La tabla de memoria es una parte importante de la base de datos DolphinDB. La tabla de memoria no solo se puede usar directamente para almacenar datos, realizar lectura y escritura de datos a alta velocidad, sino que también puede almacenar en caché los resultados intermedios del motor de cálculo para acelerar el proceso de cálculo. Este tutorial presenta principalmente los escenarios de clasificación y uso de las tablas de memoria de DolphinDB, y las similitudes y diferencias en las operaciones de datos y las operaciones de estructura de tabla (esquema) de varias tablas de memoria.
1. Categoría de la tabla de memoria
Según los diferentes escenarios de uso y características funcionales, las tablas de memoria de DolphinDB se pueden dividir en los siguientes cuatro tipos:
- Mesa de memoria convencional
- Tabla de memoria de valores-clave
- Tabla de datos de flujo
- Tabla de memoria MVCC
1.1 Tabla de memoria convencional
La tabla de memoria convencional es la estructura de tabla más básica en DolphinDB y admite operaciones como adición, eliminación, modificación y consulta. Los resultados devueltos por las consultas SQL generalmente se almacenan en tablas de memoria convencionales, esperando su procesamiento posterior.
- crear
Utilice la función de tabla para crear una tabla de memoria convencional. La función de tabla tiene dos usos: el primer uso se basa en el esquema especificado (tipo de campo y nombre de campo) y la capacidad de la tabla (capacidad) y el número inicial de filas (tamaño) para generar; el segundo uso es a través de los datos existentes ( matriz, tabla, matriz y tupla) para generar una tabla.
La ventaja de utilizar el primer método es que la memoria se puede asignar a la mesa por adelantado. Cuando el número de registros en la tabla excede la capacidad, el sistema expandirá automáticamente la capacidad de la tabla. Al expandirse, el sistema primero asignará un espacio de memoria más grande (aumentará del 20% al 100%), luego copiará la tabla anterior a la nueva tabla y finalmente liberará la memoria original. Para tablas más grandes, el costo de expansión será mayor. Por lo tanto, si podemos predecir el número de filas en la tabla de antemano, se recomienda asignar una capacidad razonable por adelantado al crear la tabla de memoria. Si el número inicial de filas en la tabla es 0, el sistema generará una tabla vacía. Si el número inicial de filas no es 0, el sistema generará una tabla con el número especificado de filas y el valor de cada columna de la tabla es el valor predeterminado. P.ej:
//创建一个空的常规内存表
t=table(100:0,`sym`id`val,[SYMBOL,INT,INT])
//创建一个10行的常规内存表
t=table(100:10,`sym`id`val,[SYMBOL,INT,INT])
select * from t
sym id val
--- -- ---
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0 La función de tabla también permite crear una tabla de memoria convencional a partir de datos existentes. El siguiente ejemplo lo crean varias matrices.
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=table(sym,id,val)- solicitud
La tabla de memoria convencional es una de las estructuras de datos más utilizadas en DolphinDB, solo superada por las matrices. Los resultados de las consultas de las sentencias SQL y los resultados intermedios de las consultas distribuidas se almacenan en tablas de memoria convencionales. Cuando la memoria del sistema es insuficiente, la tabla no desbordará automáticamente los datos en el disco, pero la falta de memoria es anormal. Por tanto, cuando realizamos diversas consultas y cálculos, debemos prestar atención al tamaño de los resultados intermedios y los resultados finales. Cuando ya no se necesiten algunos resultados intermedios, publíquelos a tiempo. Con respecto a los diversos usos de agregar, eliminar, modificar y verificar tablas de memoria convencionales, puede consultar otro tutorial sobre cómo cargar y operar tablas de particiones de memoria .
1.2 Tabla de memoria de valores clave
La tabla de memoria de clave-valor es una tabla de memoria en DolphinDB que admite claves primarias. Al especificar uno o más campos de la tabla como clave principal, los registros de la tabla se pueden determinar de forma única. La tabla de memoria de clave-valor admite operaciones como adición, supresión, modificación y consulta, pero no se permite actualizar el valor de clave principal. La tabla de memoria de clave-valor registra el número de fila correspondiente a cada valor clave a través de una tabla hash, por lo que tiene una eficiencia muy alta para la búsqueda y actualización basada en clave-valor.
