文章目录
声明
下面的故事,记录的技术要点,是真实发生在我身上的。为了记录下这些知识点,同时让大家以一个放松的心态去进行阅读,将其改编成诙谐幽默的小故事。
登场人物介绍:
H兄:我们的项目总监、技术负责人,老大哥的形象,一般也是问题的最后裁判员
C大:我们的架构师同学,技术涉猎面广,考虑问题全面,鬼点子也非常地多
小L:刚入职公司的应届毕业生开发,对技术有着无比的热情~需要的是时间磨练以及经验!
大V:高级JAVA开发,有着3年以上开发经验,正在朝架构师方向努力中!
Fox桑: 我们的测试同学,有着丰富的功能以及性能测试经验,总能在测试过程中发现很多虫子哦~
特别说明
本次的故事,素材依然来自我的工作经历。这次的故事,是一个发生在我们团队内部的真实案例,对于刚进入移动支付领域的同学来说,会是一个非常好的启发,让我们一起共勉。
背景知识
想要了解这个故事,首先我们得从移动支付的一般性流程说起。这里因为涉及到一些公司资产,有一些保密内容,因此我将整个移动支付系统模型做了一个简化。因此,在实际生产过程中,今天这个故事中讲到的数据模型以及流程,仅供大家学习研究之用,生产上是不够用的,切记哦!
一般来说,我们的移动支付中会有几个对象,订单、商品、支付流水。他们的关系,大体上是这样的:
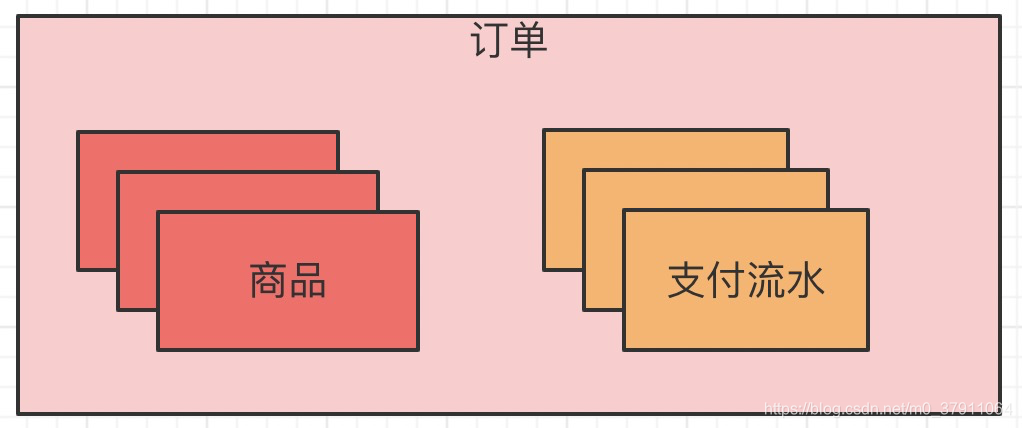
一笔订单,会有多个商品信息与之关,换句话说,可能会有一个或者多个商品,合并到一个订单内进行支付。
