
Autor: Equipo de Big Data de Internet de vivo: Wu Yonggang, Li Xiong
Este artículo es el cuarto artículo de la serie de artículos "Práctica del modelo de análisis del comportamiento del usuario" del equipo de big data de Internet de vivo: Modelo de análisis de retención.
Este artículo presenta en detalle el concepto y los principios básicos del modelo de análisis de retención y explica su implementación específica en el producto. En vista de los problemas en el proceso de uso real, se exploró una solución práctica basada en el modelo de análisis de retención de ClickHouse.
1. Requisitos de antecedentes
Según las estadísticas de CNNIC, los usuarios de Internet en China han llegado a 1.079 millones y la tasa de penetración de Internet ha alcanzado el 79,4%. Aunque Internet sigue creciendo rápidamente, el número de usuarios se está saturando gradualmente. De hecho, Internet ha entrado en la era de los usuarios existentes. La competencia general por el tráfico se está volviendo cada vez más feroz y la retención de usuarios se está volviendo cada vez más importante que atraer nuevos. usuarios. Por tanto, ¿cómo identificar a los usuarios leales y comprender el rendimiento de retención del grupo de usuarios objetivo? ¿Cómo analizar la pérdida de usuarios y optimizar los productos? Cómo analizar si los usuarios objetivo han completado el comportamiento deseado, etc., son temas importantes en nuestro análisis de datos, y el modelo de análisis de retención es una herramienta importante para resolver estos problemas.
2. Descripción general
2.1 Introducción al concepto
El modelo de análisis de retención se utiliza principalmente para analizar la proporción de usuarios que activaron el evento inicial y desencadenaron eventos posteriores (es decir, eventos de visita repetida) en períodos de tiempo posteriores. Este modelo puede reflejar mejor la lealtad del usuario o la fidelidad del usuario. Hay varios conceptos importantes que se deben comprender sobre el modelo de análisis de retención:

El análisis de retención generalmente requiere especificar el evento inicial y el evento de visita de regreso, pero el evento de inicio y el evento de visita de regreso pueden ser iguales o diferentes:
1. Puede elegir el mismo evento para el evento inicial y el evento de visita posterior. Esto puede ver intuitivamente la cantidad de usuarios leales que activaron el evento.
Por ejemplo: durante el proceso de inicio de sesión, el evento inicial es el inicio de sesión exitoso y el evento de nueva visita es el inicio de sesión exitoso. Dentro de un período de tiempo, la cantidad de usuarios que activan continuamente este evento puede ser la cantidad de. Usuarios leales.
2. Puede elegir diferentes eventos para el evento inicial y el evento de visita posterior. Estos son los datos de retención del usuario bajo un proceso relativamente normal.
Por ejemplo: en una determinada actividad, desde la realización del pedido hasta el pago exitoso, el evento inicial es la realización del pedido y el evento de nueva visita es el pago exitoso. Dentro de un período de tiempo, el mismo usuario que desencadena estos dos eventos es el proceso designado. datos de retención de usuarios.
2.2 Ideas de análisis
La tasa de retención es uno de los indicadores principales de un producto. Mejoramos las capacidades del producto, mejoramos la experiencia del usuario y analizamos a los usuarios objetivo en gran medida para mejorar este indicador. Por ejemplo, podemos evaluar si una determinada iteración es positiva calculando la tasa de retención en N días. Como se muestra en la Figura 1, si una aplicación optimiza el diseño de la página de inicio y lanza la nueva versión A, se puede combinar con la versión anterior B para calcular la tasa de retención diaria de usuarios. Generalmente formará una curva de retención decreciente. Cuanto más lentamente decae la curva, mayor es nuestra tasa de retención, lo que también refleja que la modificación de nuestra página de inicio tiene un efecto positivo. Por supuesto, a veces la mejora en la retención puede ser solo de unas pocas décimas porcentuales, pero bajo la premisa de una gran base de usuarios, también puede producir algunos cambios cualitativos. También podemos definir grupos específicos de personas como grupos de usuarios, realizar análisis de retención en diferentes grupos de usuarios y descubrir grupos de usuarios más leales.
