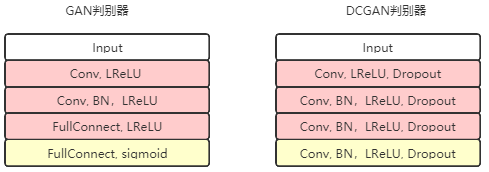
En el modelo GAN original, tanto el generador como el discriminador son modelos poco profundos. Para generar imágenes de mayor resolución , necesitamos modelos más profundos. Alec Radford et al. De Indico propusieron un modelo DCGAN (GAN convolucional profundo) en 2016. Tanto el discriminador como el generador de este modelo utilizan una red neuronal completamente convolucional. A excepción de la última capa del discriminador y la primera capa del generador, todas las demás capas utilizan capas convolucionales. Este modelo mejora la capacidad de GAN para generar imágenes a gran escala. Después de entrenar en el conjunto de datos LSUN (Comprensión de escena de gran venta), puede generar
una imagen realista con un tamaño de 64 × 64 , que supera a otros modelos GAN anteriores.
def discriminator(self, image, reuse=False):
if reuse:
tf.get_variable_scope().reuse_variables()
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')
return tf.nn.sigmoid(h4), h4

def generator(self, z):
self.z_, self.h0_w, self.h0_b = linear(z,self.gf_dim*8*4*4,'g_h0_lin', with_w=True)
self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = conv2d_transpose(h1,[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = conv2d_transpose(h2,[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = conv2d_transpose(h3,[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)
return tf.nn.tanh(h4)

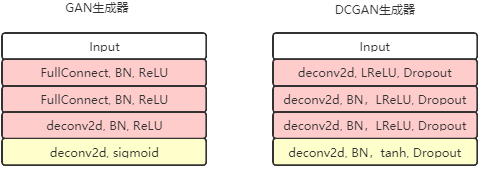
Como puede verse en la figura anterior, el generador G expande un vector de ruido de 100 dimensiones en una salida de matriz de 64 * 64 * 3, y todo el proceso adopta el método de convoluciones de pasos fraccionarios.
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.zeros_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.ones_like(self.D_)))
En comparación con la mejora de GAN
(1) use convolución y desconvolución para reemplazar la capa de agrupación
(2) agregue operaciones de normalización por lotes tanto al generador como al discriminador
(3) elimine la capa de GAN completamente conectada, use La capa de agrupación global reemplaza
(4) La capa de salida del generador usa la función de activación Tanh, y otras capas usan RELU
(5) Todas las capas del discriminador usan la función de activación LeakyReLU
http://bamos.github.io/2016/08/09/deep-completion/