Elasticsearch is a key tool for enabling a seamless search experience for users. It has revolutionized the way users interact with applications by providing fast, accurate and relevant search results. However, ensuring optimal performance of your Elasticsearch deployment requires attention to key metrics and optimization of various components such as indexing, caching, querying, searching, and storage.
In this blog post, we'll dive into best practices and tips on how to tune Elasticsearch for optimal performance and maximum potential, from optimizing cluster health, search performance, and indexing, to mastering caching strategies and storage options. Whether you're an experienced Elasticsearch expert or new to the field, it's critical to follow some best practices to ensure performance, reliability, and scalability of your deployment.

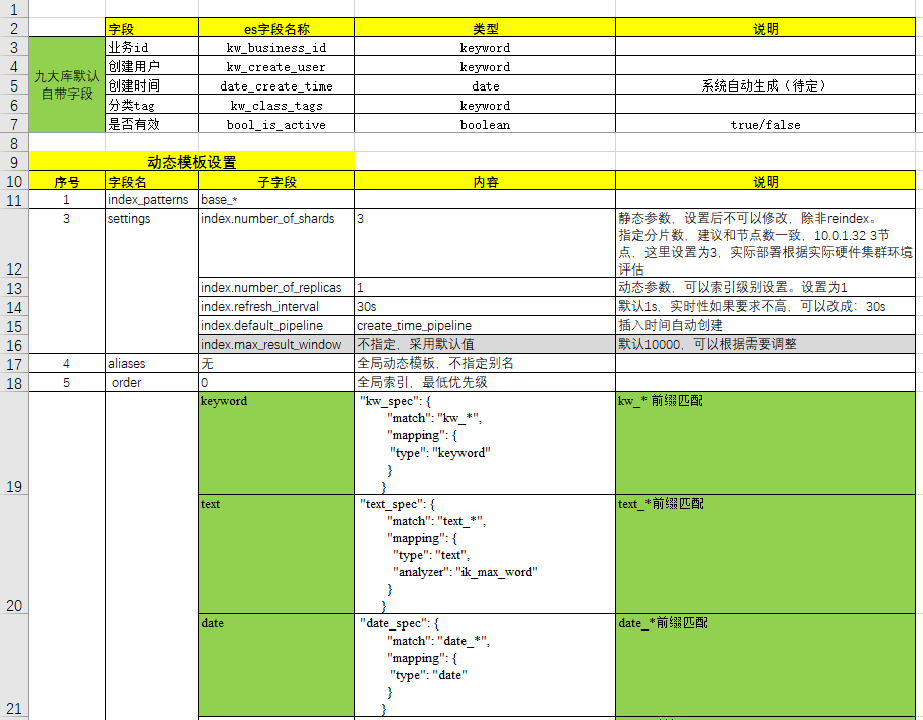
1. General optimization suggestions
1.1 Use the right hardware
Elasticsearch is a memory-intensive application, so it's important to use hardware with enough memory. Also, solid-state drives (SSDs) are recommended as storage devices, as they can significantly improve indexing and search performance.
Although the I/O performance of SSDs is better than that of traditional hard drives, I/O performance can still become a bottleneck if the number of nodes in the Elasticsearch cluster is large. In order to ensure performance, some optimization measures can be taken, such as using RAID configuration, reasonable disk partitioning and load balancing.
| RAID level | advantage | shortcoming | Applicable scene |
|---|---|---|---|
| RAID 0 | High I/O performance, realize parallel reading and writing | No redundancy, disk failure can result in data loss | Performance-sensitive applications with acceptable data recovery times |
| RAID 1 | Data redundancy, data will not be lost in case of disk failure | Write performance is not as good as RAID 0 | Applications with high data security and reliability |
| RAID 5 | Data redundancy, a certain degree of I/O performance advantage | Write performance is not as good as RAID 0 | Applications that require a balance between performance and data security |
| RAID 10 | Combining the advantages of RAID 0 and RAID 1, high I/O performance and data redundancy | Requires more disks and costs more | Applications that require both performance and data security |
1.2 Planning index strategy
Elasticsearch is designed to handle large amounts of data, but needs to consider how to index this data. This includes how many shards and replicas are needed, how the data will be indexed, and how updates and deletes will be handled.
