1. What are NoSql databases (memory databases, non-relational databases)?
1. redis
2. mongdb
3. memcache
4. tair (Taobao self-developed)
2. What is Redis?
1. Redis is completely open source and free, is a high performancekey-value database
2. Redis is based on single threadC languageWritten
3. Redis has no windows version, only the linux version
3. What is the difference between relational and non-relational databases?
Relational database: data is stored inhard disk
Yes , every time the data is read, it is io operation, and the efficiency is relatively low. Non-relational database: the data is put intoRAMThere are also some mechanisms for persistence operations
Four, Redis application scenarios:
1. Token generation! ! !
2. The cache query data can be realized, and the access pressure of the relational database can be reduced! ! !
3. Distributed lock! ! !
4. Delayed operation: For example, when an order is placed and payment is not made, the inventory is reduced. You can set a timeout period, and the inventory is increased after the timeout! ! !
具体例子,比如下单30分钟未支付自动更新订单状态
1、采用定时任务,30分钟后检查该笔订单是否已经支付(性能不好,不推荐)
2、根据key有效期时间回调实现(推荐)
实现
1、创建订单的时候绑定一个订单token(不用订单编号是因为不安全)存放在redis中(有效期只有30分钟)
2、token过期时执行回调方法判断订单状态
5. Distributed message middleware
6, log
7, code
8 for SMS verification code , implementation counter
5. Why does Redis only have a Linux version without a Windows version?
1. The underlying adoption of RedisIO multiplexing mechanism in Nio, Use one thread to maintain multiple Redis client connections, can be very goodSupport concurrency and ensure thread safety
2. In windowsselect selectorUse for loop, easy to poll empty, time complexity is O (n)
3. In linux, epoll is used to implement event-driven callback, there will be no empty rotation training, only active callback connection is implemented to achieve active callback The performance is greatly improved, so the time complexity is O (1)
6. What is the function of 16 (0 ~ 15) libraries in Redis?
The keys in different libraries can be the same, but the keys in the same library cannot be the same
7. Will Redis memory be full?
Redis does not set the upper limit of memory by default. Generally, it is the size of the available memory. It can also be configured, maxmemory. When the data reaches the limited size, it will choose the configuration strategy to eliminate the data
.
8. What data types are there in Redis?
1. String (string type): can store up to 512MB
2. Hash: a set of key-value (key => value) pairs
3. List (list): simple list of strings, sorted in order of insertion . You can add an element to the head (left side) or tail (right side) of the list
4. Set (set): the set is implemented through a hash table, so the complexity of adding, deleting, and searching are all O (1)
5 , Zset (sorted set: ordered set): as set is also a collection of string type elements, and does not allow duplicate members
9. What are the ways Redis stores objects?
1. UsejsonThe serialization and deserialization of the
advantages: intuitive, visual, cross-language
Disadvantages: occupying memory, unsafe
2, use the serialization method of redis (serialization intoBinary), The entity class must implement a serialized interface.
Advantages: security, binary comparison does not occupy memory.
Disadvantages: invisible, binary cannot be cross-language, can only be converted into java objects, can not be converted into objects in other languages, json can be cross-language
10. What is the difference between full synchronization and incremental synchronization?
1. Full synchronization: It is a daily timing (avoiding high abandonment) or a cycle of implementation to copy data to another place.
The frequency is not very large, but it may cause data loss.
2. Incremental synchronization: Behavioral operation is used to synchronize the data, the frequency is very high, the pressure on the server synchronization is also very large, and the data is not lost.
11. What is the difference between RDF and AOF to achieve persistence?
1. AOF, based on data log operation to achieve persistence,Incremental synchronization,appendonly.aofFile
open aof: modify appendonly to yes in redis.conf in
three aof modes:
1. appendonly always: write when there is data change, more synchronization times, frequent io operations
2, appendonly everysecdefault):useBuffer zone,Per secondRegularly write from the buffer to the AOF file, there may be missing
3, appendonly no Never sync. Efficient but the data will not be persistent, whether to open AOF
2, RDB (default), Timing persistence mechanism ==, full synchronization ==, there is oneTemporary RDB filewithFinal RDB fileEach time it is persisted, a temporary RDB file is generated to overwrite the last RDB temporary file. After Redis is down, the temporary file becomes the final RDB file. After Redis is restored, the final dump.RDB file is used to restore it to memory When executed regularly, a fork subprocess will be launched to synchronize data to the hard disk. For example: after 90 seconds, determine whether the number of key changes exceeds 10 times, and persist if there are.
