In this article, let's talk about how to use Docker containers to quickly get started with the Chinese version of the LLaMA2 open source model produced by our friend team. It is the first truly open source model in China, which can be run, downloaded, privately deployed, and supports commercial use.
written in front
After the open download of the Meta LLaMA2 model yesterday, many open source model projects with "only Readme documents" appeared on GitHub, and spread wildly in various groups for a while, just like the futures in the "tulip bubble" story.
When I was eating at noon, I complained with my friends. The friend said, this thing is not difficult, let's make a whole one tonight. I also hope to use this to make the Chinese open source ecology better, so the protagonist of this article is: the Chinese version of the LLaMA2 model.
The address of the project is: https://github.com/LinkSoul-AI/Chinese-Llama-2-7b ; the open-source project https://github.com/soulteary/docker-llama2-chat yesterday , which can use Docker to run LLaMA2, has also added Chinese LLaMA2 model support. Welcome to download, forward, and connect with one click. Let's build a better Chinese open source environment together!
Of course, if you want to use MetaAI's official LLaMA2 large model, you can read yesterday's article: " Using Docker to Quickly Get Started with the Official LLaMA2 Open Source Large Model ".
Preparation
Because the Chinese version of the LLaMA2 model uses the strict input format consistent with the original LLaMA2 for training, the Chinese model is fully compatible with the original program , which greatly reduces the workload for us to use the program in yesterday's article, and the code is almost exactly the same as yesterday's article.
In the preparation part, we still only have two steps to do: prepare the model file and the model running environment.
Regarding the model running environment, we talked about it in the previous article " Docker-based Deep Learning Environment: Getting Started ", so I won't go into details. Students who are not familiar with it can read it for reference.
As long as you have installed the Docker environment and configured the basic environment that can call the graphics card in the Docker container, you can proceed to the next step.
Model download
The Chinese LLaMA2 model is completely open source and open to all people and organizations to download and use, so we can directly use the following command to download and obtain the model file:
# 依旧需要确保你安装了 Git LFS (https://git-lfs.com)
git lfs install
# 然后下载我们的中文模型即可
git clone https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
After downloading the model from HuggingFace, before starting the next step, let's create and adjust a directory for later use.
# 和昨天一样,创建一个目录
mkdir LinkSoul
# 将模型移动到目录中
mv Chinese-Llama-2-7b LinkSoul/
A suitable directory structure would look like the following.
# tree -L 2 LinkSoul
LinkSoul
└── Chinese-Llama-2-7b
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00003.bin
├── pytorch_model-00002-of-00003.bin
├── pytorch_model-00003-of-00003.bin
├── pytorch_model.bin.index.json
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
└── tokenizer.model
2 directories, 10 files
With the model ready, we are ready to run the model.
Start the model application
You download the Docker LLaMA2 Chat model application file using the following command :
git clone https://github.com/soulteary/docker-llama2-chat.git
After waiting for the program to be downloaded, we enter the program directory and start building the Chinese model container image:
# 进入程序目录
cd docker-llama2-chat
# 构建中文 7B 镜像
bash scripts/make-7b-cn.sh
After waiting patiently for the image to be built, we move the previously prepared LinkSouldirectory storing the model to the current program directory, and then select the model program to start:
# 运行中文 7B 镜像,应用程序
bash scripts/run-7b-cn.sh
After the command is executed, if all goes well, you will see a log similar to the following:
=============
== PyTorch ==
=============
NVIDIA Release 23.06 (build 63009835)
PyTorch Version 2.1.0a0+4136153
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:12<00:00, 4.09s/it]
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
Caching examples at: '/app/gradio_cached_examples/20'
Caching example 1/5
/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1270: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
warnings.warn(
Caching example 2/5
Caching example 3/5
Caching example 4/5
Caching example 5/5
Caching complete
/usr/local/lib/python3.10/dist-packages/gradio/utils.py:839: UserWarning: Expected 7 arguments for function <function generate at 0x7fd4ac3d1000>, received 6.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/gradio/utils.py:843: UserWarning: Expected at least 7 arguments for function <function generate at 0x7fd4ac3d1000>, received 6.
warnings.warn(
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Next, use a browser to open http://localhost:7860or http://你的IP:7860to start experiencing the Chinese version of the LLaMA2 Chat model.