支付流水,可能也会存在一个或者多个,为什么这么说呢?暂且不论有没有可能一笔订单分微信和支付宝两个方式拆分支付。比如我们要设计一个优惠券系统的话,优惠券的抵扣金额,也应该生成一笔支付流水。否则的话,日终对账就会出现订单总额与流水总额对不起来的情况。同时,给用户展示的订单信息中,不展示优惠券抵扣部分金额,其实也是说不过去的。因此,一般在设计过程中,一笔订单会有多个支付流水。
当然,我们这次的故事,跟这个模型基本上没有关系,只是作为一个前提背景,我先给大家做一个简单的介绍。
在来述说我们的支付,一般来说,当下主流的支付渠道的支付方式,都是异步的。比如,我们来看一下支付宝的支付API:

很明显,我们创建订单以及支付流水应该是在第1步就完成,那么最终在支付宝完成支付,应当是在第7步才收到支付宝的异步回调通知。
毫无疑问,整个步骤是异步的。那么用我们的时序图把他画出来,应该是这个样子的:
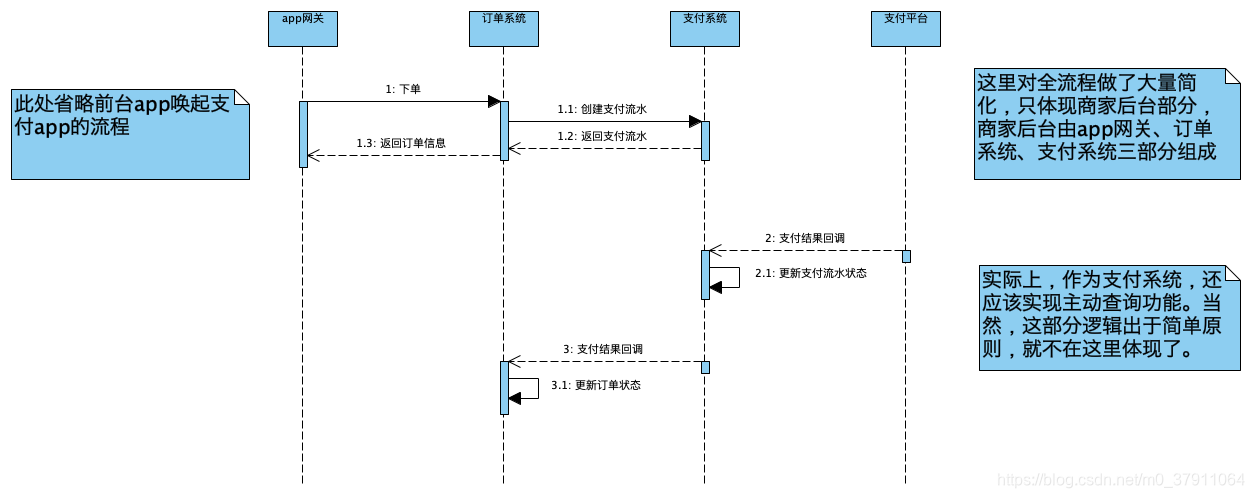
再次声明:上面的数据模型以及流程,我是做了大量简化的,中间有很多异常处理流程的,仅供大家学习研究之用,生产上是不够用的,切记哦!如果真的很想了解这一块应用的,可以私信我,我们可以私下交流。
好,如果你看懂了上面的这些流程以及模型。那么你可以开始看我们今天的故事了。
开发任务来了
这天,产品爸爸拿着macbook air笔记本电脑,英姿飒爽地走了过来:"H兄,你给排个期呗~看看咱们之前讨论的app商城支付,啥时候落地啊?“。
”那就现在?“H兄很爽快,因为这个需求已经被拖了半个月了,再不给个说法,估计要被产品爸爸吊打了。