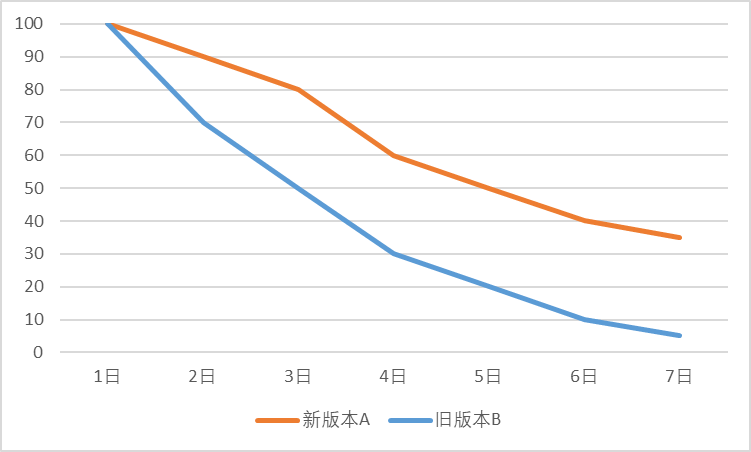
Figura 1 Comparación de la retención entre la nueva versión A y la antigua versión B
3. Análisis de datos mediante retención
Ahora que entendemos los conceptos básicos del modelo de retención anterior, veamos cómo crear uno.
3.1 Seleccionar un evento inicial y un evento de visita de regreso
Evento inicial: abra el navegador.
Evento de visita de regreso: salga del navegador.
3.2 Establecer días de retención
Establezca un período de retención de 3 días.
3.3 Determinar el intervalo de tiempo de retención
El concepto de intervalo de tiempo aquí se refiere al intervalo de fechas que necesita ver. Por ejemplo, si selecciona el intervalo de tiempo como 2023-01-06~2023-01-08, entonces solo los tres días desde 2023-01-06 hasta. Se calculará el 8 de enero de 2023, cada día se retiene el mismo día, se retiene el primer día, se retiene el segundo día y se retiene el tercer día.
3.4 Lógica de visualización y cálculo de los datos retenidos
Número de usuarios iniciales = Número de usuarios que activaron el evento inicial en la fecha calculada.
El número de usuarios retenidos en el día = la intersección de los usuarios que activaron el evento de revisita ese día y los usuarios que activaron el evento inicial ese día.
El número de usuarios retenidos el primer día = la intersección de los usuarios que activaron el evento de revisita al día siguiente y los usuarios que activaron el evento inicial en la fecha calculada.
El número de usuarios retenidos el segundo día = la intersección de los usuarios que activaron el evento de revisita después de 2 días y los usuarios que activaron el evento inicial en la fecha calculada.
El número de usuarios retenidos el tercer día = la intersección de los usuarios que activaron el evento de revisita después de 3 días y los usuarios que activaron el evento inicial en la fecha calculada.
La tasa de retención del día = la cantidad de usuarios retenidos en el día / la cantidad inicial de usuarios * 100%.
La tasa de retención el primer día = la cantidad de usuarios retenidos el primer día / la cantidad de usuarios iniciales * 100%.
La tasa de retención el segundo día = la cantidad de usuarios retenidos el segundo día/la cantidad inicial de usuarios*100%.
Tasa de retención el tercer día = número de usuarios retenidos el tercer día/número inicial de usuarios*100%.
La tabla de números de retención de usuarios (es decir, la Tabla 1) indica que cuando el evento inicial es "abrir navegador" y el evento de nueva visita es "salir del navegador", corresponde a los usuarios retenidos en los últimos 3 días desde el 2023-01-06 hasta 2023-01-09.