- crear
Utilice la función keyedTable para crear una tabla de memoria de valores clave. Esta función es muy similar a la función de tabla, la única diferencia es que se agrega un parámetro para indicar el nombre de la columna clave.
//创建空的键值内存表,主键由sym和id字段组成
t=keyedTable(`sym`id,1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建键值内存表,主键由sym和id字段组成
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=keyedTable(`sym`id,sym,id,val)Nota: Al crear una tabla de memoria de valores-clave especificando la capacidad y el tamaño inicial, el tamaño inicial debe ser 0.
También podemos usar la función keyedTable para convertir tablas de memoria convencionales en tablas de memoria de valores clave. P.ej:
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=keyedTable(`sym`id, tmp)- Características de inserción y actualización de datos
Al agregar un nuevo registro a la tabla de memoria de valores clave, el sistema verificará automáticamente el valor de la clave principal del nuevo registro. Si el valor de la clave principal del nuevo registro no existe en la tabla, agregue un nuevo registro a la tabla; si el valor de la clave principal del nuevo registro duplica el valor de la clave principal del registro existente, el valor de la clave principal correspondiente en se actualizará el registro de la tabla. Consulte el ejemplo siguiente.
Primero, inserte un nuevo registro en la tabla de memoria de clave-valor vacía. Los valores de clave principal en el nuevo registro son AAPL, IBM y GOOG.
t=keyedTable(`sym,1:0,`sym`datetime`price`qty,[SYMBOL,DATETIME,DOUBLE,DOUBLE]);
insert into t values(`APPL`IBM`GOOG,2018.06.08T12:30:00 2018.06.08T12:30:00 2018.06.08T12:30:00,50.3 45.6 58.0,5200 4800 7800);
t;
sym datetime price qty
---- ------------------- ----- ----
APPL 2018.06.08T12:30:00 50.3 5200
IBM 2018.06.08T12:30:00 45.6 4800
GOOG 2018.06.08T12:30:00 58 7800Inserte un lote de registros nuevos con valores de clave primaria de AAPL, IBM y GOOG en la tabla nuevamente.
insert into t values(`APPL`IBM`GOOG,2018.06.08T12:30:01 2018.06.08T12:30:01 2018.06.08T12:30:01,65.8 45.2 78.6,5800 8700 4600);
t;
sym datetime price qty
---- ------------------- ----- ----
APPL 2018.06.08T12:30:01 65.8 5800
IBM 2018.06.08T12:30:01 45.2 8700
GOOG 2018.06.08T12:30:01 78.6 4600Como puede ver, el número de registros de la tabla no ha aumentado, pero se han actualizado los registros correspondientes a la clave primaria.
Continúe insertando un lote de nuevos registros en la tabla, el nuevo registro en sí contiene el valor de clave primaria duplicado MSFT.
Como puede ver, solo hay un registro cuyo valor de clave principal es MSFT en la tabla.
- Escenario de aplicación
(1) La tabla clave-valor tiene una eficiencia muy alta para la actualización y consulta de una sola fila, y es una opción ideal para el almacenamiento en caché de datos. En comparación con redis, la tabla de memoria de clave-valor en DolphinDB es compatible con todas las operaciones de SQL y puede completar cálculos más complejos además de las actualizaciones y consultas de clave-valor.
(2) Como tabla de salida del motor de agregación de series de tiempo, los resultados de la tabla de salida se actualizan en tiempo real. Para obtener más información, consulte el tutorial Uso de DolphinDB para calcular K-line .
1.3 Tabla de datos de flujo
La tabla de datos de transmisión, como su nombre lo indica, es una tabla de memoria diseñada para la transmisión de datos y un medio para la publicación y suscripción de datos de transmisión. La tabla de datos de flujo tiene una dualidad de tabla de flujo natural. Publicar un mensaje es equivalente a insertar un registro en la tabla de datos de flujo, y suscribirse a un mensaje es equivalente a enviar los datos recién llegados en la tabla de datos de flujo a la aplicación cliente. La consulta y el cálculo de la transmisión de datos se pueden realizar a través de declaraciones SQL.