需求很简答, 就是做个简单的app商城支付系统,因为之前的商城商品都是积分兑换的,现在开始要增加用钱购买的功能。
根据我们刚才说的一般流程,其实后台只要开发下单和支付两部分功能就行了。
然后,一番激烈的需求评审后。H兄直接就拍板了。因为与支付渠道对接,需要一定的开发经验,不太时候新手直接上,所以这部分工作就安排给了大V。
至于订单系统嘛,逻辑比较简答, 就是下单,然后维护订单状态,就交给我们的小L同学啦。
不就是流水状态更新嘛,看我来搞定
小L拿到需求之后,稍微想了一下整个业务流程,还认真的画了流程图,如下:
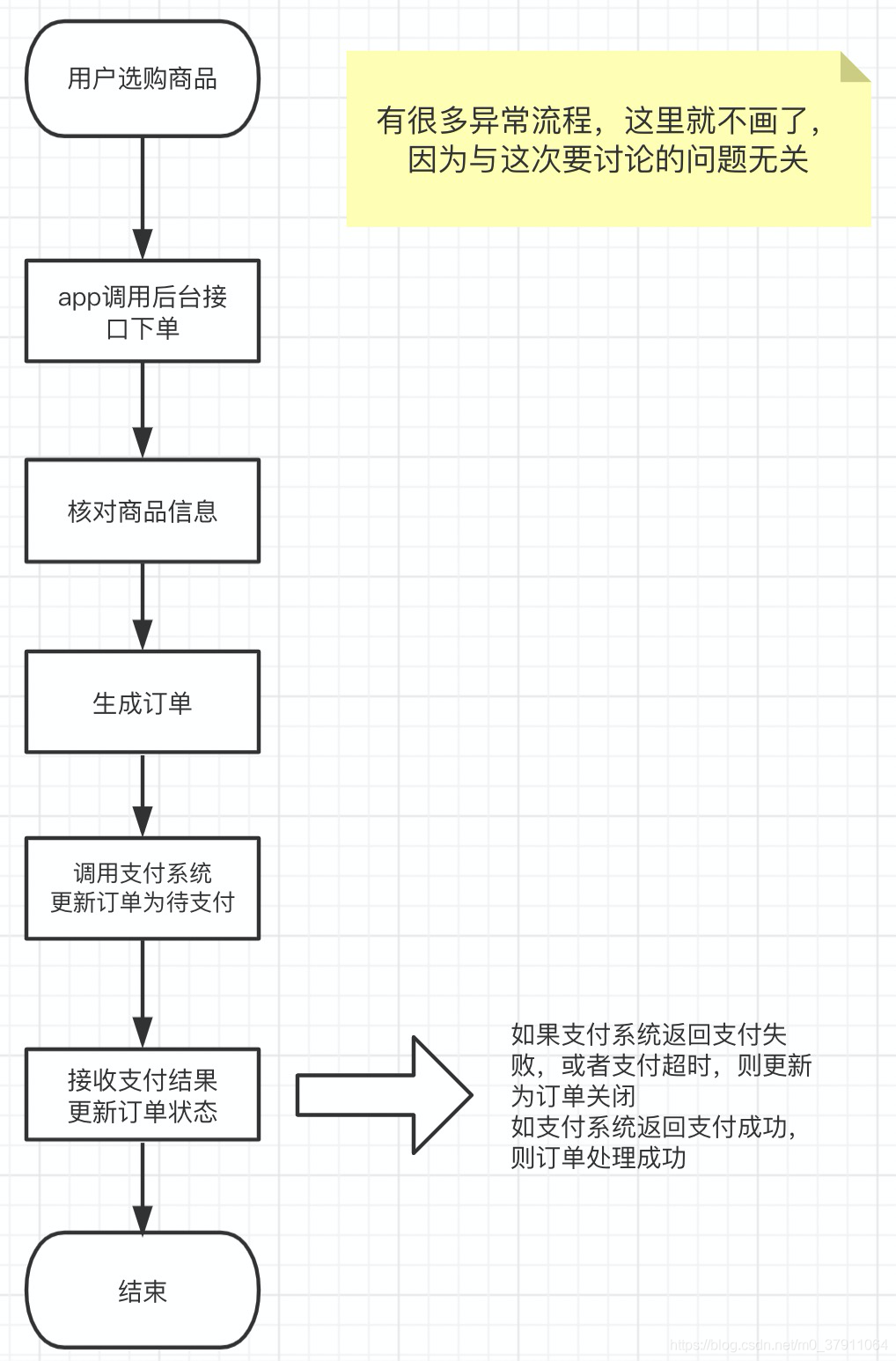
业务流程很简单嘛,小L也没多想,就开始咔咔地搞了,当开发到支付接口的时候,小L发现,大V的支付接口,其实是一个异步接口。于是小L将原来写好的处理支付结果的代码,放到了接收大V支付回调的MQ的消费者代码中。
一般来说,一个异步处理机制,分为请求提交,回调处理和主动查询三部分。这个故事里面,我们主要关注请求提交和回调处理,对主动查询,大家只要做到心中有数,自己去实现的时候不能只依赖于下游系统的回调机制,还应当有自己的主动查询机制。
没过几天,订单系统就搞定了。当小L跑完自己的测试用例后, 大V那边,也搞完了。两个人马上就进行了联调,结果非常顺利,没过两天就把所有他们能想到的点都测完了。于是,他们把代码做了最后一次提交,打上tag之后,就让Fox桑去做整体的测试了。
