1. Introducción a los conjuntos de datos.
El conjunto de datos CIFAR-10 consta de 60.000 imágenes en color de 32x32 en 10 categorías , 6000con 1 imagen en cada categoría. Hay 50000imágenes de entrenamiento e 10000imágenes de prueba.
El conjunto de datos se divide en 5 lotes de entrenamiento y 1 lote de prueba, cada lote tiene 10,000 imágenes. El lote de prueba contiene exactamente 1000 imágenes seleccionadas al azar de cada clase. Los lotes de entrenamiento contienen las imágenes restantes en orden aleatorio, pero algunos lotes de entrenamiento pueden contener más imágenes de una clase que de otra. Entre ellos, el lote de entrenamiento contiene exactamente 5000 imágenes de cada clase.
Resumir:
Size(大小):Imagen RGB de 32 × 32, el conjunto de datos en sí es el canal BGR,
Num(数量):el conjunto de entrenamiento 50000 y el conjunto de prueba 10000, un total de 60000 imágenes
Classes(十种类别):de avión (avión), automóvil (automóvil), pájaro (pájaro), gato (gato), ciervo (ciervo) ), perro (perro), rana (rana), caballo (caballo), barco (barco), camión (camión)

Enlace de descarga
Dream是个帅哥Compartiendo desde blogger ( ):
Enlace: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ Código de extracción: 0213
Carpeta de conjunto de datos
Conjunto de datos CIFAR-100 (ampliado)
Este conjunto de datos es similar a CIFAR-10 excepto que tiene 100 clases y cada clase contiene 600 imágenes. Hay 500 imágenes de entrenamiento y 100 imágenes de prueba para cada clase. Las 100 subcategorías de CIFAR-100 se dividen en 20 categorías amplias. Cada imagen tiene una etiqueta "fina" (la subcategoría a la que pertenece) y una etiqueta "gruesa" (la categoría principal a la que pertenece).
Comparación entre el conjunto de datos CIFAR-10 y el conjunto de datos MNIST
- Las dimensiones son diferentes: el conjunto de datos CIFAR-10 tiene 4 dimensiones y el conjunto de datos MNIST tiene 3 dimensiones (las cuatro dimensiones de CIRAR-10: el número de muestras a la vez, la altura de la imagen, el ancho de la imagen, el número de canales de imagen -> NHWC; las tres dimensiones de MNIST: una vez, número de muestras, altura de la imagen, ancho de la imagen -> NHW)
- Los tipos de imágenes son diferentes: el conjunto de datos CIFAR-10 es una imagen RGB (con tres canales) y el conjunto de datos MNIST es una imagen en escala de grises, razón por la cual el conjunto de datos CIFAR-10 tiene una dimensión más que el conjunto de datos MNIST. .
- El contenido de las imágenes es diferente: el conjunto de datos CIFAR-10 muestra una variedad de objetos diferentes (gatos, perros, aviones, automóviles...), y el conjunto de datos MNIST muestra números escritos a mano del 0 al 9 por diferentes personas.
2. Lectura del conjunto de datos
Leer el conjunto de datos
Seleccione data_batch_1 para visualizar una de las imágenes:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
Resultados de salida:
hay 4 claves de diccionario en un lote de conjuntos de datos. Lo que debemos usar es la etiqueta de datos y el contenido de los datos (10000 × 32 × 32 × 3, 10000 32 × 32 imágenes de tres canales RGB)

la salida es un diccionario :
{ b'batch_label': b'lote de entrenamiento 1 de 5', b'labels': [6, 9… 1,5], b'data': array([[ 59, 43,…, 84, 72], …[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8), b'filenames': [b'leptodactylus_pentadactylus_s_000004.png',…b'cur_s_000170.png'] }
Entre ellos, el significado de cada representante es el siguiente:
b'batch_label': el conjunto de archivos al que pertenece
b'labels': etiqueta de imagen
b'data' : datos de imagen
b'filename' : nombre de imagen
Tipo de lectura
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
Resultado de salida:
<clase 'bytes'>
<clase 'lista'>
<clase 'numpy.ndarray'>
<clase 'lista'>
leer fotos
img = dict[b'data']
print(img.shape)
Resultado de salida: (10000, 3072), donde 3072 = 32 * 32 * 3 (tamaño de imagen)
3. Llamada de conjunto de datos
Llamadas de TensorFlow
from tensorflow.keras.datasets import cifar10
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
llamada local
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4. Entrenamiento de redes neuronales convolucionales
Referencia aquí: Portal
1.Especificar GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2. Cargar datos
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3. Preprocesamiento de datos
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4. Construye un modelo
Los parámetros del algoritmo Adam utilizan los parámetros públicos predeterminados de keras, la función de pérdida utiliza la función de pérdida de entropía cruzada dispersa y la precisión utiliza la función de precisión de clasificación dispersa.
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息
#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5.Entrena el modelo
El tamaño del entrenamiento por lotes es 64, la iteración es 5 y la proporción del conjunto de prueba es 0,2 (48 000 datos del conjunto de entrenamiento, 12 000 datos del conjunto de prueba)
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6. Evaluar el modelo
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7. Visualización de resultados
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8. Utilice modelos
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,32,32,3))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
Resultados de salida:

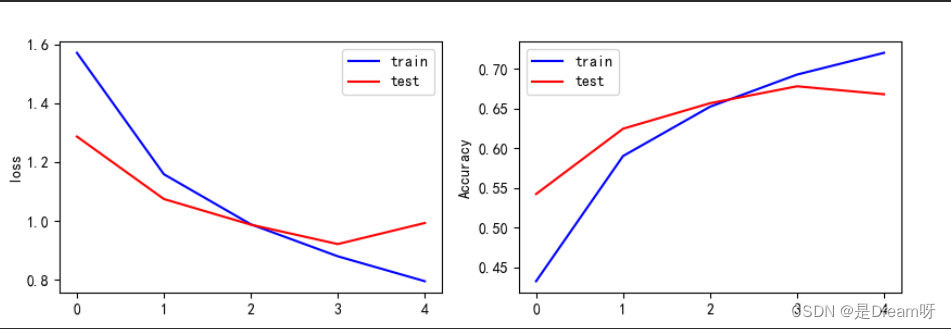
el contenido anterior es el valor de la función de pérdida y la precisión de la muestra de entrenamiento, y el valor de la función de pérdida y la precisión de la muestra de prueba. Puede ver los cambios en la función de pérdida y la precisión en cada iteración de entrenamiento, comenzando desde la última Resultado de la iteración Parece que el valor de la función de pérdida de la muestra de prueba alcanza 0,9123 y la precisión solo alcanza 0,6839.
Este resultado no es muy bueno. Intenté aumentar el número de iteraciones y descubrí que el valor de la función de pérdida de la muestra de entrenamiento podía alcanzar 0.04 y la precisión alcanzó 0.98, pero de hecho, el modelo de entrenamiento produjo errores de generalización cada vez mayores. El fenómeno del exceso es que después de intentarlo, la mejor capacidad de generalización es en la quinta iteración, por lo que solo podemos elegir iterar 5 veces.

Archivo de modelo entrenado: úselo directamente
Introducción al conjunto de datos CIFAR10 y el uso de redes neuronales convolucionales para entrenar modelos de clasificación de imágenes ( código completo y archivos de modelo entrenado adjuntos ) para usar directamente: https://download.csdn.net/download/weixin_51390582/88788820