Quickly understand Open Graph Benchmark in 10 minutes
Open Graph Benchmark (OGB)
Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. The dataset covers various graph machine learning tasks and real-world applications. The OGB data loader is fully compatible with popular graph deep learning frameworks, including PyTorch Geometric and Deep Graph Library (DGL). They provide automatic dataset downloads, standardized dataset splits, and unified performance evaluation.

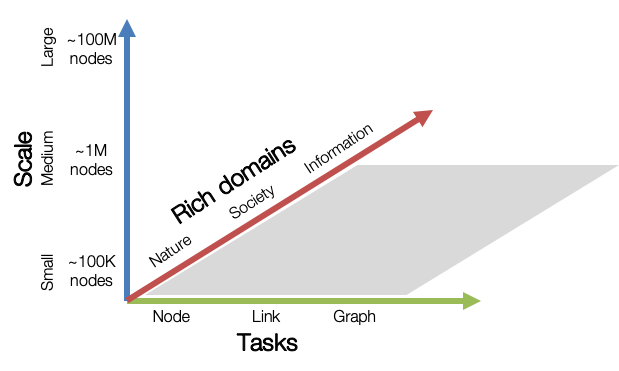
OGB aims to provide graph datasets covering important graph machine learning tasks, different dataset scales, and rich domains.
- Graph ML Tasks : Covers three basic graph machine learning tasks: node, link, and graph-level predictions.
- Variety of scale : Small graph datasets can be processed within a single GPU, while medium and large graphs may require multiple GPUs or clever sampling/partitioning techniques.
- Rich Domains : Graph datasets come from different domains from scientific networks to social/information networks, also including heterogeneous knowledge graphs.
Install OGB
It can be installed using the Python package manager pip.
pip install ogb
Check the version of ogb:
python -c "import ogb; print(ogb.__version__)"
# This should print "1.3.6". Otherwise, please update the version by
pip install -U ogb
Other related dependencies are:
- Python>=3.6
- PyTorch>=1.6
- DGL>=0.5.0 or torch-geometric>=2.0.2
- Numpy>=1.16.0
- pandas>=0.24.0
- urllib3>=1.24.0
- scikit-learn>=0.20.0
- outdated>=0.2.0
easy to use
Two key features of OGB are mainly emphasized, namely (1) an easy-to-use data loader and (2) a standardized estimator .
(1) Data loaders
OGB has easy-to-use PyTorch Geometric and DGL data loaders. Can handle dataset downloads as well as normalized dataset splits. The following example is data preparation and splitting datasets on PyTorch Geometric! Of course, it is also very convenient for DGL!
from ogb.graphproppred import PygGraphPropPredDataset
from torch_geometric.loader import DataLoader
# Download and process data at './dataset/ogbg_molhiv/'
dataset = PygGraphPropPredDataset(name = 'ogbg-molhiv')
split_idx = dataset.get_idx_split()
train_loader = DataLoader(dataset[split_idx['train']], batch_size=32, shuffle=True)
valid_loader = DataLoader(dataset[split_idx['valid']], batch_size=32, shuffle=False)
test_loader = DataLoader(dataset[split_idx['test']], batch_size=32, shuffle=False)
(2) Evaluators
OGB also prepares standardized evaluators to facilitate the evaluation and comparison of different methods. The evaluator takes input_dict(the evaluator.expected_input_formatdictionary of format specified in ) as input and returns a dictionary storing performance metrics applicable to the given dataset. A standardized evaluation protocol enables researchers to compare their methods reliably.
from ogb.graphproppred import Evaluator
evaluator = Evaluator(name = 'ogbg-molhiv')
# You can learn the input and output format specification of the evaluator as follows.
# print(evaluator.expected_input_format)
# print(evaluator.expected_output_format)
input_dict = {
'y_true': y_true, 'y_pred': y_pred}
result_dict = evaluator.eval(input_dict) # E.g., {'rocauc': 0.7321}
Node Classification Task Dataset
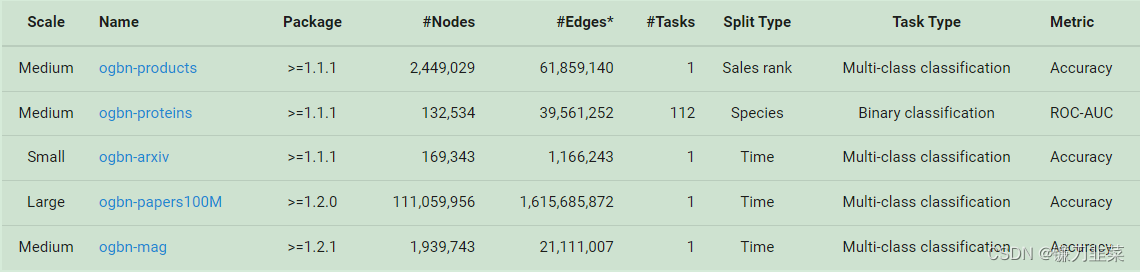
Note: For undirected graphs, the loaded graph will have double the number of edges, since OGB automatically adds bidirectional edges.
Link Prediction Task Dataset
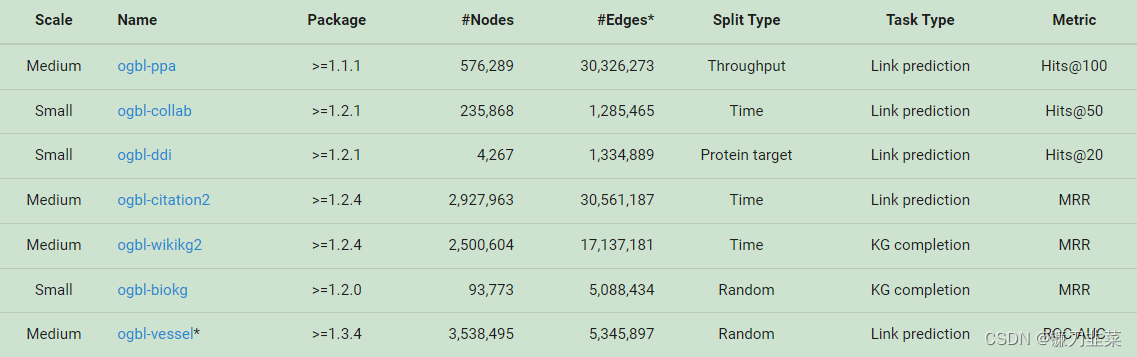
Note: For undirected graphs, the loaded graph will have double the number of edges, since OGB automatically adds bidirectional edges. *Denotes externally provided datasets.
Graph Attribute Prediction Task Dataset