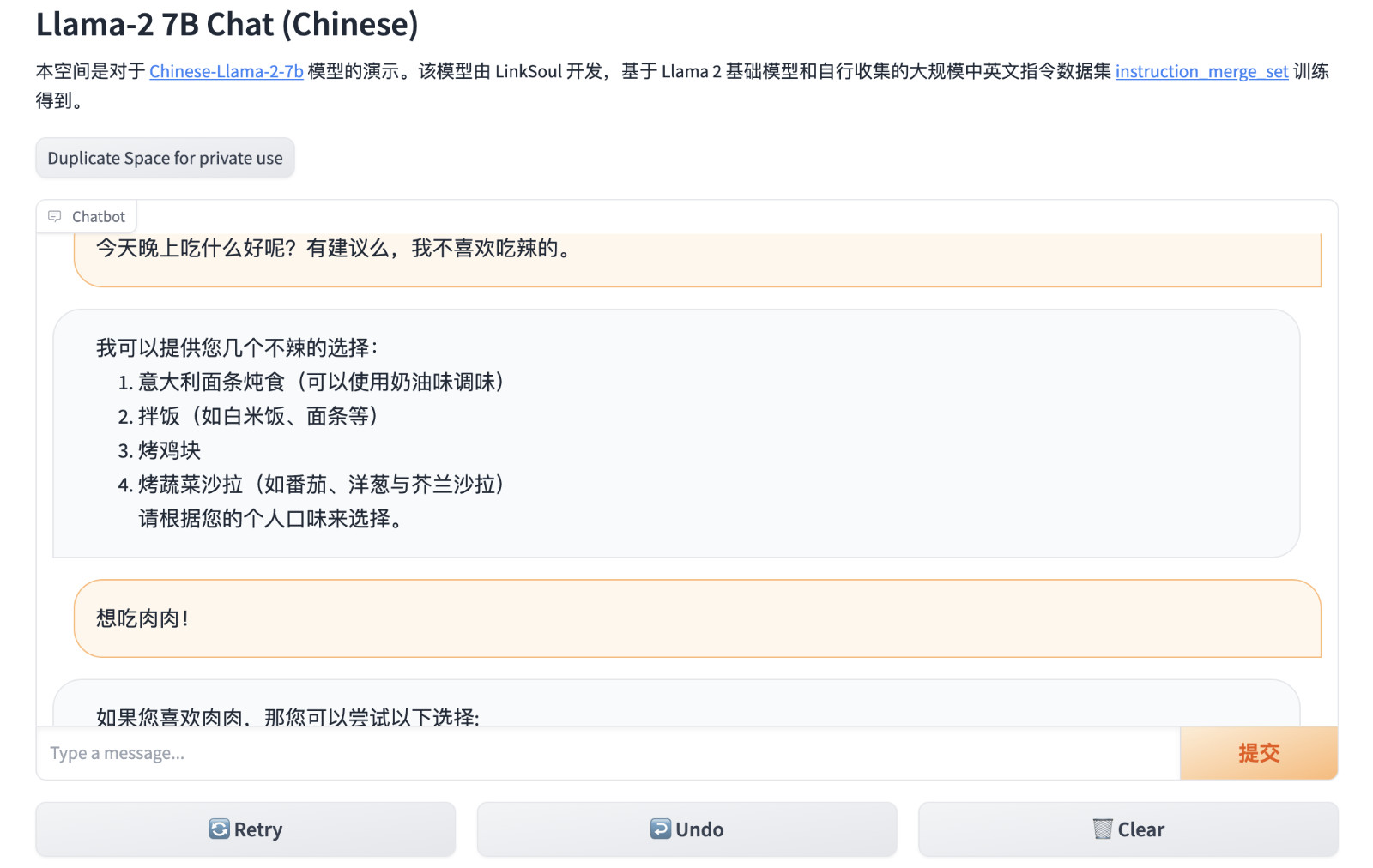
After starting, you can chat and interact with him.
Currently it is only the first version of the model, the effect and status can only be said to have just passed, there should be better versions iterated in the future, let's look forward to it together.
memory usage
There is basically no difference between the video memory consumption and the official original version, and it will take up about 13G of resources.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.125.06 Driver Version: 525.125.06 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 41C P8 33W / 450W | 14101MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1434 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1673 G /usr/bin/gnome-shell 16MiB |
| 0 N/A N/A 27402 C python 13914MiB |
+-----------------------------------------------------------------------------+
Peak operation will consume about 18G of video memory.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.125.06 Driver Version: 525.125.06 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 54% 72C P2 408W / 450W | 18943MiB / 24564MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1434 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1673 G /usr/bin/gnome-shell 16MiB |
| 0 N/A N/A 27402 C python 18756MiB |
+-----------------------------------------------------------------------------+
Well, so far, you have been able to run the Chinese LLaMA2 large model locally. Next, you can play freely. For example, in langChain or various previous tasks, especially specific instructional work, you may wish to use it for a try.
at last
At the end of yesterday’s article, I mentioned that I am optimistic about the future open source model ecology, but in fact, as a technology enthusiast and some industry stakeholders, I also know that the current domestic open source situation is not so good, and there are still many things that can be improved, but this requires everyone to work together .
Therefore, I hope that with friends from all walks of life with different backgrounds and experiences, friends who are interested in open source and models, we can steadily contribute to the open source ecology, use practical actions to improve the Chinese open source technology ecology, and conduct technical evangelism, so that good technologies and good content can be spread more widely, and everyone can know and use these technologies earlier .
If you are interested, let's play together? !
At the end of the article, I have written two basic articles about LLaMA2. Next, let’s talk about interesting engineering practices and scene applications, so that large-scale model technology can fly into thousands of households faster.
–EOF
This article uses the "Signature 4.0 International (CC BY 4.0)" license agreement. You are welcome to reprint or re-use it, but you need to indicate the source. Attribution 4.0 International (CC BY 4.0)
Author of this article: Su Yang
Creation time: July 21, 2023
Counting words: 3599 words
Reading time: 8 minutes to read
This link: https://soulteary.com/2023/07/21/use-docker-to-quickly-get-started-with-the-chinese-version-of-llama2-open-source-large-model.html