功能测试验收通过
fox桑对首先按照他俩给的部署文档,在测试环境把系统一点一点搭建好。然后对照着产品需求,以及前期整理好的测试用例,整体跑了一遍,发现功能上并没有什么问题。
下单,支付,订单成功,功能ok。
下单,取消支付,订单关闭,功能ok
下单,余额不足,订单关闭,功能ok
显然,fox桑对于这次的测试结果比较满意。于是,就开始准备进入压力测试了。
压测开始,然后。。。
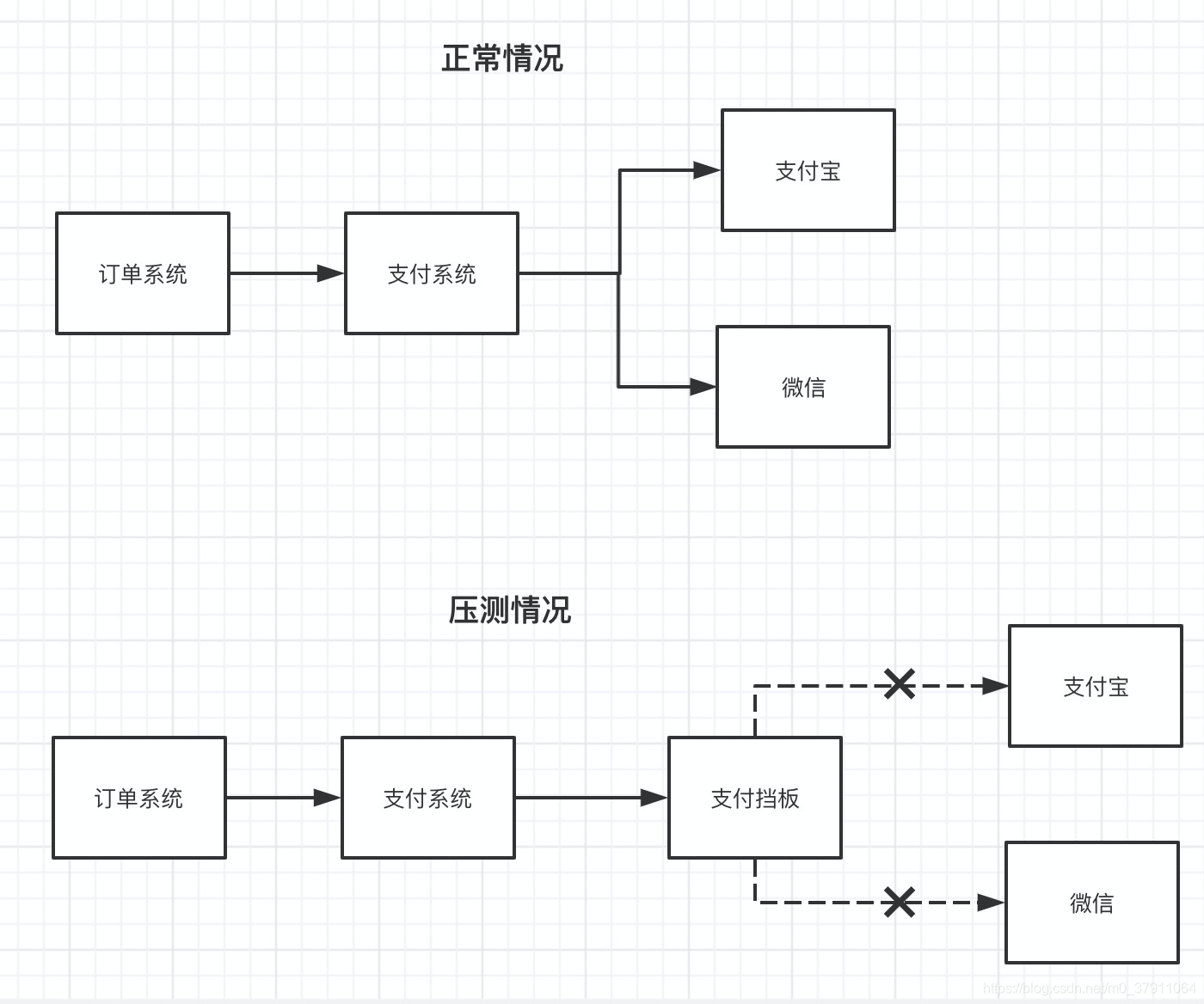
压测开始时,fox桑,换上了大V给他准备的支付挡板(挡板一定会返回支付成功)。
这里解释一下,什么叫做挡板。
在我们做压测的时候,数据肯定是随意生成的。就上面的例子而言,做压测的时候,显然是不可能直接去向支付渠道发起支付的。也就是说,我们要在支付系统与支付渠道中间,添加一个支付挡板,用来给支付系统模拟支付系统的返回(支付系统以为支付成功了,实际上并没有去发起支付)以模拟整个链路。链路看起来就像是下面这个样子的:
压测的成绩也相对来说可以,有400TPS,对于目前的每天几万单的系统体量来说,fox桑觉得已经完全足够了。
正当fox桑写完压测报告,准备清数据打完收工的时候,几条看起来很奇怪的数据,引起了fox桑的注意,慢慢地,fox桑皱起了眉头,发现事情好像不太对。
本地无法复现,大V居然也搞不定了
fox桑发现了什么问题呢?原来,订单的数据库记录中,有不少是待支付的!这说不通啊,挡板返回的都是支付成功,怎么可能会出现没有支付的订单呢?