- crear
Utilice la función streamTable para crear una tabla de datos de flujo. El uso de streamTable es exactamente el mismo que el de la función de tabla.
//创建空的流数据表
t=streamTable(1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建流数据表
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=streamTable(sym,id,val)También podemos usar la función streamTable para convertir una tabla de memoria convencional en una tabla de datos de flujo. P.ej:
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=streamTable(tmp)La tabla de datos de flujo también admite la creación de una única columna de valor clave, que puede crearse mediante la función keyedStreamTable. Pero a diferencia del propósito de diseño de la tabla con clave, el propósito de la tabla de flujo de clave es evitar mensajes duplicados en escenarios de alta disponibilidad (varios editores escriben al mismo tiempo). Por lo general, la clave es el ID del mensaje.
- Características de la operación de datos
Debido a que los datos del flujo tienen la característica de que no cambiarán una vez que se generen, la tabla de datos del flujo no admite la actualización ni la eliminación de registros, sino que solo admite la consulta y la adición de registros. La transmisión de datos suele ser continua, pero la memoria es limitada. Para resolver esta contradicción, la tabla de datos de transmisión introduce un mecanismo de persistencia para mantener la última parte de los datos en la memoria, y los datos más antiguos se conservan en el disco. Cuando el usuario se suscribe a los datos antiguos, se leen directamente del disco. Para habilitar la persistencia, use la función enableTableShareAndPersistence, consulte el tutorial de transmisión de datos para obtener más detalles .
- Escenario de aplicación
La tabla de datos de transmisión compartida publica datos en la informática de transmisión. El suscriptor usa la función subscribeTable para suscribirse y consumir datos de transmisión.
1.4 tabla de memoria MVCC
La tabla de memoria MVCC almacena múltiples versiones de datos Cuando varios usuarios leen y escriben la tabla de memoria MVCC al mismo tiempo, no se bloquean entre sí. El aislamiento de datos de la tabla de memoria MVCC adopta el modelo de aislamiento de instantáneas. Lo que el usuario lee son los datos que ya existen antes de leerlos. Incluso si los datos se modifican o eliminan durante el proceso de lectura, también afectarán al usuario que está leyendo antes. Sin efecto. Este enfoque de múltiples versiones puede admitir el acceso de usuarios simultáneos a las tablas de memoria. Cabe señalar que la implementación actual de la tabla de memoria MVCC es relativamente simple, toda la tabla está bloqueada al actualizar y eliminar datos, y la tecnología de copia en escritura se utiliza para copiar una copia de los datos, por lo que la eficiencia de las operaciones de eliminación y actualización de datos no son elevadas. En versiones posteriores, implementaremos tablas de memoria MVCC a nivel de fila.
- crear
Utilice la función mvccTable para crear la tabla de memoria MVCC. P.ej:
//创建空的流数据表
t=mvccTable(1:0,`sym`id`val,[SYMBOL,INT,INT])
//使用向量创建流数据表
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
t=mvccTable(sym,id,val)Podemos conservar los datos de la tabla de memoria MVCC en el disco, solo especifique el directorio persistente y el nombre de la tabla al crearlo. P.ej,
t=mvccTable(1:0,`sym`id`val,[SYMBOL,INT,INT],"/home/user1/DolphinDB/mvcc","test")Una vez que el sistema se reinicia, podemos cargar los datos del disco en la memoria a través de la función loadMvccTable.
loadMvccTable("/home/user1/DolphinDB/mvcc","test")También podemos usar la función mvccTable para convertir tablas de memoria convencionales en tablas de memoria MVCC.
sym=`A`B`C`D`E
id=5 4 3 2 1
val=52 64 25 48 71
tmp=table(sym, id, val)
t=mvccTable(tmp)- Escenario de aplicación
La tabla de memoria MVCC actual es adecuada para escenarios donde hay más lecturas y menos escrituras, y se requiere persistencia. Por ejemplo, un sistema de configuración dinámica requiere elementos de configuración persistentes y los elementos de configuración no se cambian con frecuencia.Se han agregado recientemente y se han buscado principalmente, lo cual es muy adecuado para tablas MVCC.