Number of fragments
Choose an appropriate number of shards to achieve horizontal scaling and load balancing.
By default, each index has 1 primary shard. Adjust the number of shards according to the amount of data and the number of nodes. Try to avoid using too many shards, as each shard requires additional resources and overhead.
number of copies
Increase the number of copies to improve search performance and system fault tolerance, but it must be dialectical, which will be explained in detail later.
By default, each shard has 1 replica. Adjust the number of replicas based on load and availability needs.
Data Indexing Strategy
Use time-based index lifecycle management strategies (ILM) to improve query performance and reduce resource consumption. For example, create a new index for daily, weekly, or monthly data.
Choose the appropriate field type and analyzer. Optimize mappings to reduce storage space and improve query performance.
Use Index Templates to automatically apply mappings and settings.
Update and delete handling
Use the Update API to update documents without deleting and re-indexing the entire document.
Make reasonable use of Elasticsearch's version control features.
Consider using Index Lifecycle Management (ILM) to automatically manage the lifecycle of your indexes. According to specific business needs and scenarios, flexibly adjust the above suggestions to optimize the performance of the Elasticsearch cluster.
1.3 Optimizing queries
Elasticsearch is a powerful search engine, but make sure query performance is optimized. This includes using filters instead of queries where possible, and using pagination to limit the number of returned results.

Use filters instead of queries :
Improved query speed: Filters do not calculate relevance scores.
The results can be cached: get the results directly with the same filter conditions.
Use pagination to limit the number of returned results :
Reduce computational and transfer burden: improve query performance.
Note that deep pagination may cause performance issues: consider using
search_afterthe parameter.
Optimizing query performance can help reduce response times, increase throughput, and ensure that the cluster remains stable under high load.
