LLaMA2 of LLMs: a detailed introduction to LLaMA2 (technical details), installation, usage (open source-free for research and commercial use)
Guide : On July 18, 2023, Meta will release Llama 2! This is a set of pre-trained and fine-tuned large language models (LLMs) ranging in size from 7 billion to 70 billion parameters. The Meta-fine-tuned LLM is called Llama 2-Chat, which is optimized for conversational usage scenarios. The Llama 2 model outperforms the open-source chat model on most of the benchmarks we tested, and may be an appropriate replacement for the closed-source model for reliability and security, based on Meta's human evaluations. Meta provides detailed instructions on how to fine-tune and improve the security of Llama 2-Chat in order for the community to build on Meta's work and contribute to the responsible development of LBM.
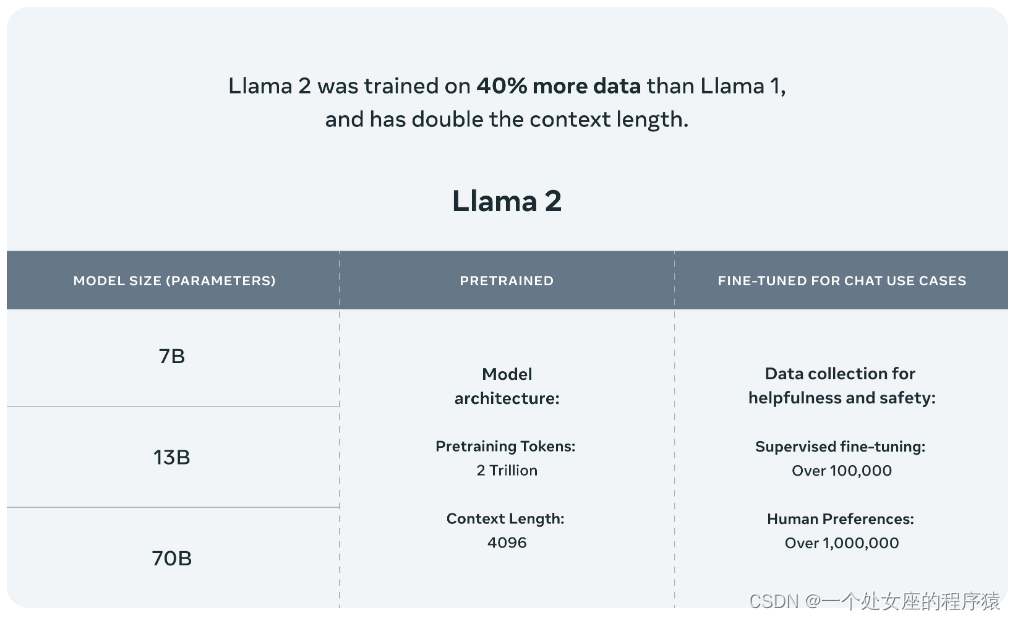
Llama 2 = Llama 1 [RoPE+RMSNorm+SwiGLU+AdamW] + 40% new data volume + 2T tokens + 4096 + high -quality SFT + RLHF alignment [PPO + Rejection sampling fine-tuning] : The Llama 2 model is trained on 2 trillion tokens , and the Llama-2-chat model has additionally trained more than 1 million new human annotations. Llama 2 has 40% more data than Llama 1 and doubles the context length . And, Llama-2-chat uses reinforcement learning from human feedbackto be safe and useful. Llama 2 adopts most of the pre-training setup and model architecture from Llama 1, including the standard Transformer architecture, prenormalization using RMSNorm, SwiGLU activation function, and rotated position embedding. The AdamW optimizer is used for training, where β_1 = 0.9, β_2 = 0.95, eps = 10^−5. At the same time, a cosine learning rate schedule (2000 steps of warm-up) was used, and the final learning rate was decayed to 10% of the peak learning rate. Meta pre-trained the model on its Research Super Cluster (RSC) as well as its internal production cluster. Three
commonly used benchmarks evaluated the safety of Llama 2 : TruthfulQA benchmark for authenticity + ToxiGen benchmark for toxicity + BOLD benchmark for bias. Meta uses supervised secure fine-tuning, secure RLHF, secure context distillation in secure fine-tuning. RLHF begins by collecting data on human preferences for safety, where annotators write prompts that they believe elicit unsafe behavior, then compare multiple model responses to the prompts, and select the safest response based on a set of guidelines. The human preference data is then used to train a secure reward model, and an adversarial prompt is reused in the RLHF stage to sample from the model. Meta refines the RLHF pipeline with context distillation.