2. Tabla de memoria compartida
La tabla de memoria en DolphinDB solo se usa en la sesión que creó la tabla de memoria por defecto. No admite operaciones concurrentes de múltiples usuarios y múltiples sesiones, y por supuesto no es visible para otras sesiones. Si desea crear una tabla de memoria que pueda ser utilizada por otros usuarios para garantizar la seguridad de las operaciones simultáneas de múltiples usuarios, debe compartir la tabla de memoria. Se pueden compartir los 4 tipos de tablas de memoria. En DolphinDB, usamos el comando compartir para compartir tablas de memoria.
t=table(1..10 as id,rand(100,10) as val)
share t as st
//或者share(t,`st)El código anterior comparte la tabla t con la tabla st.
Utilice la función undef para eliminar la tabla compartida.
undef(`st,SHARED)2.1 Asegúrese de que sea visible para todas las sesiones
La tabla de memoria solo es visible en la sesión actual, no en otras sesiones. Después de compartir, otras sesiones pueden acceder a la tabla de memoria accediendo a variables compartidas. Por ejemplo, compartimos la tabla t como tabla st en la sesión actual.
t=table(1..10 as id,rand(100,10) as val)
share t as stPodemos acceder a la variable st en otras sesiones. Por ejemplo, inserte un dato en la tabla compartida st.
insert into st values(11,200)
select * from st
id val
-- ---
1 1
2 53
3 13
4 40
5 61
6 92
7 36
8 33
9 46
10 26
11 200Al cambiar a la sesión original, podemos encontrar que también se ha agregado un registro a la tabla t.
select * from t
id val
-- ---
1 1
2 53
3 13
4 40
5 61
6 92
7 36
8 33
9 46
10 26
11 200
2.2 Garantizar la seguridad de los hilos
En el caso de multiproceso, los datos de la tabla de memoria se destruyen fácilmente. Compartir proporciona un mecanismo de protección para garantizar la seguridad de los datos, pero también afecta el rendimiento del sistema.
Las tablas de memoria convencionales, las tablas de datos de flujo y las tablas de memoria MVCC admiten modelos de múltiples versiones, lo que permite múltiples lecturas y una escritura. Específicamente, la lectura y la escritura no se bloquean entre sí, puede leer al escribir y puede escribir al leer. No hay bloqueo al leer datos, se permite que varios subprocesos lean datos al mismo tiempo y se usa el aislamiento de instantáneas al leer datos. Se debe agregar un candado al escribir datos y solo se permite un subproceso para modificar la tabla de memoria. Las operaciones de escritura incluyen agregar, eliminar o actualizar. Los registros de adición siempre se añaden al final de la tabla de memoria, tanto el uso de la memoria como el uso de la CPU son muy eficientes. Las tablas de memoria convencionales y las tablas de memoria MVCC admiten actualizaciones y eliminaciones, y utilizan tecnología de copia en escritura, lo que significa que primero se copia una copia de los datos (para formar una nueva versión) y luego se elimina y modifica en la nueva versión. Se puede ver que tanto el consumo de memoria como de CPU de las operaciones de eliminación y actualización son relativamente altos. Cuando las operaciones de eliminación y actualización son frecuentes, y las operaciones de lectura requieren mucho tiempo (la versión anterior no se puede publicar rápidamente), es fácil provocar excepciones OOM.
La tabla de memoria de clave-valor necesita mantener un índice interno al escribir, y necesita obtener datos basados en el índice al leer. Por lo tanto, el uso compartido de la tabla de memoria de valores clave adopta diferentes métodos, y tanto la lectura como la escritura deben estar bloqueadas. El hilo de escritura y el hilo del lector, varios hilos de escritura, varios hilos del lector son mutuamente excluyentes. Intente evitar consultas o cálculos que consuman mucho tiempo para las tablas de memoria de valores clave; de lo contrario, otros subprocesos estarán esperando durante mucho tiempo.