1.4 Keep Elasticsearch version updated
Elasticsearch is an active project, and new versions are released regularly to fix bugs and provide new features. It is critical to keep the version updated to take advantage of these improvements and avoid known issues.
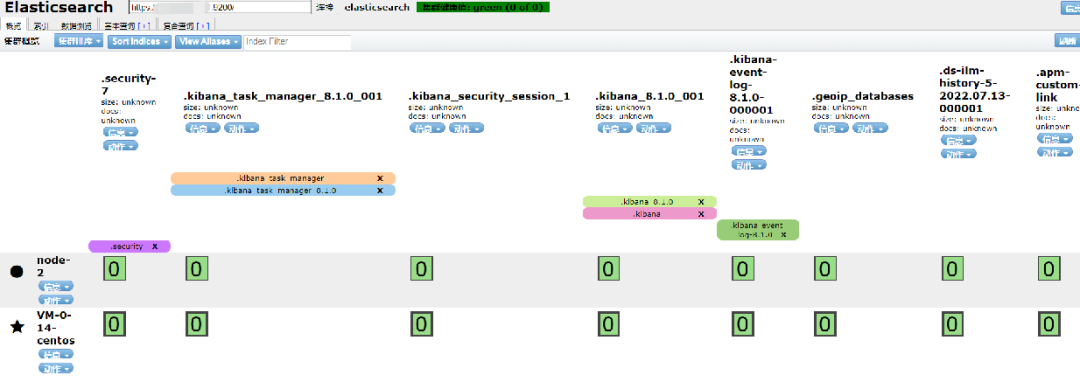
1.5 Monitoring Cluster
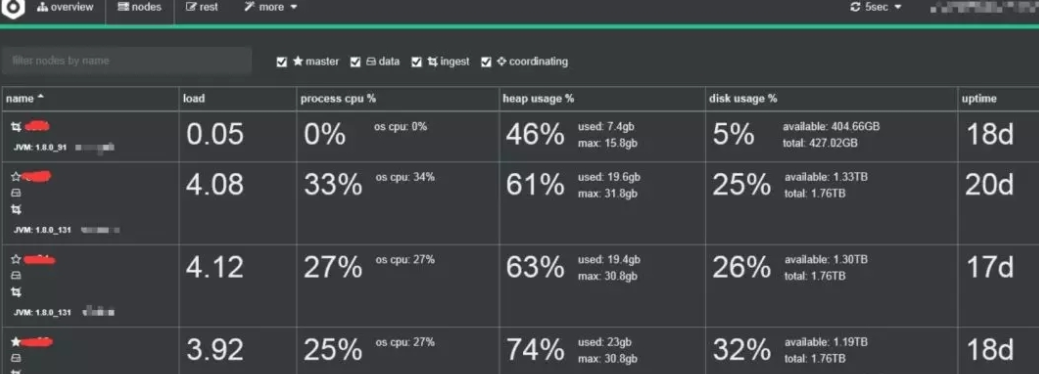
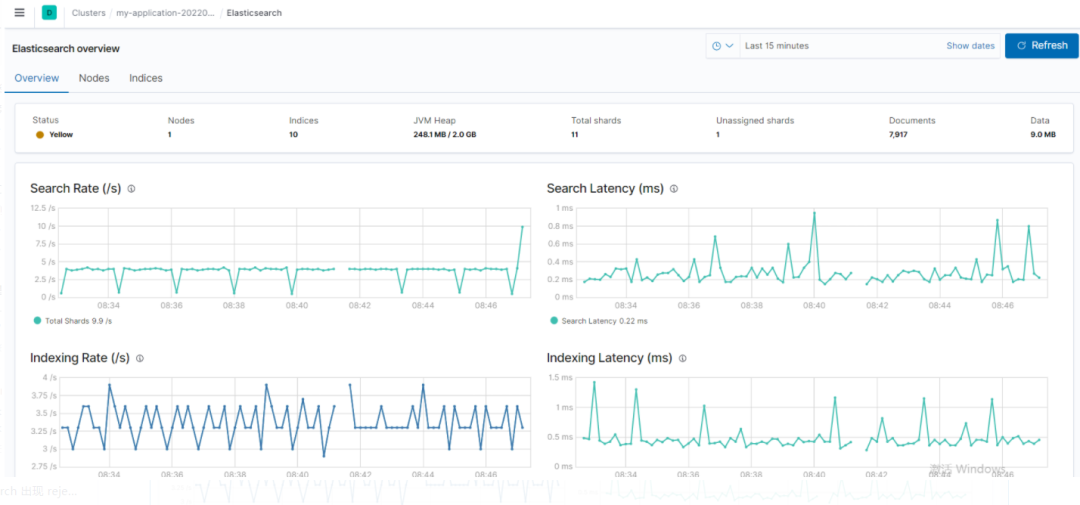
Elasticsearch provides a variety of monitoring tools , such as Elasticsearch Head, Kibana monitoring (preferred) plug-ins, which can be used to monitor the health and performance of the cluster. Keep an eye on disk usage, CPU and memory usage, and the number of search requests.
Building on general best practices, we'll dive into specific areas such as indexing, querying and searching, scaling, performance, and monitoring.
2. Writing (indexing) optimization suggestions
2.1 Using batch requests
Elasticsearch's bulk API allows multiple index/delete operations to be performed in a single API call. This greatly improves indexing speed. If one of the requests fails, the top-level error flag will be set to true and error details will be reported under the relevant request.
Reasons to use Elasticsearch's bulk API :
improve performance
Reduce network overhead and connection establishment time, improve indexing speed.
Reduce resource consumption
Reduce server and client resource consumption, improve system efficiency and throughput.
error handling
Flexible and controllable error handling, even if some operations fail, other operations can continue to execute.
Using the bulk API enables efficient data indexing and deletion operations while improving system stability and reliability.
2.2 Index data using a multi-threaded client
Sending batch requests by a single thread cannot take full advantage of the indexing capabilities of the Elasticsearch cluster.
Sending data through multiple threads or processes will help to utilize all resources of the cluster, reduce the cost of each fsync, and improve performance.
2.3 Increase the refresh interval (index.refresh_interval)
The default refresh interval in Elasticsearch is 1 second, but if search traffic is low, this value can be increased to optimize indexing speed.