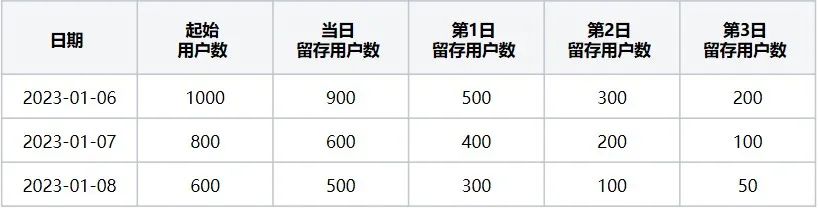
Tabla 1 Tabla de números de retención de usuarios
La tabla de tasa de retención de usuarios (es decir, la Tabla 2) indica que cuando el evento inicial es "abrir navegador" y el evento de nueva visita es "salir del navegador", corresponde a los usuarios retenidos en los últimos 3 días desde el 2023-01-06 hasta 2023-01-08. Datos de proporción.
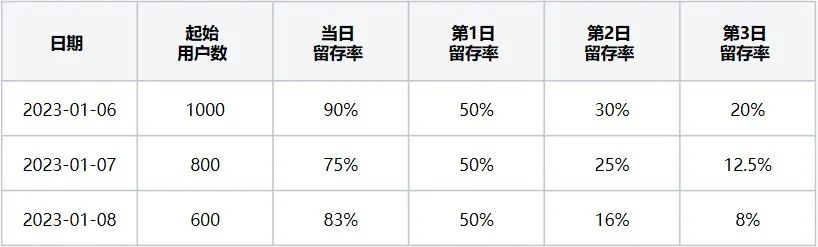
Tabla 2 Tabla de tasa de retención de usuarios
Tomando como ejemplo los datos del 6 de enero de 2023 en la Tabla 1, la cantidad de usuarios iniciales el 6 de enero es 1000: se refiere a la cantidad de usuarios que activaron el evento inicial "abrir navegador" y la cantidad de usuarios retenidos en ese; día: 900: se refiere a la cantidad de usuarios que activaron el evento inicial "abrir navegador" La cantidad de usuarios que activaron el evento de visita de regreso "salir del navegador" el mismo día entre los usuarios del evento inicial;
Número de usuarios retenidos el primer día: 500: se refiere al número de usuarios que activaron el evento de nueva visita el 7 de enero y se cruzaron con el evento inicial el 6 de enero. Número de usuarios retenidos el segundo día: 300: se refiere al número de usuarios que activaron el evento de visita de regreso el 8 de enero Y el número de usuarios de la intersección que activaron el evento inicial el 6 de enero es 300, y así hasta el tercer día. En este momento, los tres días de datos retenidos para el día. 2023-01-06 están calculados!
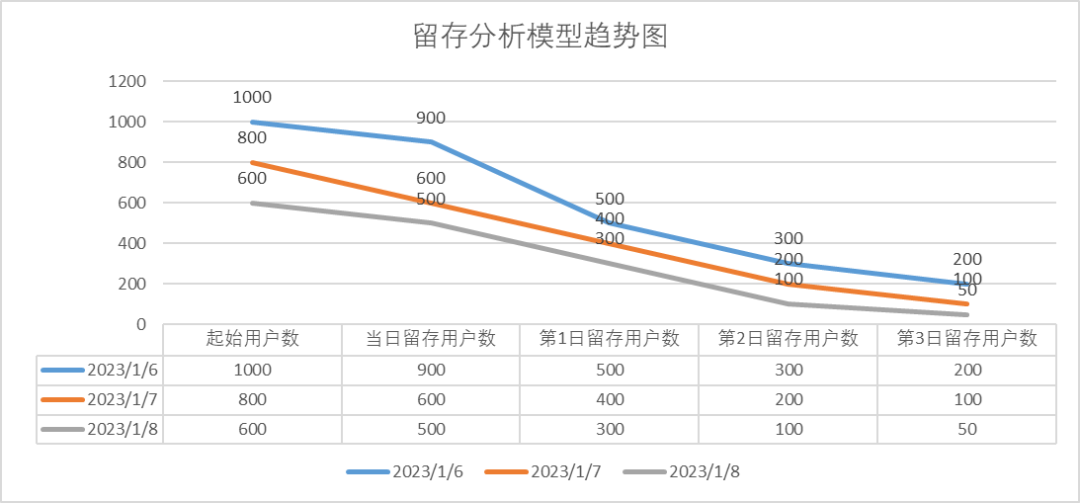
Figura 2: Gráfico de tendencias de usuarios retenidos dentro de los 3 días correspondientes al evento inicial desencadenante y al evento de visita de regreso