3. Tabla de memoria de particiones
Cuando la cantidad de datos en la tabla de memoria es grande, podemos particionar la tabla de memoria. Después de la partición, una tabla grande consta de varias subtablas (tabletas). La tabla grande no utiliza bloqueos globales. Los bloqueos se gestionan de forma independiente por cada subtabla, lo que puede aumentar considerablemente la concurrencia de lectura y escritura. DolphinDB admite la partición de valores, la partición de rango, la partición hash y la partición de listas para tablas de memoria. No admite la partición combinada. En DolphinDB, usamos la función createPartitionedTable para crear una tabla de particiones de memoria.
- Crear tabla de memoria convencional de partición
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,0 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)- Crear tabla de memoria de clave de partición
kt=keyedTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,0 101 201 301)
pkt=db.createPartitionedTable(t,`pkt,`id)- Crear una tabla de datos de flujo particionada
Al crear una tabla de datos de flujo particionada, debe pasar varias tablas de datos de flujo como plantillas, y cada tabla de datos de flujo corresponde a una partición. Al escribir datos, escriba directamente en estas tablas de flujo; al consultar datos, debe consultar la tabla de particiones.
st1=streamTable(1:0,`id`val,[INT,INT])
st2=streamTable(1:0,`id`val,[INT,INT])
st3=streamTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301) pst=db.createPartitionedTable([st1,st2,st3],`pst,`id)
st1.append!(table(1..100 as id,rand(100,100) as val))
st2.append!(table(101..200 as id,rand(100,100) as val))
st3.append!(table(201..300 as id,rand(100,100) as val))
select * from pst- Crear tabla de memoria de partición MVCC
Al igual que al crear una tabla de datos de flujo particionado, para crear una tabla de memoria MVCC particionada, debe pasar varias tablas de memoria MVCC como plantillas. Cada tabla corresponde a una partición. Al escribir datos, escriba directamente en estas tablas; al consultar datos, debe consultar la tabla de particiones.
mt1=mvccTable(1:0,`id`val,[INT,INT])
mt2=mvccTable(1:0,`id`val,[INT,INT])
mt3=mvccTable(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pmt=db.createPartitionedTable([mt1,mt2,mt3],`pst,`id)
mt1.append!(table(1..100 as id,rand(100,100) as val))
mt2.append!(table(101..200 as id,rand(100,100) as val))
mt3.append!(table(201..300 as id,rand(100,100) as val))
select * from pmtDado que la tabla de memoria de partición no usa bloqueos globales, las subtablas no se pueden agregar ni eliminar dinámicamente después de la creación.
3.1 Incrementar la concurrencia de consultas
Hay tres significados para aumentar la simultaneidad de la consulta por tabla de partición: (1) La tabla de clave-valor también debe bloquearse al realizar la consulta. La tabla de partición es administrada de forma independiente por la tabla secundaria, lo que equivale a reducir la granularidad de la bloquear, por lo que puede aumentar la concurrencia de lectura.; (2) La tabla de partición puede procesar cada subtabla en paralelo durante el cálculo por lotes; (3) Si el campo de partición se especifica en el filtro de la consulta SQL, el rango de partición se puede reducir para evitar el escaneo completo de la tabla.
Tomando la tabla de memoria de valores-clave como ejemplo, comparamos el rendimiento de consultas simultáneas con y sin particiones. Primero, cree un conjunto de datos de simulación, que contiene un total de 5 millones de filas de datos.
n=5000000
id=shuffle(1..n)
qty=rand(1000,n)
price=rand(1000.0,n)
kt=keyedTable(`id,id,qty,price)
share kt as skt
id_range=cutPoints(1..n,20)
db=database("",RANGE,id_range)
pkt=db.createPartitionedTable(kt,`pkt,`id).append!(kt)
share pkt as spktSimulamos 10 clientes en otro servidor para consultar simultáneamente la tabla de memoria de valores clave. Cada cliente consulta 100.000 veces, y cada vez que se consulta un dato, se calcula el tiempo total consumido por cada consulta de cliente 100.000 veces.