2.4 Using auto-generated IDs
When indexing a document with an explicit ID, Elasticsearch needs to check whether a document with the same ID already exists, which is an expensive operation.
Using auto-generated IDs can skip this check, making indexing faster.
2.5 index.translog.sync_interval
This setting controls when the translog is committed to disk, regardless of write operations. The default is 5 seconds, but values smaller than 100 milliseconds are not allowed.
Official document address:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
2.6 Avoid large documents
Large documents can put pressure on the network, memory usage, and disk, causing slow indexing and affecting proximity searches and highlighting.
Highlight processing recommends the fvh highlighting method.
2.7 Setting Mappings Explicitly
Elasticsearch can dynamically create mappings, but it is not suitable for all scenarios. Setting the (strict) mapping explicitly will help ensure optimal performance.

Advantages of setting the mapping explicitly :
exact field type
Ensure query and aggregation operations are correct.
Optimize storage and performance
Reduce storage space and improve query performance.
Avoid unnecessary map updates
Reduce map update operations and performance overhead.
2.8 Avoid using nested Nested types
While nested types are useful in certain scenarios, they also come with a certain performance impact:
Query is slower
Querying nested fields is slower than querying normal fields in non-nested documents.
This is because queries on nested fields require additional processing steps such as filters and joins. This can lead to lower query performance, especially when dealing with large amounts of data.
additional deceleration
When retrieving documents matching nested fields, Elasticsearch needs to associate nested documents. This means it needs to match nested documents with their outer documents to determine which documents actually contain matching nested fields. This process can cause additional performance overhead, especially if the query result set is large.
To avoid the performance impact of nested types, consider using the following methods:
Flattened data structure (commonly known as a large and wide table): convert nested fields into a flattened data structure as much as possible, for example, use multiple common fields to represent the original nested fields.
Use keyword type (keyword type): For fields with fixed set values, you can use keyword type for indexing to improve query speed.
Use join type (parent-child association type): In some scenarios, you can use join type instead of nested type.
Note, however, that join types can also cause performance issues, especially if document relationships need to be modified frequently.
3. Query and search optimization suggestions
3.1 Use filter instead of query as much as possible
The query clause is used to answer "How well does this document match this clause?
The filter clause is used to answer "Does this document match this clause?" Elasticsearch only needs to answer "yes" or "no". It does not need to compute relevance scores for filter clauses, and filter results can be cached.
3.2 Increase refresh interval
Increasing the refresh interval can help reduce the number of segments and reduce the IO cost of searching.
Also, once a refresh happens and the data changes, the cache is invalidated. Increasing the refresh interval allows Elasticsearch to utilize the cache more efficiently.
3.3 A dialectical look at the impact of increasing the number of copies on retrieval performance
Directly give the enterprise-level test conclusion - the impact of the number of copies on retrieval performance is not positively correlated. That is to say: it is not that the more copies, the higher the retrieval performance.
Advantages of increasing the number of replicas :
load balancing
Distribute query request load to achieve load balancing.
high availability
Improve cluster availability and fault tolerance.
parallel processing
Accelerate queries and increase throughput.
Note: Increasing the number of replicas consumes additional storage space and computing resources. The number of replicas needs to be weighed against demand and resource constraints.
3.4 Retrieve only necessary fields
If the document is large and only a few fields are needed, use stored_fields to retrieve only the required fields, not all fields.
3.5 Avoid wildcard queries
Wildcard queries can be slow and resource-intensive. It's best to avoid them as much as possible.
Alternatives: Ngram word segmentation, setting wildcard data type.
3.6 Using Node Query Cache
Query results used in the filter context will be cached in the node query cache for fast lookups.
Advantages of filter context query result caching :
cache hit ratio
Filter queries have a high cache hit ratio and are often reused in multiple queries.
save computing resources
Caching results reduces repeated calculations and saves resources.
Improve query speed
Caching speeds up queries, especially complex or data-heavy filter queries.
Concurrent query works better
Node query cache plays a role in high concurrency scenarios to improve performance.