Note:If both aof and rdb are enabled, use aof first
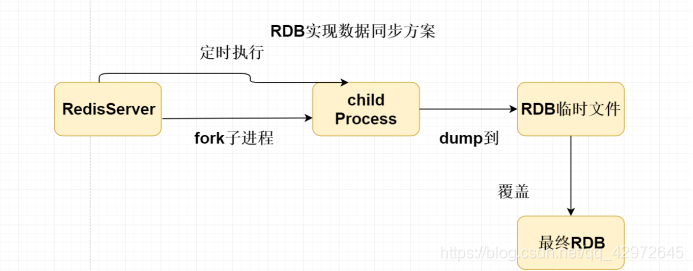
12. How does MySQL and Redis maintain data consistency?
1. DirectClear redis cache, Re-query
2. Direct usemq subscribe mysql binlog(Update, insert, and del operations are all recorded) The log files are incrementally synchronized to Redis
3. Use alibabacanal(The bottom layer is method two)
Thirteen, SpringBoot and Redis annotation versions
1. Add @EnableCache to the main class
2. Add @Cacheable to the method (cacheName = "category directory", key = "'is generally the method name, and single quotes must be added")
3. The object implements the serialization interface
14. Redis six major memory elimination strategies: when the memory space is full, the old data will be automatically expelled
1. noeviction (default): When the memory usage reaches the threshold, execute the command When the memory usage reaches the threshold, execute the command directlyReport an error
2. allkeys-lru: inallIn the key, priority removalNot used recentlyKey. (Recommended)
3. allkeys-random: inallIn the key,Random removalA key.
4. Volatile-lru: After settingexpire dateIn the key space ofRecently unused key.
5. Volatile-random: set inexpire dateIn the key space,randomRemove a key.
6, volatile-ttl: set inexpire dateIn the key space ofExpire earlierTime key is removed first.
15. Transactions in Redis
Redis transaction operation: There is no rollback in Redis, but there is a cancel commit transaction
Multi: open the transaction, put the key and value into the queue, keep it atomic
EXEC: commit the transaction
Discard: cancel the commit transaction
Watch: you can monitor one or more key, whether there has been a change before committing the transaction. If there is an edge change, the transaction will not be submitted, and the transaction can only be submitted if there is no change.
watch name //启动监听
multi //开启事务
set name xiaoxiao //添加key-value
exec //提交事务
16. What are the differences between transactions in Redis and Mysql?
Redis transactions are not isolated. At the same time, they operate on the same data without locks. Whoever submits the data last is what kind of
Mysql transaction has isolation.
17. What is the difference between canceling a transaction and rolling back a transaction?
Roll back the transaction: cancel the transaction and release the row lock
Cancel the transaction: simply cancel the transaction
18. What is a distributed lock? Give a scene
Local lock: In multiple threads, only one thread is guaranteed to execute (thread safety issue)
Distributed lock: In distributed, only one jvm is guaranteed to execute (multiple jvm thread safety issues). For
example, each jar in the cluster is Similarly, there is a scheduled task in the jar package. Multiple jars will repeatedly execute this scheduled task. At this time, distributed locks can be used to solve the problem of repetitive task scheduling.
Nineteenth, to solve the core ideas of distributed locks:
1. Acquire the lock: multiple different JVMs create a tag (a globally unique tag) at the same time, whoever can create a successful one will acquire the lock
2. Release the lock: release the globally unique tag, and other JVMs will re-enter to acquire the lock resource
3. Overtime lock: decide how to deal with it according to the timeout strategy
#### Twenty. Three ways to implement distributed locks:
1. Database-based approach: whoever gets the row lock first, who will acquire the distributed lock
2. Zk-based approach: Temporary node + event notification
3. Redis implementation: Use the setnx command to create a key, and whoever successfully creates the key first will get the distributed lock.
4. Use a framework. For example, Redis official website has a redis framework to solve the distributed lock redission
set:如果key不存在则创建,存在则修改原值
setnx:如果key不存在则创建,返回1,存在则不执行任何操作,返回0。
Twenty-one, the advantages and disadvantages of Redis and zk to achieve distributed locks?
