In this article, we talk about how to use Docker containers to quickly get started with the LLaMA2 open source large model produced by Meta AI.
written in front
I was very busy yesterday. After applying for the permission to download the LLaMA2 model in the morning, I didn't bother with a Docker container operation solution until evening, and I didn't have time to write an article to talk about what happened to this container and how to use it.
So, now let's talk about how to quickly get started with the large model of the official version of LLaMA2.
I uploaded the complete open source project code to soulteary/docker-llama2-chat , students who need it can pick it up by themselves.
Let's do the preparatory work together first.
Preparation
In the preparation work, there are two main steps: preparing the model file and the model running environment.
Regarding the model running environment, we talked about it in the previous article " Docker-based Deep Learning Environment: Getting Started ", so I won't go into details. Students who are not familiar with it can read it for reference.
As long as you have installed the Docker environment and configured the basic environment that can call the graphics card in the Docker container, you can proceed to the next step.
Model download
To happily deploy LLaMA2 locally, we first need to apply for the download permission of the model file. Currently, there are two places where you can apply: Meta AI official website and Meta's model page on HuggingFace.
No matter which method you choose, after the application, wait for a while, we will receive the approval email, and then refresh the page to download the model.
HuggingFace's model download speed is faster than Meta AI's official website, so we focus on how to prepare the model we need from HuggingFace.
Get the model file from HuggingFace
There are two models (original base model and Chat model) that we can get from HuggingFace; and on the HuggingFace platform, they are saved in two formats: PyTorch Pickle format and HuggingFace SafeTensors format .

If you also use the HuggingFace family bucket, I strongly recommend the latter format: it is future-proof, convenient and reliable, and the loading performance is stronger (faster).
In order to facilitate the demonstration and get a decent experience, in this article, we use the "LLaMA2-Chat-HF" version of the model, you can apply for model download authorization at the following address:
- https://huggingface.co/llamaste/Llama-2-7b-chat-hf
- https://huggingface.co/llamaste/Llama-2-13b-hf
- https://huggingface.co/llamaste/Llama-2-70b-hf
Among them, the 7B and 13B versions of the models can be run on ordinary home video cards (probably using 10G ~ 14G video memory).
After the download authorization is approved, we can use the following commands to download the following three models according to your needs:
# 本地需要按照 Git LFS,https://git-lfs.com
# 安装完毕,进行初始化
git lfs install
# 下载 7B 模型
git clone https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
# 下载 13B 模型
git clone https://huggingface.co/meta-llama/Llama-2-13b-chat-hf
# 下载 70B 模型
git clone https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
After waiting for the model we selected to download, adjust the directory structure:
# 创建一个新的目录,用于存放我们的模型
mkdir meta-llama
# 将下载好的模型移动到目录中
mv Llama-2-7b-chat-hf meta-llama/
mv Llama-2-13b-chat-hf meta-llama/
mv Llama-2-70b-chat-hf meta-llama/
The complete directory structure looks like this, with all the models in meta-llamaone level below the directory we created:
# tree -L 2 meta-llama
meta-llama
├── Llama-2-13b-chat-hf
│ ├── added_tokens.json
│ ├── config.json
│ ├── generation_config.json
│ ├── LICENSE.txt
│ ├── model-00001-of-00003.safetensors
│ ├── model-00002-of-00003.safetensors
│ ├── model-00003-of-00003.safetensors
│ ├── model.safetensors.index.json
│ ├── pytorch_model-00001-of-00003.bin
│ ├── pytorch_model-00002-of-00003.bin
│ ├── pytorch_model-00003-of-00003.bin
│ ├── pytorch_model.bin.index.json
│ ├── README.md
│ ├── Responsible-Use-Guide.pdf
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ ├── tokenizer.model
│ └── USE_POLICY.md
└── Llama-2-7b-chat-hf
├── added_tokens.json
├── config.json
├── generation_config.json
├── LICENSE.txt
├── model-00001-of-00002.safetensors
├── model-00002-of-00002.safetensors
├── model.safetensors.index.json
├── models--meta-llama--Llama-2-7b-chat-hf
├── pytorch_model-00001-of-00003.bin
├── pytorch_model-00002-of-00003.bin
├── pytorch_model-00003-of-00003.bin
├── pytorch_model.bin.index.json
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
├── tokenizer.model
└── USE_POLICY.md
After the above content is ready, we start preparing to run the model.