Note: There is a balance between cache usage and memory consumption. For queries that change frequently or have low cache hit ratios, caching may be of limited effectiveness.
3.7 Using Sharded Query Cache
Sharded query caching can be enabled by setting "index.requests.cache.enable" to true.
The setting reference is as follows:
PUT /my-index-000001
{
"settings": {
"index.requests.cache.enable": false
}
}Official document address:
https://www.elastic.co/guide/en/elasticsearch/reference/current/shard-request-cache.html
3.8 Using index templates
Index templates can help automatically apply settings and mappings to new indexes.
Advantages of using index templates :
consistency
Make sure the new index has the same settings and mappings for cluster consistency.
Simplify operation
Automatically apply predefined settings and mappings, reducing manual configuration.
easy to expand
Quickly create new indexes with the same configuration for easy cluster scaling.
Version Control and Updates
Implement template versioning to ensure new indexes use the latest configuration.
4. Suggestions for performance optimization
4.1 Active sharding should be proportional to CPU
Active shards = sum of primary shards + replica shards.
Reasons for active shards proportional to CPU :
parallel processing
More active shards increase parallel processing, speeding up query and indexing requests. Proportional to the number of CPU cores to ensure full utilization of CPU resources.
avoid resource competition
Proportionate active shards to the number of CPU cores to avoid multiple shards competing for the same CPU core and improve performance.
load balancing
A proportional number of active shards helps spread requests across multiple nodes, avoiding resource bottlenecks on a single node.
performance optimization
The number of shards proportional to the number of CPU cores allocates processing power to shards according to available computing resources, optimizing query and indexing operations.
Note: The actual deployment needs to consider other factors, such as memory, disk and network resources.
As mentioned earlier, to improve performance for write-intensive use cases, the refresh interval should be increased to a large value (for example, 30 seconds), and primary shards should be increased to distribute write requests to different nodes. For read-intensive use cases, increasing replica shards to balance query/search requests across replicas can help.
4.2 If the query has a date range filter, organize the data by date.
For logging or monitoring scenarios, organizing indexes by day, week, or month and getting a list of indexes by a specified date range can improve performance.

Elasticsearch only needs to query smaller datasets, not the entire dataset, and it would be easy to shrink/remove old indexes when data expires.
Negative case: Previously, there was a problem that the customer's data of more than 100TB did not have a date format field or the field format was not standardized.
4.3 If the query has a filter field and its value is enumerable, split the data into multiple indexes.
If our query includes an enumerable filter field (for example, region), query performance can be improved by splitting the data into multiple indexes.
For example, if the data contains records from the United States, Europe, and other regions, and queries are often filtered using "region", the data can be split into three indexes, each containing data for a set of regions.
This way, when executing a query with the filter clause "region", Elasticsearch only needs to search in the index that contains data for that region, improving query performance.
5. Suggestions for extension
5.1 Index Status Management
Define custom management policies to automate common tasks and apply them to indexes and index schemas. For example, you can define a policy that makes an index read-only after 30 days and deletes it after 90 days.
ILM (Index Lifecycle Management) is an Elasticsearch feature that automates the management and maintenance of indexes, with the following benefits:
Simplified index management: Automate index lifecycle management, including index creation, update, deletion, and archiving, reducing the burden on administrators.
Improve performance: Automatically optimize index settings, including adjusting the size of fragments, shrinking indexes, and deleting expired data, etc., to help improve query performance and reduce storage space usage.
Reduce costs: automatically archive and delete expired data, reduce storage costs, and reduce administrator workload and time costs.
Better scalability: Automatically adjust index settings and storage policies as needed, making indexes better adaptable to growing and changing data.
Using ILM can make index management simpler and more reliable.
5.2 Snapshot Lifecycle Management
SLM (Snapshot Lifecycle Management) is an Elasticsearch feature that automates the management and maintenance of snapshots, with the following benefits:
Simplified snapshot management: Automate the lifecycle management of snapshots, including creating, managing, deleting, and cleaning up snapshots, reducing the burden on administrators.