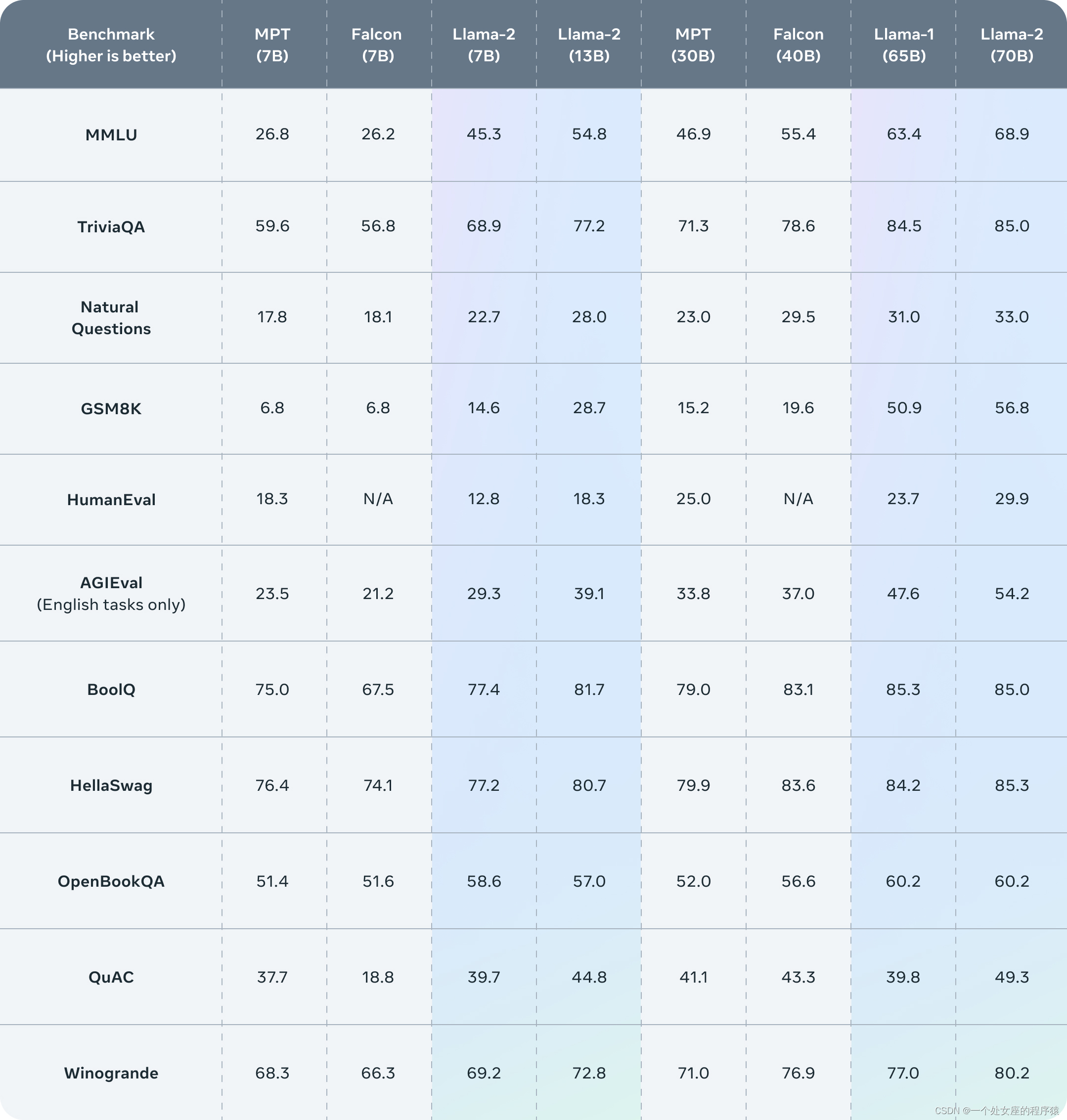
The performance of the model is open source and the show + high cost [ A100 ] + still follow the Open route: Both Meta clusters use NVIDIA A100. HuggingFace machine learning scientist Nathan Lambert estimates that Llama 2 could cost more than $25 million to train. Meta published a large number of details of the Llama 2 model training data, training methods, data labeling, fine-tuning, etc. The comparison found that, with the same parameter scale, Llama 2 is more capable than all open source large models; the published evaluation results show that Llama 2 is better than other open source language models in many external benchmarks including reasoning, coding, proficiency and knowledge testing.