fox桑马上叫来了大V,让大V来找找这其中可能出现的原因。大V看了下两边的数据之后,发现支付流水表中的数据,其实是正确的,也就是说,支付系统这边的处理逻辑是OK的,回调给订单的消息应该也是支付成功。但是实际上数据在订单表中的状态,却被更新成了待支付。
大V马上叫来了小L,一起看一下这其中的问题。他们仔仔细细地看了小L写的订单回调处理逻辑,以及程序运行的日志。

见了鬼了,payStatus=2,支付成功,最后update返回的结果也是1,说明数据成功更新了啊。但是为啥最后在数据库里看到的payStatus = 1 !!
这完全刷新了小L的三观!!写了这么久的update,突然之间,感觉是如此的陌生!当一个程序员真的好难啊!连update都不会写了,以后这漫漫长路可怎么走下去啊!
小L和大V之后又找了几个小时,又是拿数据本地模拟,又是在开发环境模拟,但始终无法复现这个问题。
他俩实在是没办法了,于是叫来了C大帮忙看看,或许C大能有办法呢,谁让他鬼点子多呢?
C大看了一眼程序的日志,然后又看了小L更新数据用的SQL:
update t_trade_record set payStatus = 2 where pay_id = 'xxx' and update_time = 'xxx'
这里说明一下,为啥更新数据的时候,这里小L加上了update_time的条件,主要是为了防止多个服务同时更新数据的时候,可以检测出来。如果其他服务更新了,那么update_time就会增加,update就返回0了,程序就可以做出对应的处理了。
最后去看了一眼出问题的数据库的数据,然后心中似乎有了答案,但是还不能完全确定。