def queryKeyedTable(tableName,id){
for(i in id){
select * from objByName(tableName) where id=i
}
}
conn=xdb("192.168.1.135",18102,"admin","123456")
n=5000000
jobid1=array(STRING,0)
for(i in 1..10){
rid=rand(1..n,100000)
s=conn(submitJob,"evalQueryUnPartitionTimer"+string(i),"",evalTimer,queryKeyedTable{`skt,rid})
jobid1.append!(s)
}
time1=array(DOUBLE,0)
for(j in jobid1){
time1.append!(conn(getJobReturn,j,true))
}
jobid2=array(STRING,0)
for(i in 1..10){
rid=rand(1..n,100000)
s=conn(submitJob,"evalQueryPartitionTimer"+string(i),"",evalTimer,queryKeyedTable{`spkt,rid})
jobid2.append!(s)
}
time2=array(DOUBLE,0)
for(j in jobid2){
time2.append!(conn(getJobReturn,j,true))
}time1 es el tiempo que tardan 10 clientes en consultar la tabla de memoria de claves no particionadas, y time2 es el tiempo que tardan 10 clientes en consultar la tabla de memoria de claves particionadas, en milisegundos.
time1
[6719.266848,7160.349678,7271.465094,7346.452625,7371.821485,7363.87979,7357.024299,7332.747157,7298.920972,7255.876976]
time2
[2382.154581,2456.586709,2560.380315,2577.602019,2599.724927,2611.944367,2590.131679,2587.706832,2564.305815,2498.027042]Se puede ver que el tiempo que consume cada cliente para consultar la tabla de memoria de valores de clave particionada es menor que el de consultar la tabla de memoria no particionada.
Consulte tablas de memoria sin particiones para garantizar el aislamiento de instantáneas. Pero consultar una tabla de memoria de partición ya no garantiza el aislamiento de instantáneas. Como se mencionó anteriormente, la lectura y escritura de la tabla de memoria particionada no usa un bloqueo global. Cuando un hilo está consultando, otro hilo puede estar escribiendo e involucrando múltiples subtablas, por lo que parte de los datos escritos pueden leerse.
3.2 Aumentar la concurrencia de escritura
Tomando la tabla de memoria convencional particionada como ejemplo, podemos escribir datos en diferentes particiones al mismo tiempo.
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)
def writeData(mutable t,id,batchSize,n){
for(i in 1..n){
idv=take(id,batchSize)
valv=rand(100,batchSize)
tmp=table(idv,valv)
t.append!(tmp)
}
}
job1=submitJob("write1","",writeData,pt,1..100,1000,1000)
job2=submitJob("write2","",writeData,pt,101..200,1000,1000)
job3=submitJob("write3","",writeData,pt,201..300,1000,1000)En el código anterior, hay 3 hilos que escriben simultáneamente en 3 particiones diferentes de pt. Cabe señalar que debemos evitar escribir en la misma partición al mismo tiempo. Por ejemplo, el siguiente código puede hacer que el sistema falle.
job1=submitJob("write1","",writeData,pt,1..300,1000,1000)
job2=submitJob("write2","",writeData,pt,1..300,1000,1000)El código anterior define dos hilos de escritura y escribe en la misma partición, lo que destruirá la memoria. Para garantizar la seguridad y la coherencia de los datos en cada partición, podemos compartir la tabla de memoria de la partición. De esta manera, se pueden definir varios subprocesos para dividirse en la misma partición al mismo tiempo.
share pt as spt
job1=submitJob("write1","",writeData,spt,1..300,1000,1000)
job2=submitJob("write2","",writeData,spt,1..300,1000,1000)
4. Comparación de operaciones de datos
4.1 Agregar, eliminar, modificar
La siguiente tabla resume las operaciones de adición, eliminación, modificación y verificación admitidas por los 4 tipos de tablas de memoria en el caso de compartidas / particionadas.