Start the model application
Download the Docker LLaMA2 Chat model application file using the following command :
git clone https://github.com/soulteary/docker-llama2-chat.git
After waiting for the program to be downloaded, we enter the program directory and start building the model container image we need:
# 进入程序目录
cd docker-llama2-chat
# 构建 7B 镜像
bash scripts/make-7b.sh
# 或者,构建 13B 镜像
bash scripts/make-13b.sh
After waiting patiently for the image to be built, we move the previously prepared meta-llamadirectory storing the model to the current program directory, and then select the model program to start:
# 运行 7B 镜像,应用程序
bash scripts/run-7b.sh
# 或者,运行 13B 镜像,应用程序
bash scripts/run-13b.sh
After the command is executed, if all goes well, you will see a log similar to the following:
=============
== PyTorch ==
=============
NVIDIA Release 23.06 (build 63009835)
PyTorch Version 2.1.0a0+4136153
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
WARNING: CUDA Minor Version Compatibility mode ENABLED.
Using driver version 525.105.17 which has support for CUDA 12.0. This container
was built with CUDA 12.1 and will be run in Minor Version Compatibility mode.
CUDA Forward Compatibility is preferred over Minor Version Compatibility for use
with this container but was unavailable:
[[Forward compatibility was attempted on non supported HW (CUDA_ERROR_COMPAT_NOT_SUPPORTED_ON_DEVICE) cuInit()=804]]
See https://docs.nvidia.com/deploy/cuda-compatibility/ for details.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:05<00:00, 2.52s/it]
Caching examples at: '/app/gradio_cached_examples/20'
Caching example 1/5
/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1270: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
warnings.warn(
Caching example 2/5
Caching example 3/5
Caching example 4/5
Caching example 5/5
Caching complete
/usr/local/lib/python3.10/dist-packages/gradio/utils.py:839: UserWarning: Expected 7 arguments for function <function generate at 0x7f3e096a1000>, received 6.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/gradio/utils.py:843: UserWarning: Expected at least 7 arguments for function <function generate at 0x7f3e096a1000>, received 6.
warnings.warn(
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
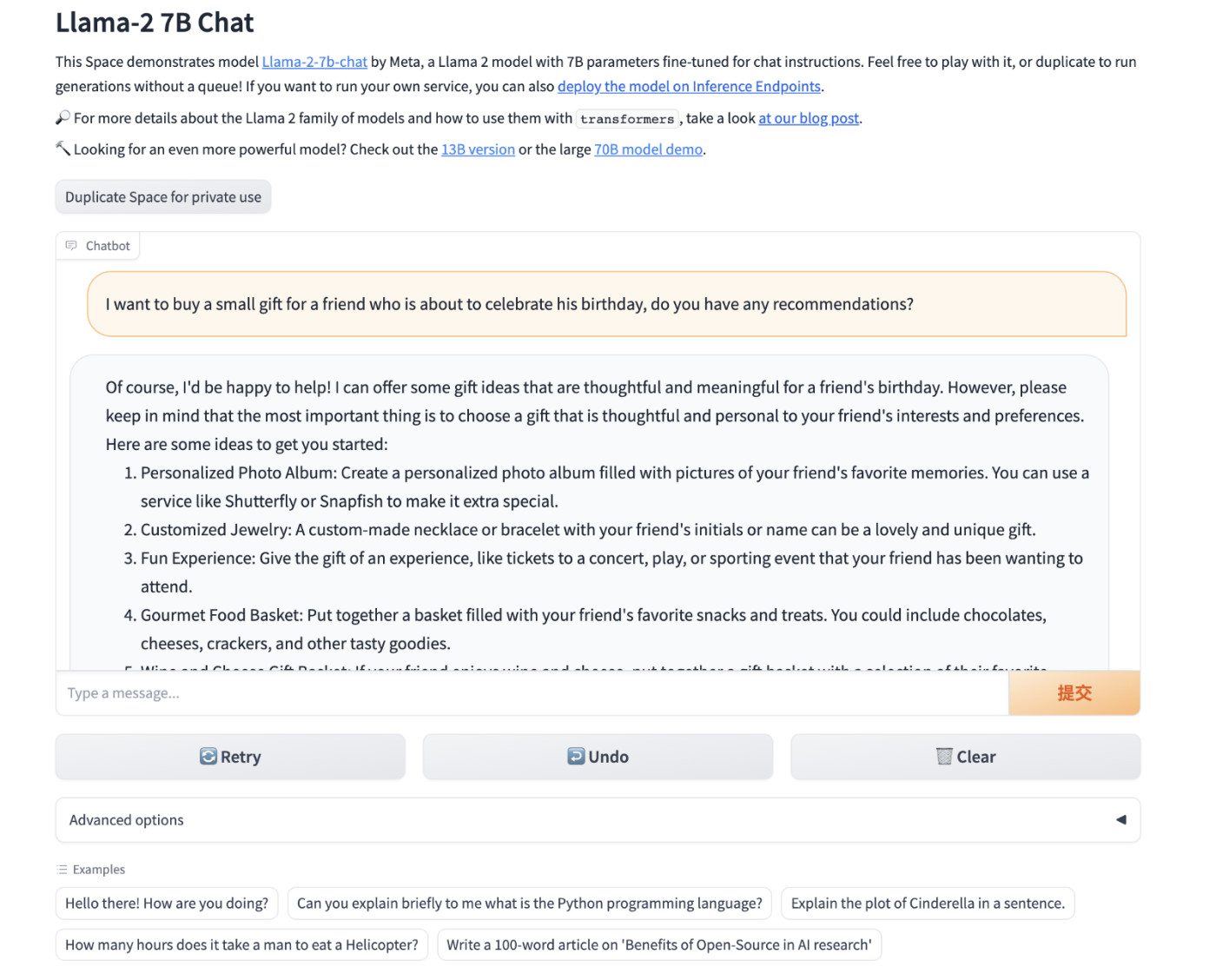
Then, we use the browser to open http://localhost:7860or http://你的IP:7860to start experiencing the LLaMA2 Chat model.
memory usage
When the 7B model actually runs, it will take up about 13 G of video memory.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | Off |
| 31% 42C P8 34W / 450W | 14158MiB / 24564MiB | 2% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1414 G /usr/lib/xorg/Xorg 103MiB |
| 0 N/A N/A 1593 G /usr/bin/gnome-shell 16MiB |
| 0 N/A N/A 2772 C python 14034MiB |
+-----------------------------------------------------------------------------+