甩下一句:“我大概知道问题出在那里了,我去找运维要个东西来证实我的想法!”。
原来binlog还能这么玩
C大找运维去要什么了呢?过了半个小时,C大回来了,拿着一个文件mysql-bin.000001。
原来C大去找运维拿mysql数据库的binlog去了,目的就是为了去查找压测期间,数据更新的记录。
C大将binlog拷贝到本地,然后用本地安装的mysql数据库中的mysqlbinlog组件。娴熟地敲下这条命令:
mysqlbinlog --base64-output=decode-rows -v -d xxx --start-datetime='2020-03-10 14:33:06' --stop-datetime='2018-03-20 14:34:07' mysql-bin.000001 > 1.sql
然后,就得到了一个1.sql的文件,里面记录了标识为xxx的数据库,从2020-03-10 14:33:06至2018-03-20 14:34:07的所有数据更新记录。
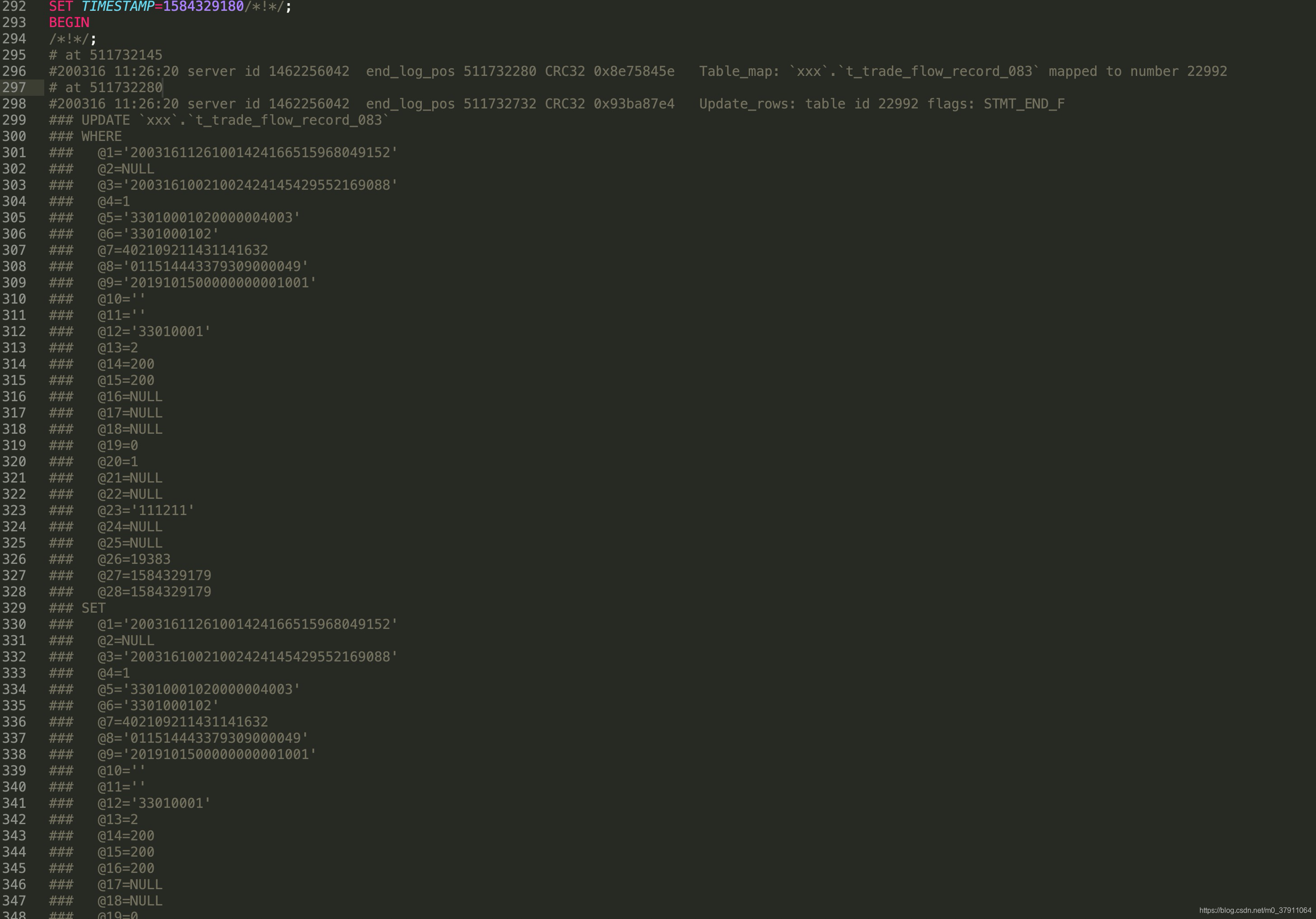
根据小L提供的订单编号,C大很快就找到了这期间,这条数据的所有操作。
数据的payStatus变更路径如下: insert(0) -> update(2) -> update(1)
C大说:“明白了吧,这就是你日志提示更新成功,但最后结果是1的原因!数据确实在中间被更新成了2,但是最后又被更新成了1。”
原来,由于加了支付挡板,再加上压测数据的密集程度增加,使得CPU压力升高,原本能在几毫秒的过程中完成的提交支付后的更新,被拉到支付回调更新以后才执行!