4. Diseño funcional general e implementación del modelo de análisis de retención.
4.1 Diseño de arquitectura general de funciones (fuera de línea)
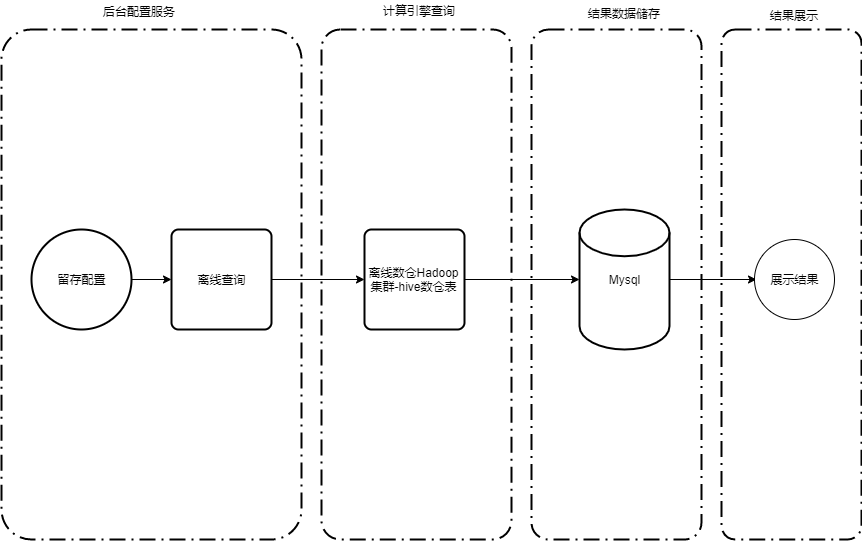
Figura 3 Diagrama de arquitectura de Hive del modelo de análisis de retención
La arquitectura general se divide principalmente en cuatro etapas: configuración, cálculo, almacenamiento y visualización.
1. Configuración
Esta etapa se trata principalmente de la implementación de servicios en segundo plano en el lado de la ingeniería. Los usuarios pueden configurar eventos de inicio y eventos de visita de regreso, condiciones de filtrado, filtrado de grupos de usuarios, filtrado de dimensiones y otras configuraciones según sus propias necesidades en la plataforma. Después de recibir la solicitud de configuración, el servicio en segundo plano selecciona diferentes ensambladores de tareas según el tipo de análisis de retención para ensamblar las tareas SQL.
2. Cálculo
Según el método de consulta recibido, la plataforma selecciona el motor Spark de consulta fuera de línea para su análisis y cálculo. Los resultados de los cálculos sin conexión se sincronizan con MySQL.
3. Almacenamiento
El conjunto de resultados fuera de línea se conserva en la base de datos MySQL y se puede mostrar al usuario a través del servicio en segundo plano.
4. Mostrar
Los resultados fuera de línea se muestran de acuerdo con el ID de configuración del gráfico consultando los datos de la tabla de resultados de MySQL. La consulta instantánea se consulta y muestra directamente después de la configuración.
4.2 (Sin conexión) Implementar SQL bajo diferentes condiciones de retención
Ejecución universal sin conexión de la tarea de colmena SQL
Ejecución de colmena de retención sin conexión SQL
Los significados de los campos en SQL son:
[origin_day]: fecha inicial del cálculo de retención
[día]: Fecha de cálculo de retención final
[diff]: ¿En qué día guardar?
[usuario]: Número de usuarios iniciales
【retención】:número de retención
El significado de SQL anterior: consultar los datos de retención detallados de cada día en el intervalo desde la fecha de inicio del cálculo de la retención hasta la hora de inicio y finalización. Los datos de retención completos en el intervalo de tiempo no se pueden calcular de una vez. Requiere una consulta acumulativa. varios días, y el resultado de esta ejecución de SQL se muestra como un triángulo invertido que completa la tabla de resultados retenidos.