Acquiring locks: almost
releasing locks: almost
timeout locks: zk uses session timeout, which is less efficient, closes the current Session connection, automatically deletes the current zk node path, and other threads re-enter the lock acquisition phase. Redis key automatically releases the lock when it expires
22. What if the business logic has not reached the timeout?
Method 1: Determine the approximate time according to the business logic you wrote and set the key timeout time
Method 2: Check whether the lock has timed out when submitting the transaction, if it has timed out, roll back, otherwise submit (recommended)
23. Application scenarios of distributed locks?
1. The distributed task scheduling platform guarantees the idempotency of the tasks
2. The generation of distributed global ids
24. Three ways to achieve high availability in Redis cluster?
1. Traditional master-slave replication
2. Master-slave replication + sentinel mechanism
3. Sharded cluster
25. Redis master-slave replication principle
1. From redis.conf: slaveof points to the master ip and port number and the password of the master service
2. After startup, the master and slave establish a long socket connection
3. Use the full amount (send binary dump.rdb file instead of aof) The data is synchronized to the slave redis server in the form of AOF. When the slave node starts for the first time, the master node synchronizes the data in the form of a full amount. After that, the master write data is incremental.
4. The network has problems, and the slave node connects to the master again. Node, the master node reissues the missing data, each time the data increments are synchronized
主master:做读写操作
从slaveof:只读,把写操作交给主节点
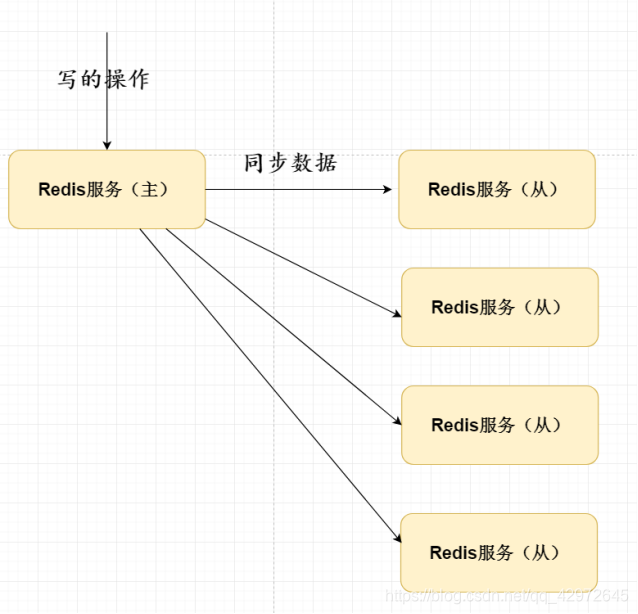
Twenty-six, what problems exist in the traditional one-master multi-slave?
1. If there is a problem with the master node, the entire Redis environment cannot
perform write operations. It is necessary to manually change the configuration to become the master operation. How to solve this problem: Using the sentry mechanism can help solve the Redis cluster master-slave election strategy.
2. There are many synchronized servers and low efficiency, so the tree form is used
27. What is the role of the Redis sentry mechanism?
The Redis sentinel mechanism is to solve the defects of our master-slave replication (election problem), solve the problem to ensure that our Redis is highly available, and realize automationFault findingversusFailover。
28. The principle of sentinel mechanism
1. The sentinel mechanism can obtain the current environment list of the entire Redis cluster (the entire node structure) every 10s, using the form of info replication command. Just configure to listen to our master node.
2. Multiple sentries listen to the same master node, subscribe to the same channel, and when new sentries join, they will send information about their services to the channel. Subscribers of the channel can find the new sentries and join each other. Long connection. Redis itself has a channel. The sentinel subscribes to the same channel and clusters.