Improve efficiency: Create, manage, delete and clean up snapshots automatically to improve management efficiency.
Reduce storage costs: Automatically delete useless snapshots to reduce storage costs.
Better scalability: Automatically adjust snapshot settings and storage policies as needed, making snapshots better adaptable to growing and changing data.
Using SLM can make snapshot management easier and more reliable, improve management efficiency and reduce storage costs.
5.3 Make good use of monitoring
In order to monitor the performance of your Elasticsearch cluster and detect any potential issues, the following metrics should be tracked regularly:
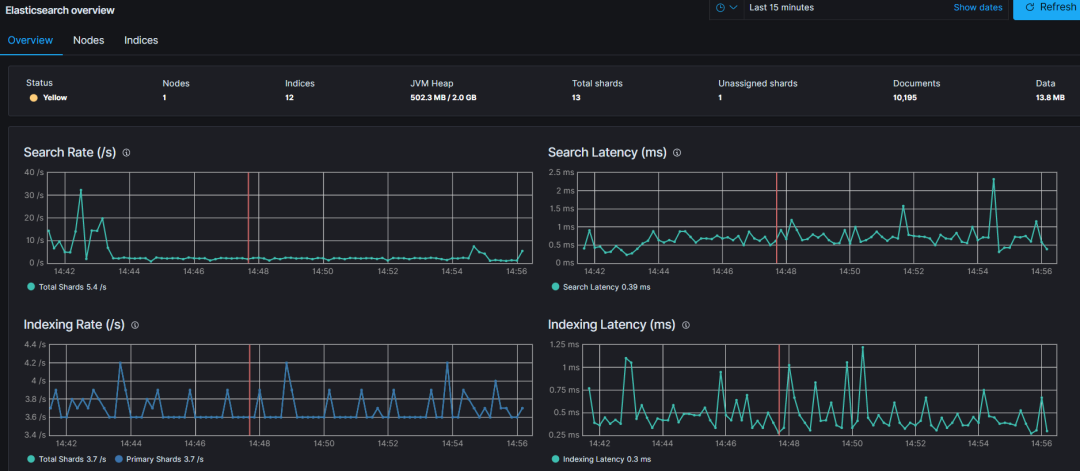
Cluster Health Nodes and Shards: Monitors the number of nodes in the cluster as well as the shards and their distribution.
Search Performance: Request Latency and Rate - Tracks the latency of search requests and the number of search requests per second.
Index Performance: Refresh Time and Merge Time - Monitor the time it takes to refresh the index and the time it takes to merge segments.
Node Utilization: Thread Pools - Monitors the usage of thread pools on each node, such as the index pool.
6. Summary
Following these best practices can ensure a performant, reliable, and scalable Elasticsearch deployment.
Remember that Elasticsearch is a powerful search and analytics engine that can process large amounts of data quickly and in near real time, but getting the most out of it requires planning, optimizing, and monitoring your deployment.
The above suggestions are for reference only. The actual operation is based on the official Elasticsearch documentation and the performance test conclusions of your own cluster. There is no universal optimization suggestion, only the optimization that suits you is the best optimization.
------
We have created a high-quality technical exchange group. When you are with excellent people, you will become excellent yourself. Hurry up and click to join the group and enjoy the joy of growing together. In addition, if you want to change jobs recently, I spent 2 weeks a year ago collecting a wave of face-to-face experience from big factories. If you plan to change jobs after the festival, you can click here to claim them !
recommended reading
··································
Hello, I am DD, a programmer. I have been developing a veteran driver for 10 years, MVP of Alibaba Cloud, TVP of Tencent Cloud. From general development to architect to partner. Along the way, my deepest feeling is that we must keep learning and pay attention to the frontier. As long as you can persevere, think more, complain less, and work hard, it will be easy to overtake on corners! So don't ask me if it's too late to do what I do now. If you are optimistic about something, you must persevere to see hope, not to persevere only when you see hope. Believe me, as long as you stick to it, you will be better than now! If you have no direction yet, you can follow me first, and I will often share some cutting-edge information here to help you accumulate capital for cornering and overtaking.