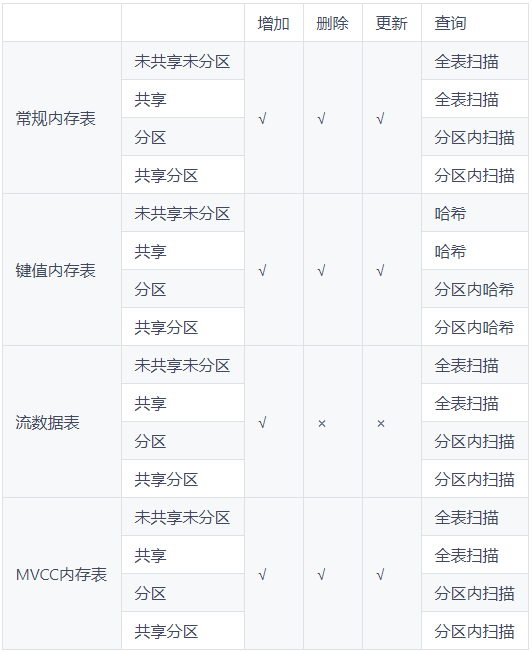
Descripción:
- Las tablas de memoria convencionales, las tablas de memoria de valores clave y las tablas de memoria MVCC admiten operaciones de adición, eliminación, modificación y consulta. Las tablas de datos de transmisión solo admiten operaciones de adición y consulta, pero no de eliminación y actualización.
- Para las tablas de memoria de clave-valor, si la clave principal se incluye en la condición del filtro de consulta, el rendimiento de la consulta mejorará significativamente.
- Para las tablas de memoria particionada, si las condiciones del filtro de consulta incluyen columnas de partición, el sistema puede reducir el rango de particiones que se analizarán, mejorando así el rendimiento de la consulta.
4.2 Simultaneidad
Sin escribir, todas las tablas de memoria permiten que varios subprocesos consulten al mismo tiempo. En el caso de la escritura, la concurrencia de las cuatro tablas de memoria es diferente. La siguiente tabla resume las condiciones de lectura y escritura simultáneas admitidas por los 4 tipos de tablas de memoria en el caso compartido / particionado.
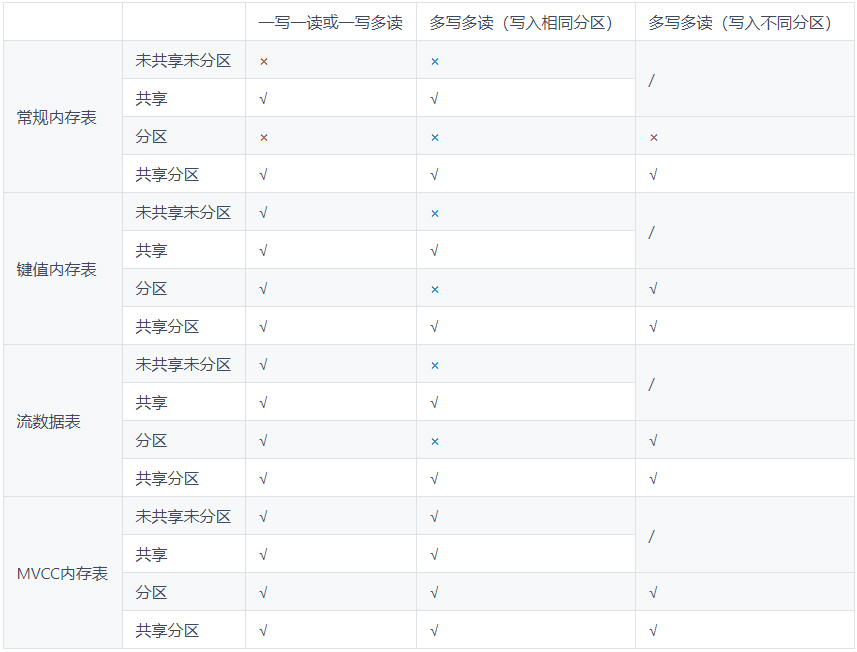
Descripción:
- La tabla compartida permite lecturas y escrituras simultáneas.
- Para las tablas de particiones que no se comparten, no se permite que varios subprocesos escriban en la misma partición al mismo tiempo.
4.3 Resistencia
- Las tablas de memoria convencionales y las tablas de memoria de valores clave no admiten la persistencia de datos. Una vez que el nodo se reinicia, se perderán todos los datos de la memoria.