The 13B model runs and consumes about 9G of video memory.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 44C P2 70W / 450W | 9057MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1414 G /usr/lib/xorg/Xorg 167MiB |
| 0 N/A N/A 1593 G /usr/bin/gnome-shell 16MiB |
| 0 N/A N/A 4686 C python 8870MiB |
+-----------------------------------------------------------------------------+
Well, if you just want to understand how to use the model, then this is enough.
Encapsulation of model images
Next, let's briefly expand what work has been done in the above script.
Encapsulating this LLaMA2 Docker image is actually very simple. It is no different from the previous model-related articles. Based on the Nvidia base image , we can do a simple multi-stage build.
For example, we can first define a base image that contains all the dependent files required for the model program to run:
ROM nvcr.io/nvidia/pytorch:23.06-py3
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && \
pip install accelerate==0.21.0 bitsandbytes==0.40.2 gradio==3.37.0 protobuf==3.20.3 scipy==1.11.1 sentencepiece==0.1.99 transformers==4.31.0
WORKDIR /app
Then, we save the above content as Dockerfile.base, and then use docker build -t soulteary/llama2:base . -f docker/Dockerfile.baseto build the base image.
Next, we just need to prepare the model calling file. I uploaded the relevant programs to soulteary/docker-llama2-chat/llama2-7b and soulteary/docker-llama2-chat/llama2-13b . There are two main files, namely the Gradio web interface and the model loading and running program.
Write the model application image file:
FROM soulteary/llama2:base
COPY llama2-7b/* ./
CMD ["python", "app.py"]
After saving the above file as Dockerfile.7b, I will use the command docker build -t soulteary/llama2:7b . -f docker/Dockerfile.7bto complete the construction of the application image.
Finally, use the following command to run the program and play:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/meta-llama:/app/meta-llama -p 7860:7860 soulteary/llama2:7b
at last
This article is the first article related to LLaMA2. In just a few months, open source projects can make such rapid progress, which is quite gratifying and exciting.
LLaMA2 is not the end, but the beginning of a new round. In the open source world, we can always expect stronger guys to emerge, constantly advancing and challenging the current king of the world.
The title of this article hides clues to the next article, can you guess it?
–EOF
This article uses the "Signature 4.0 International (CC BY 4.0)" license agreement. You are welcome to reprint or re-use it, but you need to indicate the source. Attribution 4.0 International (CC BY 4.0)
Author of this article: Su Yang
Creation time: July 21, 2023
Word count: 10092 words
Reading time: 21 minutes to read
This article link: https://soulteary.com/2023/07/21/use-docker-to-quickly-get-started-with-the-official-version-of-llama2-open-source-large-model.html