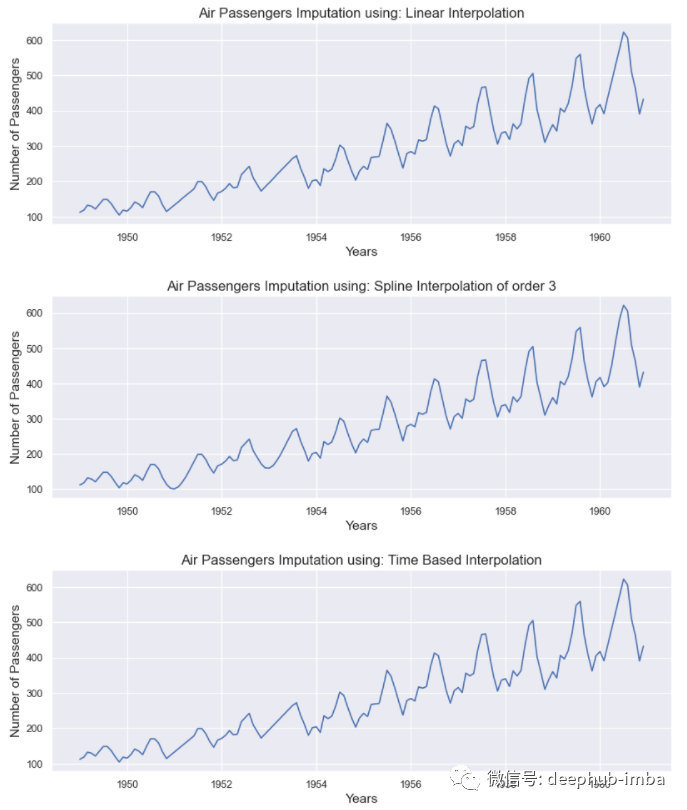
Todos los métodos dan resultados decentes. Estos métodos tienen más sentido cuando la ventana de valores faltantes (el ancho de los datos faltantes) es pequeña. Pero si faltan varios valores consecutivos, estos métodos tienen más dificultades para estimarlos.
Eliminación de ruido de series de tiempo
Los elementos de ruido en las series temporales pueden causar problemas graves, por lo que, en general, se elimina el ruido antes de construir cualquier modelo. El proceso de minimizar el ruido se llama eliminación de ruido. Estos son algunos métodos comúnmente utilizados para eliminar el ruido de las series temporales:
promedio móvil
Un promedio móvil es el promedio de una ventana de observaciones anteriores, donde una ventana es una serie de valores de datos de series temporales. Calcule la media para cada ventana ordenada. Esto puede ayudar en gran medida a minimizar el ruido en los datos de series temporales.
Apliquemos un promedio móvil al precio de las acciones de Google:
rolling_google = google_stock_price['Open'].rolling(20).mean()
plt.plot(google_stock_price['Date'], google_stock_price['Open'])
plt.plot(google_stock_price['Date'], rolling_google)
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend(['Open','Rolling Mean'])
plt.show()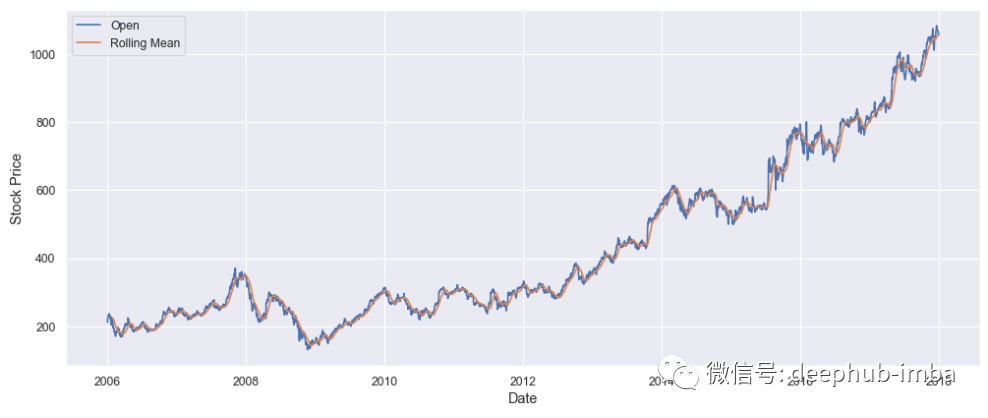
Transformada de Fourier
La transformada de Fourier puede ayudar a eliminar el ruido al transformar los datos de series temporales en el dominio de la frecuencia, podemos filtrar las frecuencias de ruido. Luego se aplica una transformada inversa de Fourier para obtener la serie temporal filtrada. Usamos la transformada de Fourier para calcular el precio de las acciones de Google.