Por ejemplo: después de configurar el evento de inicio y el evento de visita de regreso, calculamos la retención de 3 días para cada día desde el 2022-05-01 hasta el 2022-05-05. En este momento, la hora de inicio es 2022-05-01. y la hora de finalización es el 5 de mayo de 2022, el período de retención es de 3 días.
Para este caso, la fecha de cálculo de retención inicial debe ser 2022-05-01~2022-05-08, de modo que la retención de 3 días se pueda calcular para cada día desde 2022-05-01~2022-05-05.
Paso 1 : Calcule la fecha de retención inicial = 2022-05-01, y el rango de fechas de cálculo de retención final son los datos de retención diarios del 2022-05-01 al 2022-05-05. Desde una perspectiva temporal, la fecha de cálculo de retención inicial. Solo puede calcular la retención el 01/05/2022. Los resultados después de la ejecución son los siguientes (Tabla 3):

Tabla 3
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表4):
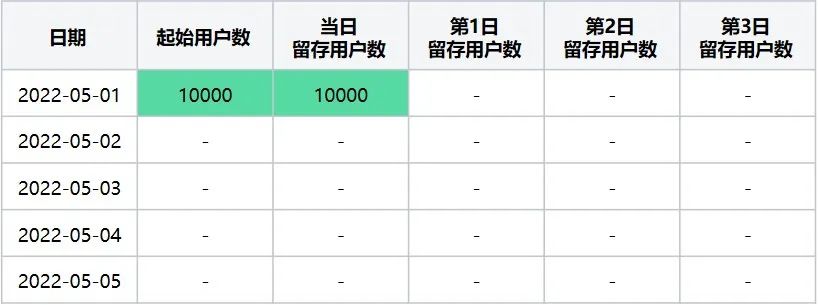
表4
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内转换后留存数据表
第二步:计算起始留存日期 = 2022-05-02时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第1日留存用户数及2022-05-02日当日留存用户数据,执行后结果如下(表5):

表5