- Solo las tablas de datos de transmisión vacías admiten la persistencia de datos. Para conservar la tabla de datos de flujo, primero configure el directorio persistenceDir para los datos de flujo y luego use enableTableShareAndPersistence para compartir la tabla de datos de flujo y conservarla en el disco. Por ejemplo, la tabla de datos de transmisión t se comparte y se conserva en el disco.
t=streamTable(1:0,`id`val,[INT,INT])
enableTableShareAndPersistence(t,`st)Una vez habilitada la persistencia de la tabla de datos de flujo, algunos de los registros más recientes de la tabla de datos de flujo se mantendrán en la memoria. De forma predeterminada, la memoria conservará los últimos 100.000 registros. También podemos ajustar este valor según sea necesario.
La persistencia de la tabla de datos de flujo se puede configurar para adoptar métodos asincrónicos / síncronos, comprimidos / no comprimidos. Normalmente, el modo asíncrono puede lograr un mayor rendimiento.
Una vez que el sistema se reinicia, ejecute la función enableTableShareAndPersistence nuevamente para cargar todos los datos del disco en la memoria.
- La tabla de memoria MVCC admite la persistencia. Al crear la tabla de memoria MVCC, podemos especificar la ruta de persistencia. Por ejemplo, cree una tabla de memoria MVCC persistente.
t=mvccTable(1:0,`id`val,[INT,INT],"/home/user/DolphinDB/mvccTable")
t.append!(table(1..10 as id,rand(100,10) as val))Una vez que el sistema se reinicia, podemos usar la función loadMvccTable para cargar los datos del disco en la memoria. P.ej:
t=loadMvccTable("/home/user/DolphinDB/mvccTable","t")5. Comparación de operaciones de estructura de tabla
Las operaciones de estructura de la tabla de memoria incluyen agregar columnas, eliminar columnas, modificar columnas (contenido y tipo de datos) y ajustar el orden de las columnas. La siguiente tabla resume las operaciones de estructura soportadas por los 4 tipos de tablas de memoria en el caso de compartidas / particionadas.
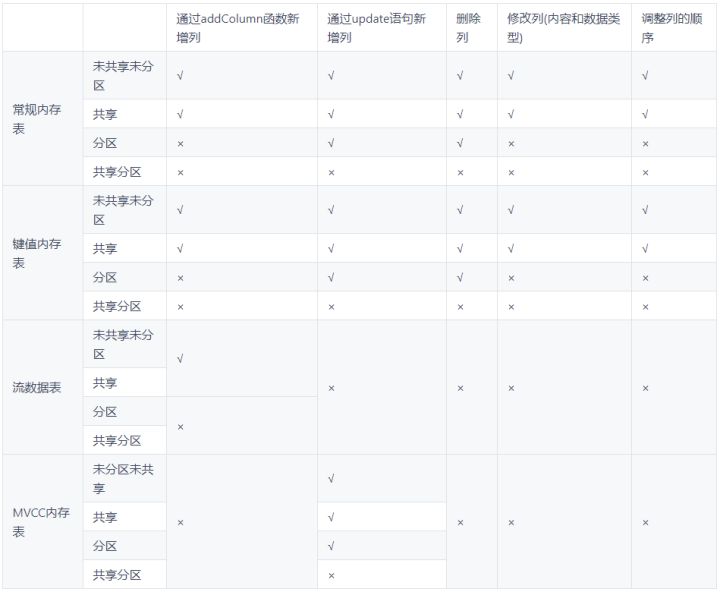
Descripción:
- Las tablas de particiones y las tablas de memoria MVCC no pueden agregar columnas a través de la función addColumn.
- La tabla de particiones puede agregar columnas a través de la declaración de actualización, pero la tabla de datos de la secuencia no puede modificarse, por lo que la tabla de datos de la secuencia no puede agregar columnas a través de la declaración de actualización.
6. Resumen
DolphinDB admite 4 tipos de tablas de memoria y también introduce el concepto de compartir y particionar, que básicamente puede satisfacer las diversas necesidades de la computación de memoria y la computación de flujo.