denoised_google_stock_price = fft_denoiser(value, 0.001, True)
plt.plot(time, google_stock['Open'][0:300])
plt.plot(time, denoised_google_stock_price)
plt.xlabel('Date', fontsize = 13)
plt.ylabel('Stock Price', fontsize = 13)
plt.legend([‘Open’,’Denoised: 0.001'])
plt.show()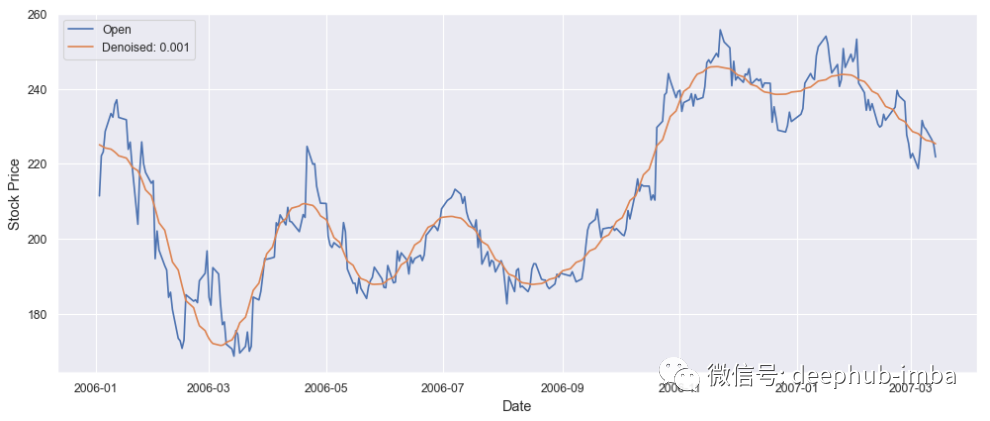
Detección de valores atípicos en series temporales
Los valores atípicos en una serie temporal son picos o caídas repentinos en una línea de tendencia. Puede haber una variedad de factores que causan valores atípicos. Echemos un vistazo a los métodos disponibles para detectar valores atípicos:
Métodos basados en estadísticas móviles
Este método es el más intuitivo y funciona para casi todos los tipos de series temporales. En este enfoque, los límites superior e inferior se crean a partir de medidas estadísticas específicas, como la media y la desviación estándar, las puntuaciones Z y T y los percentiles de la distribución. Por ejemplo, podemos definir los límites superior e inferior como:

No es recomendable tomar la media y la desviación estándar de toda la serie, porque en este caso los límites serán estáticos. Los límites deben crearse sobre la base de una ventana móvil, al igual que considerar un conjunto de observaciones consecutivas para crear un límite y luego transferirlo a otra ventana. Este método es un método de detección de valores atípicos eficiente y simple.
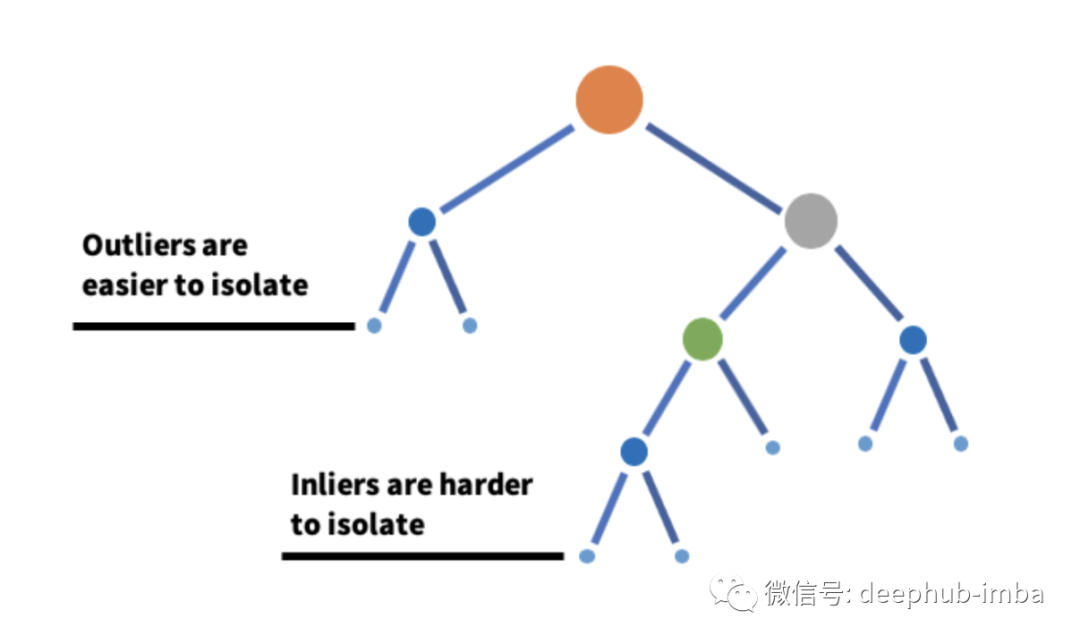
Bosque aislado
Como sugiere el nombre, Isolation Forest es un algoritmo de aprendizaje automático basado en árboles de decisión para la detección de anomalías. Funciona aislando puntos de datos en un conjunto determinado de características utilizando particiones de árboles de decisión. En otras palabras, toma una muestra del conjunto de datos y construye un árbol sobre esa muestra hasta que se aísla cada punto. Para aislar puntos de datos, divida aleatoriamente eligiendo una división entre los valores máximo y mínimo para esa característica hasta que se aísle cada punto. La partición aleatoria de características creará rutas más cortas en el árbol para puntos de datos anormales, distinguiéndolos del resto de los datos.