Note: For undirected graphs, the loaded graph will have double the number of edges, since OGB automatically adds bidirectional edges.
Large-Scale Graph ML Datasets
There are three OGB-LSC datasets: MAG240M , WikiKG90Mv2 , and PCQM4Mv2 , which have unprecedented scale and coverage predictions at the node, link, and graph levels, respectively. An illustrative overview of the three OGB-LSC datasets is provided below.
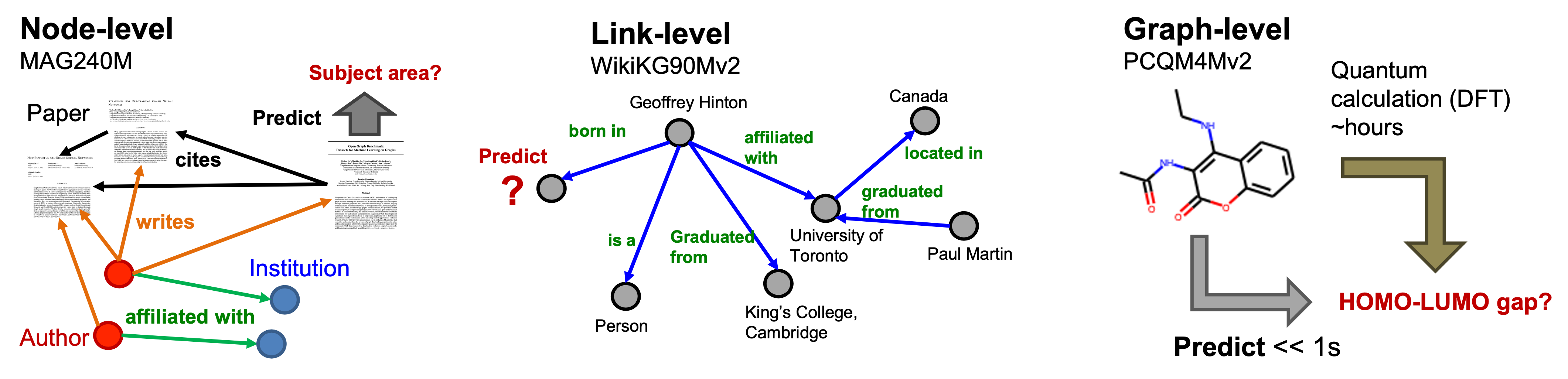
- MAG240M is a heterogeneous academic graph with the task of predicting the subject areas of papers located in the heterogeneous graph (node classification).
- WikiKG90Mv2 is a knowledge graph with the task of imputing missing triples (link prediction).
- PCQM4Mv2 is a quantum chemistry dataset with the task of predicting an important molecular property of a given molecule, namely the HOMO-LUMO gap (graph regression).
For each dataset, OGB carefully designs its prediction tasks and data splits so that achieving high prediction performance on the tasks will directly affect the corresponding applications. Further details are provided in each dataset page. The dataset statistics and basic information are summarized below, showing that the OGB dataset is very large.

†: The PCQM4Mv2 dataset is provided in the SMILES string. After processing them into graphics objects, the final file size will be around 8GB.