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表6):
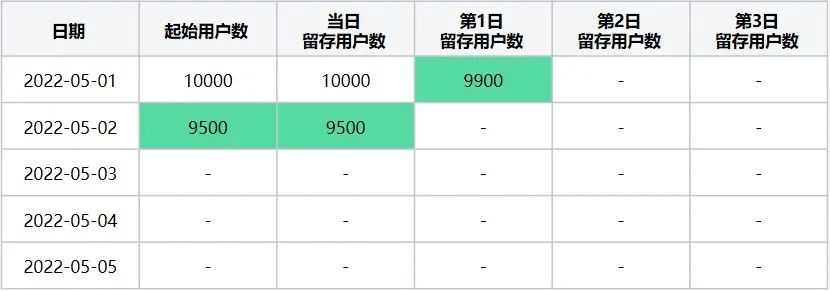
表6
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内转换后留存数据表
第三步:计算起始留存日期 = 2022-05-03时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第2日留存用户数、2022-05-02日第1日留存用户数据、2022-05-03日当日留存用户数据,执行后结果如下(表7):
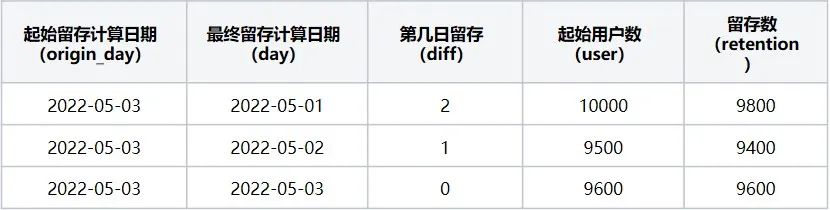
表7
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表8):
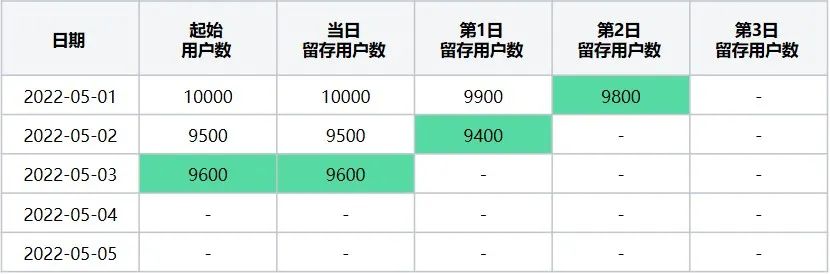
表8
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内转换后留存数据表
第四步:以此类推,计算起始留存日期 = 2022-05-08时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-05日的第3日留存用户数,执行后结果如下(表9):

表9
起始留存计算日期2022-05-08在2022-05-01~2022-05-05区间内留存详情数据
最终数据展示完全后会是一个完整的表格(可得如下结果表10):
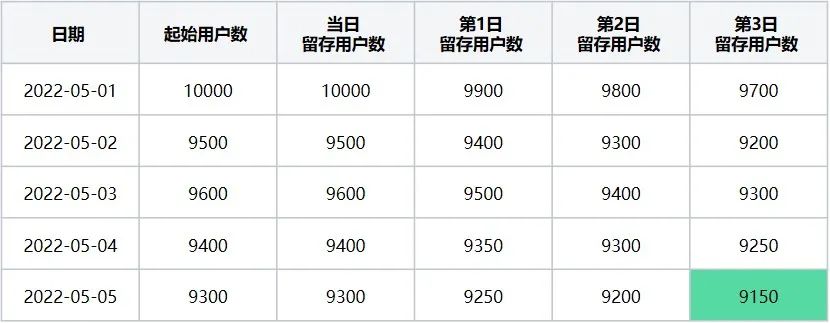
表10
2022-05-01~2022-05-05的每一天的3日留存数据表
4.3 存在的问题与下一步优化的方向
存在的问题:
用户在平台上进行报表创建后,在产出报表结果上耗时较长;当配置报表查询周期长,数据量大的情况下,存在计算资源消耗过大的情况。
优化方向:
为了优化报表生成过程,可以考虑使用ClickHouse来处理数据。ClickHouse是一个高性能、分布式、列式存储的数据库系统,特别适合处理大规模数据和复杂查询。
具体而言,可以采用以下ClickHouse特性:
将数据导入ClickHouse中,以便更快地查询和计算。ClickHouse支持高效的数据导入和压缩方式,可以大大减少数据的存储空间和查询时间。
利用ClickHouse的列式存储和分布式计算能力,实现增量计算和数据预处理。通过使用ClickHouse的分布式计算能力,可以将计算任务分配给多个节点并行处理,从而加快计算速度。同时,通过使用ClickHouse的列式存储能力,可以避免不必要的数据读取和计算,提高计算效率。