The birth of Llama 2, as well as its open-source temperament, directly insists on those who say they want to be Open but are not Open at all, GPT-4, which has been building a "technical fence", and Google's PaLM 2. Llama 2 will be an important milestone for LLMs in the open source field. In the future, there will be a high probability of accelerating changes in the pattern and ecology of the large language model market.
So, today, have you changed the base of your LLMs?
Table of contents
2. Llama-2-chat uses reinforcement learning from human feedback to be safe and useful
1. Download Download model weights and tokenizers
T1. Download from the official website
T2, download based on Hugging Face
(3), fine-tuning the chat model
related articles
LLaMA of LLMs: Translation and Interpretation of "LLaMA: Open and Efficient Foundation Language Models"
Introduction to LLaMA2
| address |
GitHub地址:GitHub - facebookresearch/llama: Inference code for LLaMA models Paper address: Blog address: https://ai.meta.com/resources/models-and-libraries/llama/ |
| time |
July 18, 2023 |
| author |
Meta |
Introduction to LLaMA2
On July 18, 2023, Meta released Llama 2 heavily. As stated on the official website, Meta is releasing the power of these large language models. Llama 2 is now available to individuals, creators, researchers, and businesses so they can experiment, innovate, and scale their ideas responsibly. This release includes model weights and starting code for pre-training and fine-tuning the Llama language model, ranging from 7B to 70B parameters.
Llama 2 is pretrained on publicly available online data sources. The fine-tuned model Llama-2-chat leverages a publicly available instruction dataset with over 1 million human annotations. Internally, the Llama 2 model is trained on 2 trillion tokens with twice the context length of Llama 1. The Llama-2-chat model was additionally trained on over 1 million new human annotations. Llama 2 has 40% more data than Llama 1 and doubles the context length. And, Llama-2-chat uses reinforcement learning from human feedback to be safe and useful.
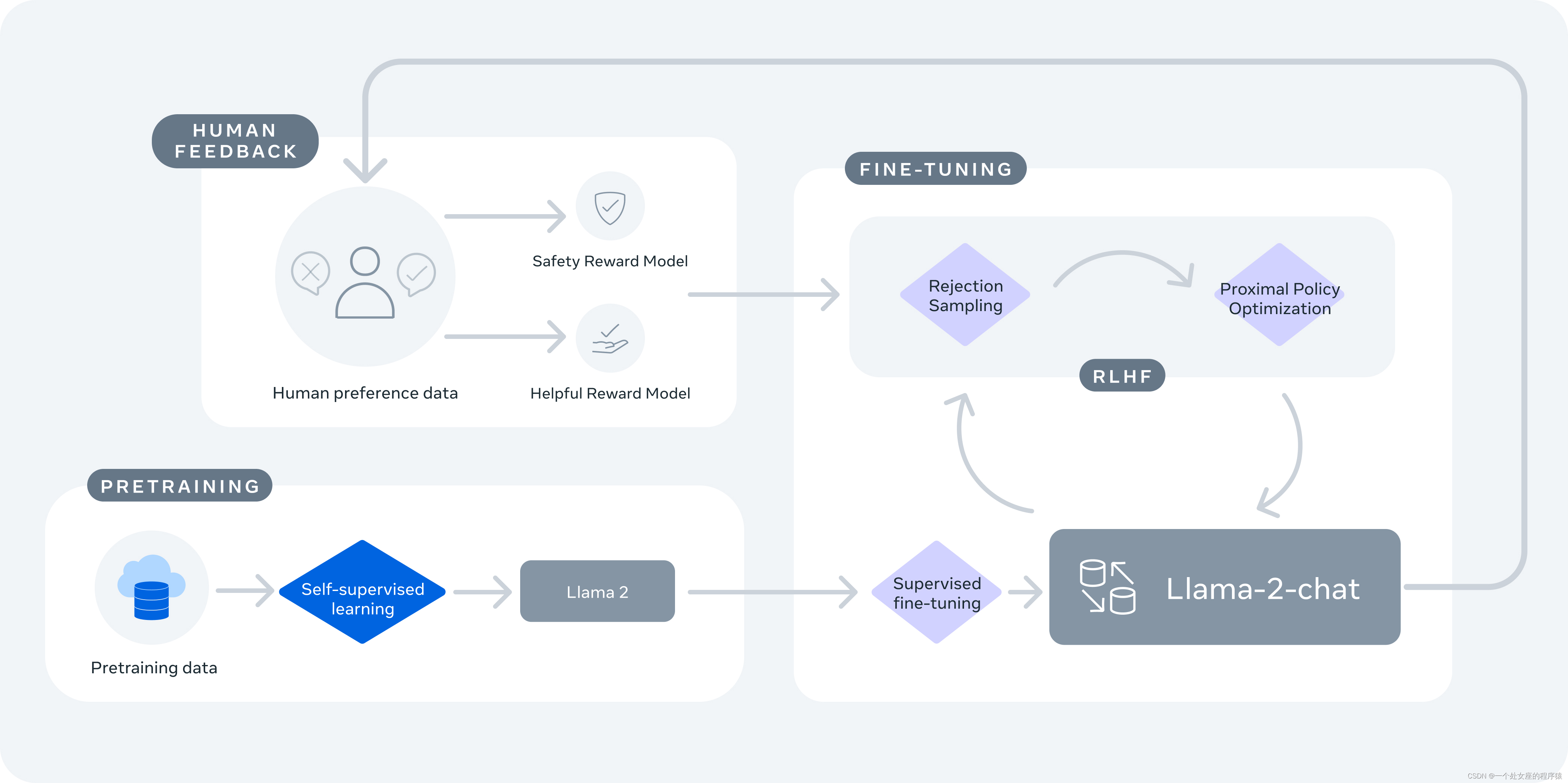
Llama-2-chat is pre-trained on Llama 2 using publicly available online data. An initial version of Llama-2-chat is then created using supervised fine-tuning. Next, iterative optimization of Llama-2-chat is performed using reinforcement learning from human feedback (RLHF), which includes rejection sampling and proximal policy optimization (PPO).
1. Benchmark test
Llama 2 outperforms other open-source language models on many external benchmarks, including inference, coding, proficiency, and knowledge tests.
2. Llama-2-chat uses reinforcement learning from human feedback to be safe and useful
Installation of LLaMA2
1. Download Download model weights and tokenizers
T1. Download from the official website