3. The failure of the Master finds that a single sentry will send a ping command to the master master node. If the master node does not respond in time, the sentry will consider the master node to be "subjective. "Use Status" will be sent to other sentries to confirm whether the Master node is unavailable. The number of currently confirmed sentinel nodes> = quorum (configurable) will achieve re-election
29. Why should the number of sentinel clusters be the same as the number of Redis slave nodes?
To ensure the fairness of the elections, the sentry only conducts elections, not master-slave replication
30. What are the problems with the traditional sentinel mechanism?
Redis sentry cluster mode, each node saves a full amount of synchronized data,There is more redundant data; And used in the cluster in the Redis Cluster modelSharded clusterMode canReduce redundant data, The disadvantage is to build the cluster modelVery high cost,
31. Redis sharding cluster
Redis3.0 officially launched the cluster mode RedisCluster, the principle adopts the concept of hash slot, pre-allocated16384Card slots, and assign the card slot to the specific service node; by key == crc16 (key)% 16384 == get the remainder, the remainder is the position of the corresponding card slot, a card slot can store multiple different key to forward the read or write to the service node of the card slot. The biggest point: dynamic expansion and reduction.
Redis5.0 distribution card slot is more convenient, 3 and 4 distribution is very troublesome, you need to install the plug-in
/usr/redis/bin/redis-cli --cluster create 192.168.212.163:7000 192.168.212.163:7001
192.168.212.163:7002 192.168.212.163:7003 192.168.212.163:7004 192.168.212.163:7005
--cluster-replicas 1
1 means that the ratio is 1, the first three are dominant, and the last three are slaves. By default, there is no forwarding function. Add -c after this command to represent the cluster, and there will be forwarding. The forwarding is that the key you access is not in this one. Redis can forward you to other redis, only the master node has a card slot, the slave node does not
32. Expansion and reduction of Redis sharded clusters
It will be allocated on the nodes specified during the expansion, and the
reduction will be evenly distributed to each node.
33. Redis security related content: great pressure on the database
1. Cache penetration: access keys that do not exist in redis, bypass redis to directly access the database, and frequent high concurrent queries cause the cache to be useless.
Solutions:
1. The interface implements API current limiting, defends against ddos, and the interface frequency limit
2. When no data can be queried from the database and redis, write the null value of the database to the cache, plus a short period of validity (only suitable for a single key, it will affect normal use, not recommended)
3, Bloom filter
2. Cache breakdown: access hotspot key under high concurrency, the hotspot key expires suddenly, all requests directly access the database
Solution:
1. Use distributed lock to solve, lock the query database, suitable for server cluster, let One of the query data to the cache, the other directly read the cache
2, the local lock is the same as the distributed lock
3, soft expiration, set an unlimited validity period for the hotspot key, get asynchronous extension time
3, cache avalanche: almost the same as cache breakdown Multiple hotspot keys fail at the same time, or redis restarts and there is no persistence
solution:
clustering to allocate deployment keys
34. Solve the problem of cache penetration based on Bloom filter
Bloom filter: The public data structure algorithm is not unique to redis. It is suitable for determining whether an element exists in the set, but there may be a problem of misjudgment. The probability is very very low. The default probability of 3 is misjudged. The lower the probability of misjudgement, the longer the length of the array. How appropriate is the setting? Depends on the project
Warm-up mechanism: In the production environment, the hotspot key should be cached in redis in advance. Use the Bloom filter to put the data in the redis cache first. When querying the redis cache, check from the Bloom filter. It means there is no redis cache
The cache breakdown is solved by using the Bloom filter:
1. Warm up: put the data in the database into the Bloom
2. Query the Bloom filter. If it does not exist in the Bloom, it means that there is no such key in the database.
3. Query redis
4. If it does not exist in redis, then query the database.
Misjudgment:
query id = 66, it exists in the Bloom filter (in fact, it should not exist), and it does not exist in redis before querying the database.
================================================== ========================
Neither redis key nor value can be null
jedis, a tool for connecting redis to java client, the cluster is not supported by default, the default is not Support redirection
Question: There is no strong consistency in the distribution, only the final consistency. Isn't zk strong consistency?
The multi-level cache is implemented in decorative mode
Most cache frameworks will have the basic functions of elimination strategy (Redis memory slow elimination strategy, first-in first-out), persistence mechanism, and EhCache has no persistence mechanism
Use Redis Key automatic expiration mechanism
When our key is invalid, we can execute our client callback callback method.
Need to be configured in Redis:
notify-keyspace-events "Ex"
Version number optimistic lock
Value uses uuid to determine whether it is its own thread
Redis distributed locks are implemented differently in standalone and clustered versions
How to know whether the current node is the master node?
Via command: info replication
How does the sentry elect the master node?
What should I do if the redis slave node is down?
Sentinel for small projects, cluser for large projects