利用ClickHouse的缓存机制,提高查询效率。ClickHouse支持高效的缓存机制,可以将查询结果缓存在内存中,以便更快地响应查询请求。
利用ClickHouse的SQL查询语言,实现灵活的数据分析和报表生成。ClickHouse支持SQL查询语言,可以方便地进行数据分析和报表生成,同时也支持复杂查询和聚合操作,可以满足各种数据分析需求。
通过利用ClickHouse上述特性,进一步提高整个数据分析过程的效率和准确性。
五、基于ClickHouse的留存分析模型
5.1 利用ClickHouse查询速度快的特性改造离线留存图表产出方式
利用ClickHouse进行实时留存查询
传统的离线留存计算通常需要借助Hadoop、Spark等大数据处理框架,需要消耗大量计算资源和时间。而利用ClickHouse进行离线留存计算,可以大大提高计算速度和效率,可以实现秒级响应和高并发查询。
具体步骤如下:
将用户行为数据导入ClickHouse;
根据查询配置数据组装留存SQL用于查询;
利用ClickHouse的高速查询功能,实时查询留存率数据。
利用ClickHouse进行留存图表的产出
利用ClickHouse进行留存计算和查询后,可以通过数据可视化工具对留存数据进行图表化展示,从而更加直观地了解用户留存情况。例如:
利用数据可视化工具连接ClickHouse数据库,查看留存率数据或者通过http请求查询结果表数据;
通过数据可视化工具绘制留存图表,并进行定制化设计和样式调整。
结合hive、ClickHouse两者优点,可将架构做如下优化,对于历史较长时间日期的结果回溯进行hive查询处理,可在ClickHouse中存储的数据作为每天例行查询存储结果。
例行:是指创建一次图表每日例行执行报表任务,产出数据(例行可回溯ClickHouse中存储日期的留存数据)。
手动:是指在指定时间范围内执行,执行完成产出任务停止。
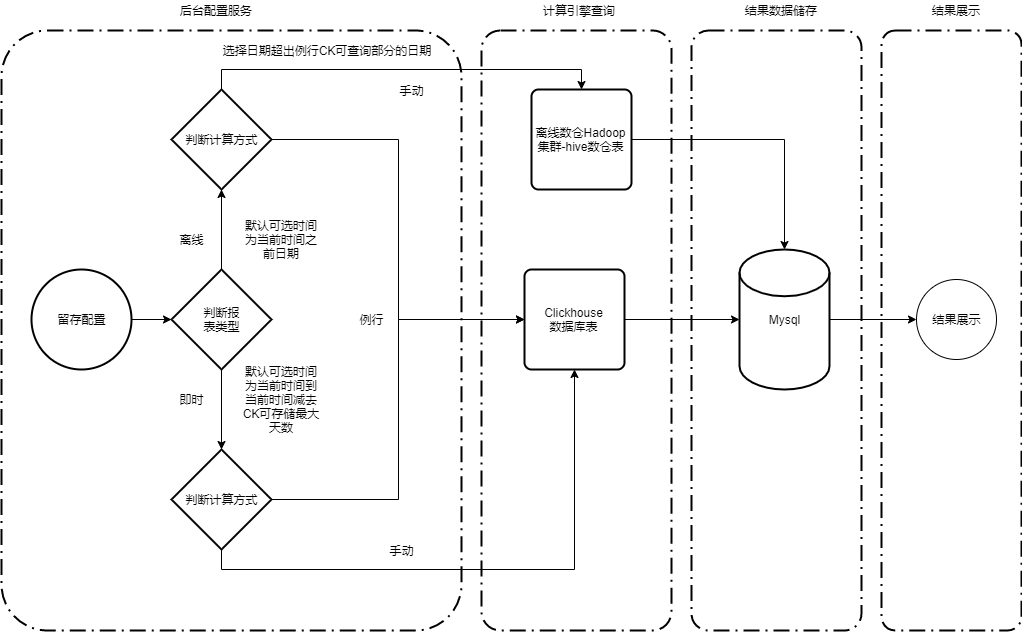
图4 结合ClickHouse、hive后留存分析模型架构图
5.2 主要函数介绍
Retention
该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如 WHERE)。
除了第一个以外,条件成对适用:如果第一个和第二个是真的,第二个结果将是真的,如果第一个和第三个是真的,第三个结果将是真的,等等。
① 语法
retention(cond1, cond2, ..., cond32);
② 参数
cond — 返回 UInt8 结果(1或0)的表达式。
③ 返回值
数组为1或0。
1 — 条件满足。
0 — 条件不满足。
④ 类型
UInt8
ClickHouse查询SQL
