Deep learning natural language processing sharing
Zhihu: Huang Wenhao,
technical director of Beijing Zhiyuan AI Research Institute
After the release of LLaMA2, the Chinese open source community began localization work in full swing. On the day the LLaMA2 model was released, there was a lot of work that took up the pit, and when I clicked in, it was empty repo. Fortunately, everyone was extremely efficient, and the volume flew up. In the past two days, I have played with several related tasks, and overall it is still good. LLaMA2's strong English basic ability, coupled with little Chinese data and unfriendly tokenizer, gives students who do Chinese SFT and Chinese continue pretraining a great opportunity, and at the same time, it will bring a lot to some players trained from scratch challenge. The following records a few jobs that I feel are pretty good.
Enter the NLP group —> join the NLP exchange group
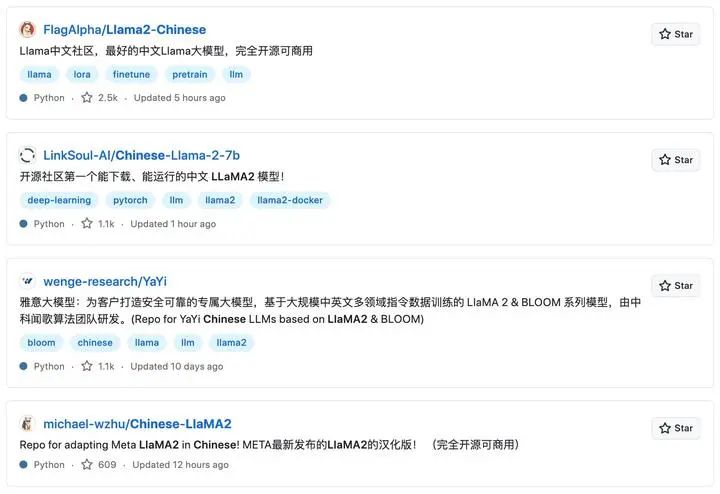
Chinese-LLaMA2-7b from LinkSoul
I am very familiar with several authors of this work [1] , and have made many calls to them. But their hand speed still shocked me. When everyone is opening the repo to occupy the hole, the author's instruction tuning of tens of millions of data has been completed. In fact, on the day when LLaMA2 was open sourced, I actually played this model that supports Chinese, and the Chinese ability is decent.
At the same time, the team is very down-to-earth, not obsessed with ranking and PR, but has successively launched very practical docker one-click deployment, 4bit quantification, and API services. The user community is also very active, and many questions can be answered immediately.
The main contribution of the author is to enable the model to have a good ability to follow instructions through the method of instruction tuning. At the same time, through the training of a large amount of Chinese instruction data, the Chinese ability of the model has been greatly improved. Different from the work of Alpaca, Vicuna, etc., the author uses nearly 1000w instruction data for instruction fine-tuning, and completes the two tasks of improving Chinese ability and instruction fine-tuning. And all 10 million instruction data are open source! Anyone with a little resources can try it in this way. The address is here [2] .
Looking closely at the open source instruction dataset, we can see that the author merged a large number of open source instruction fine-tuning datasets, and at the same time handled the format well. And if you look at the code carefully, you will find that the author used the System Message method for fine-tuning. During the fine-tuning, the ratio of the Chinese and English datasets maintained a relationship of almost 1:1. From these details, it can be seen that the author has a deep understanding of instruction fine-tuning, and the work is very meticulous, which is worth learning for all other teams who do instruction fine-tuning.
I simply tested MMLU and CMMLU with OpenCompass, and the overall performance is OK.

It is a pity that the author did not expand the Chinese vocabulary and continue pre-training, so it did not solve the problem of poor performance of LLaMA2's Chinese tokenizer.
Another question worth thinking about is whether it is possible to add knowledge to the model through instruction fine-tuning, and feed the most important knowledge of Chinese to the model through instructions. At the same time, it is equipped with English command data such as Flan. The model can use a large amount of instruction fine-tuning data to perform knowledge learning and instruction learning at the same time. The COIG-PC [3] data set organizes hundreds of millions of instruction data based on various Chinese NLP tasks, and it should be able to complete this task.
Llama2-Chinese-7B from FlagAlpha
The name is too similar to the first one, and I couldn't tell the difference several times. This is the repo with the highest LLaMA2 Sinicization star on Github, and the community operation is also very good. However, after looking at the entire repo, a lot of it is the original model download and evaluation content of LLaMA2. It feels like a resource integration site, and the details of many localization work are not very clear.