Agrupamiento de K-medias
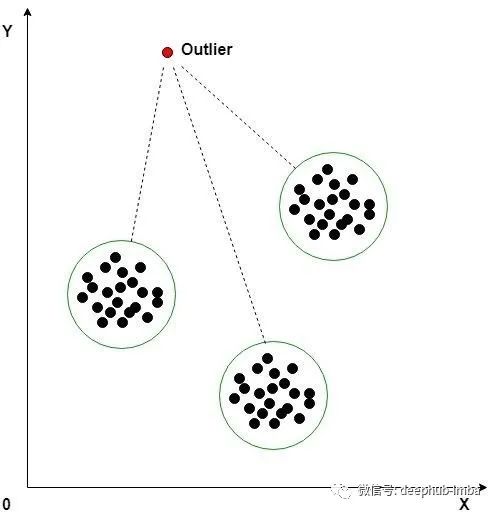
La agrupación en clústeres de K-means es un algoritmo de aprendizaje automático no supervisado que a menudo se usa para detectar valores atípicos en datos de series temporales. El algoritmo analiza los puntos de datos en el conjunto de datos y agrupa puntos de datos similares en K clústeres. Las anomalías se distinguen midiendo la distancia de un punto de datos a su centroide más cercano. Si la distancia es mayor que cierto umbral, el punto de datos se marca como anómalo. El algoritmo K-Means utiliza la distancia euclidiana para la comparación.
posibles preguntas de la entrevista
Si una persona escribe un proyecto sobre series temporales en su currículum, el entrevistador puede hacer estas posibles preguntas a partir de este tema:
¿Cuáles son los métodos para preprocesar datos de series temporales y en qué se diferencian de los métodos de imputación estándar?
¿Qué significa ventana de serie temporal?
¿Has oído hablar del Bosque Solitario? En caso afirmativo, ¿puede explicar cómo funciona?
¿Qué es la transformada de Fourier y por qué la necesitamos?
¿Cuáles son las diferentes formas de completar los valores faltantes en los datos de series temporales?
Resumir
En este artículo, examinamos algunas técnicas comunes de preprocesamiento de datos de series temporales. Comenzamos con observaciones ordenadas de series de tiempo; luego examinamos varias técnicas de imputación de valores perdidos. Debido a que estamos tratando con un conjunto ordenado de observaciones, la imputación de series de tiempo difiere de las técnicas de imputación tradicionales. Además, se aplican algunas técnicas de eliminación de ruido al conjunto de datos de precios de acciones de Google y, finalmente, se analizan algunos métodos de detección de valores atípicos de series temporales. El uso de todos estos pasos de preprocesamiento mencionados garantiza datos de alta calidad, listos para construir modelos complejos.
: Shashank Gupta
Lectura recomendada:
Mi intercambio de reclutamiento escolar por Internet de 2022
Hablando de la diferencia entre la publicación de algoritmos y la publicación de desarrollo
Resumen de salarios de investigación y desarrollo de reclutamiento de escuelas de Internet
Para series de tiempo, todo lo que puedes hacer.
Número público: coche caracol AI
Mantente humilde, mantente disciplinado, mantente progresista

Envíe [Snail] para obtener una copia del "Proyecto práctico de IA" (AI Snail Car)
Envíe [1222] para obtener una buena nota de cepillado de leetcode
Envíe [AI Four Classics] para obtener cuatro libros electrónicos clásicos de AI