ClickHouse即时查询留存SQL
SQL 当中返回结果含义分别为:
retention_date:留存日期
user:起始用户数
retain0:当日留存用户数
retain1:第1日留存用户数
retain2:第2日留存用户数
retain3:第3日留存用户数
ratio0:当日留存率
ratio1:第1日留存率
ratio2:第2日留存率
ratio3:第3日留存率
以上SQL含义:计算出指定时间区间内3日留存信息,可一次性查询出指定区间内的所有3日留存数据,一个sql即可查询完全。
例如:我们定了起始事件和回访事件后,去计算2022-06-01~2022-06-04的每一天的3日留存,此时,起始时间是2022-06-01,结束2022-06-04,留存天数3天。
针对此案例,在不同的日期查询数据完整性不一致,我们拿2022-06-04日和2022-06-07日两日查询举例。
第一步:针对2022-06-04日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表11)。

表11
2022-06-04日计算2022-06-01~2022-06-04的每一天的3日留存数据表
第二步:针对2022-06-07日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表12)。

表12
2022-06-08日计算2022-06-01~2022-06-04的每一天的3日留存数据表
趋势结果展示(图5):
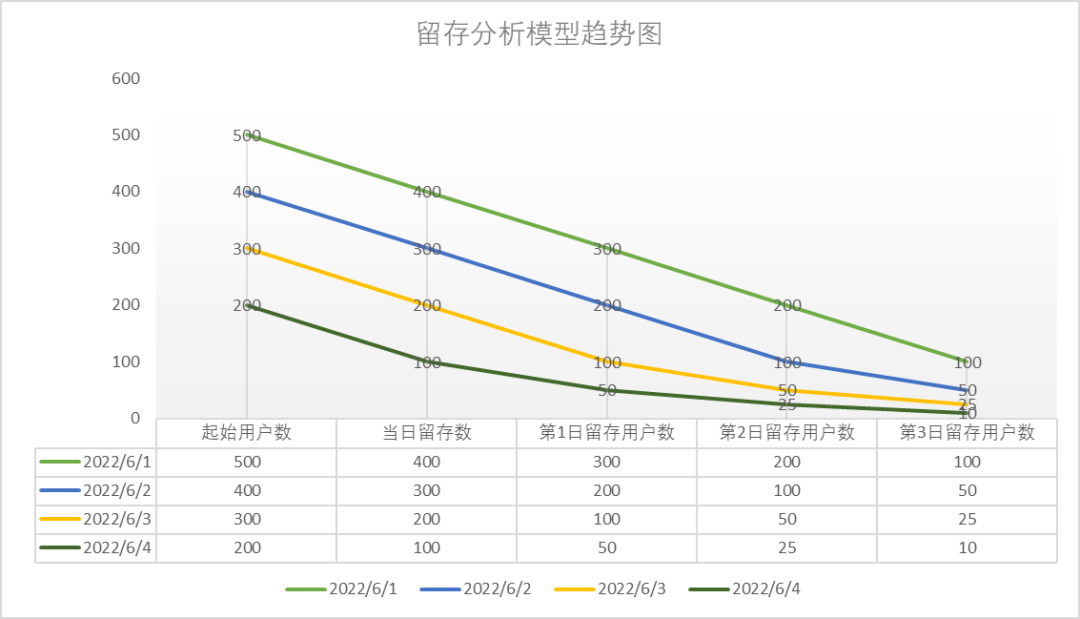
图5 留存分析模型趋势图
六、写在最后
本文介绍的留存模型就是数据分析工具箱的核心分析模型,使用的范围十分广泛。它通过计算用户在一段时间内的留存率,可以评估产品、服务或应用程序的用户体验和吸引力,提高用户留存率和活跃度。在实际的生产中,业务可根据自身具体需求和用户特征进行定制化设计,同时也可将通过留存分析得到的人群信息结合其他的数据分析方法进一步的深入分析。例如,从留存中得到的用户人群信息,我们可以进一步的使用路径分析的分析方法,分析用户的访问行为对于产品的影响。
数据分析的工具方法有很多,除了上面提到过得用于分析用户在应用上的访问行为的用户路径分析;也有衡量业务中关键事件之间转化效果的漏斗分析;还有事件分析、归因分析等等,他们共同组成的强大的数据分析工具箱,可以较为全面的分析用户行为的潜在特征与规律,帮助产品或者决策者作为更加可靠的决策。
END
猜你喜欢
本文分享自微信公众号 - vivo互联网技术(vivoVMIC)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。