The most different point of this work [4] is that it has done continue pretraining, and the data used is relatively rich, which should be able to greatly improve the Chinese knowledge level of the model.
However, the author did not introduce whether there is corresponding English data when continuing pretraining, and the approximate ratio of Chinese and English data. If the ratio is not good, it may affect the English ability of the model. It is also a pity that the author did continue pretraining but did not include a vocabulary. The original tokenizer of LLaMA2 uses about 3 tokens to represent a Chinese character, which has a great impact on the input context window and output_length.
Finally, one thing that is not very clear is that the PR draft of this work is written to pre-train from scratch with 200B token. My understanding is continue pretraining. I don't know if my understanding is wrong or the expression is not accurate.
Overall, it is worth appreciating to be able to complete the continue pretraining of the 13B model on 200B data in about 10 days, while maintaining a very active community.
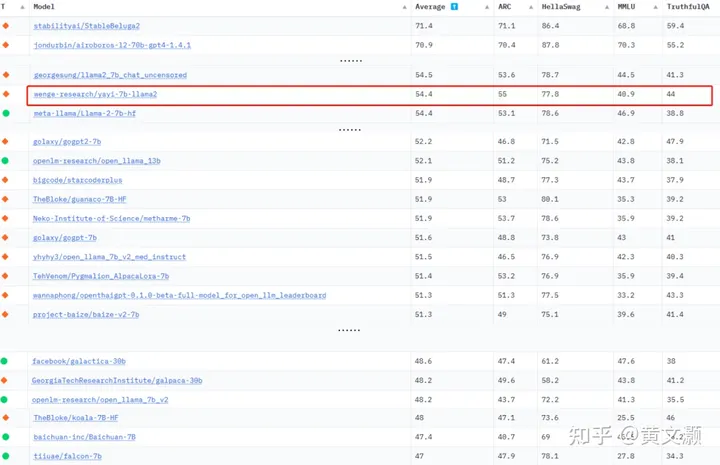
Yayi from Wenge
Judging from the introduction [5] (really few introductions), millions of field instructions were used to fine-tune the data, but only 5w (bad reviews) were released.
After reading the evaluation, the security has increased, but the MMLU has decreased. It is estimated that the fine-tuning was not as detailed as the first work, so you can learn it.
Linly [6]
This is an old project. I believe that those who play LLaMA and Falcon Chinese should have seen their work. Vocabulary expansion, Chinese-English incremental pre-training, Chinese-English command fine-tuning, everything that needs to be done has been done. From the evaluation point of view, the English ability is still good, and the Chinese ability has been significantly improved. LLaMA2 has also improved compared to LLaMA and Falcon. This path is the safest path, but I personally feel that there is still too much Chinese in the data allocation ratio (to be precise, too little English allocation), and it may be better to adjust it again. This is an old project. I believe that those who play LLaMA and Falcon Chinese should have seen their work. Vocabulary expansion, Chinese-English incremental pre-training, Chinese-English command fine-tuning, everything that needs to be done has been done. From the evaluation point of view, the English ability is still good, and the Chinese ability has been significantly improved. LLaMA2 has also improved compared to LLaMA and Falcon. This path is the safest path, but I personally feel that there is still too much Chinese in the data allocation ratio (to be precise, too little English allocation), and it may be better to adjust it again.
expectations for the future
In fact, I didn't have much hope for the localization of LLaMA2. However, the speed of everyone's roll really surprised me. And there are still some interesting things. for example:
It is known that LLaMA2 does not improve much for Chinese large models like ChatGLM, Baichun, and Intern-LM from scratch. For students who are doing continue pretraining and instruction tuning, LLaMA2 has given everyone a good base, and it has greatly improved everyone. I'm curious if the two can get close.
As mentioned earlier, I really want to see if it is possible to supplement Chinese knowledge through super-large-scale instruction fine-tuning. My understanding is that it is only necessary to supplement knowledge, and Chinese cc may not be necessary.
7B and 13B are annoying, who can do a 70B Sinicization, and see how the emerging translation ability affects the Sinicization.
Original link:
https://zhuanlan.zhihu.com/p/647388816

Enter the NLP group —> join the NLP exchange group
References
[1]
LinkSoul: https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
[2]instruction_merge_set: https://huggingface.co/datasets/LinkSoul/instruction_merge_set
[3]COIG-PC: https://huggingface.co/datasets/BAAI/COIG-PC
[4]FlagAlpha: https://github.com/FlagAlpha/Llama2-Chinese
[5]Alcohol: https://github.com/alcohol-research/YaYi
[6]Linly: https://github.com/CVI-SZU/Linly