If you download model weights and tokenizers, you need to visit the Meta AI website and accept Meta's license. Once your request is approved, you will receive a signed URL by email. Then run the download.sh script, passing the provided URL when prompted to start the download. Make sure to only copy the URL text itself, and not use the "Copy Link Address" option when you right-click on the URL. If the copied URL text starts with https://download.llamameta.net ↗, then you copied it correctly. If the copied URL text starts with https://l.facebook.com ↗, you copied it wrong.
Make sure wget and md5sum are installed. Then run the script:
./download.shT2, download based on Hugging Face
We also offer downloads on Hugging Face. You must first request the download from the Meta AI website using the same email address as your Hugging Face account. After doing so, you can request access to any model on Hugging Face and within 1-2 days your account will be granted access to all versions.
2. Installation
In a conda environment with PyTorch/CUDA, clone the repository and run in the top-level directory
pip install -e How to use LLaMA2
1. Basic usage
(1), model reasoning
Different models require different Model Parallelism (MP) values
| Model | MP |
|---|---|
| 7b | 1 |
| 13b | 2 |
| 70b | 8 |
All models support sequence lengths up to 4096 tokens , but we pre-allocate buffers based on max_seq_len and max_batch_size values. So set these values according to your hardware.
(2), pre-training model
These models were not fine-tuned for chat or question answering. They should be prompted so that the expected answer is a natural continuation of the hint.
See example_text_completion.py for some examples. To illustrate this, see the command below to run it with the llama-2-7b model (nproc_per_node needs to be set to the MP value):
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4(3), fine-tuning the chat model
These fine-tuned models are trained for conversational applications. For expected features and performance, a specific format defined in chat_completion needs to be followed, including INST and <<SYS>> tags, BOS and EOS tags, and spaces and newlines between them (we recommend calling strip() on the input to avoid double spaces).
You can also deploy additional classifiers to filter out inputs and outputs that are considered unsafe. See the llama-recipes repository for examples of how to add safety checkers to the input and output of your inference code.
Example using llama-2-7b-chat:
torchrun --nproc_per_node 1 example_chat_completion.py
--ckpt_dir llama-2-7b-chat/
--tokenizer_path tokenizer.model
--max_seq_len 512 --max_batch_size 4Llama 2 is a new technology and its use is potentially risky . The tests performed so far do not cover all situations . To help developers address these risks, we've created Responsible Use Guidelines. More details can be found in our research paper.