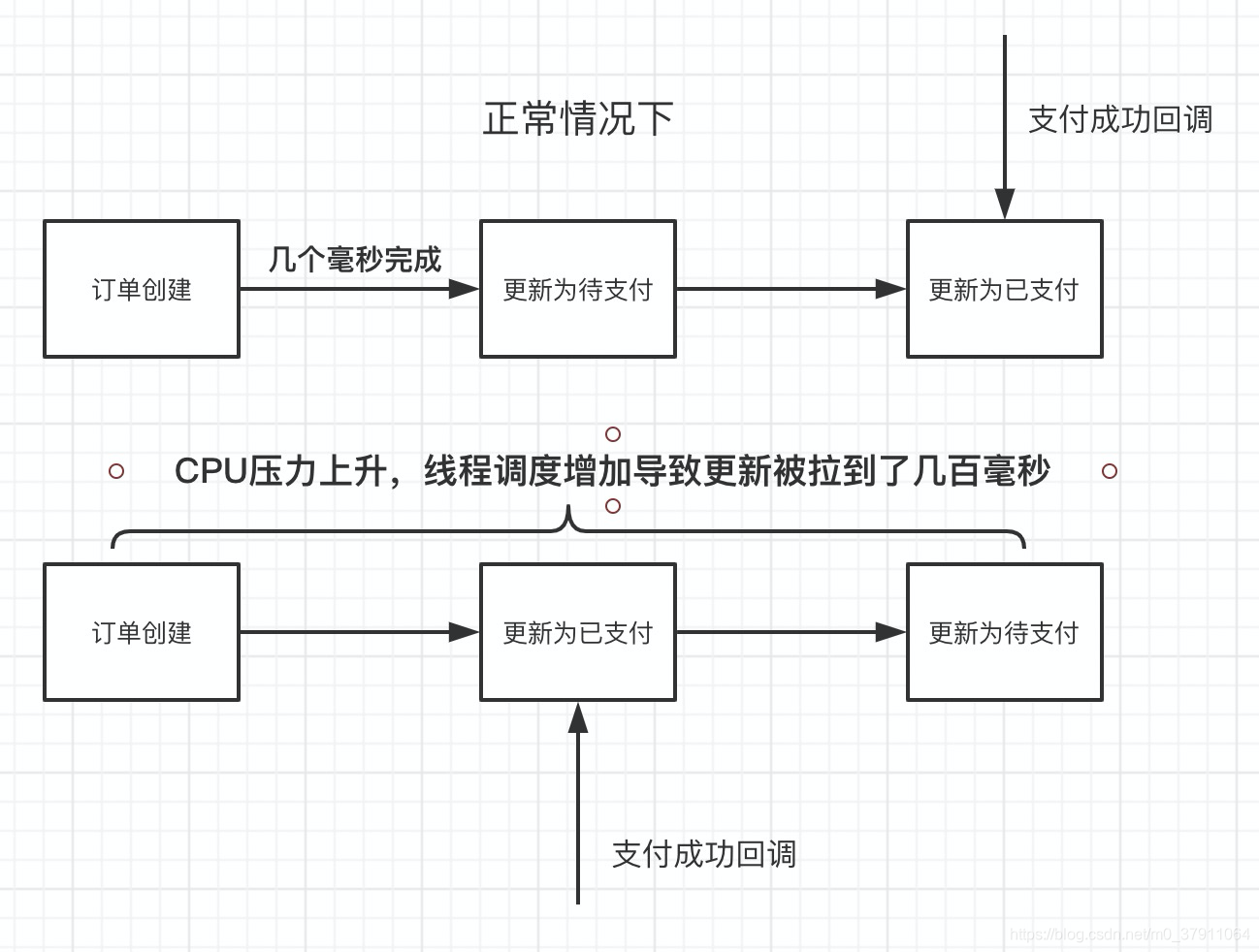
但是,小L不是对update_time做时间判断了吗?为什么还是会有问题呢?
原因就在于,update_time只是精确到1秒,如果更新时序问题发生在1秒钟之内,那么这种写法,也就无法避免出现这个问题了。
就好比我们在使用CAS进行多线程更新的时候,也无法避免ABA的问题。
知道了问题以后,小L对自己的SQL进行了修改,这个问题就得以解决了。只有当订单记录是已创建的时候,才更新成待支付,其他状态说明状态已经发生变更,则不进行处理了。
update t_trade_record set payStatus = 1 where pay_id = 'xxx' and update_time = 'xxx' and pay_status = 0
如何写好状态更新流程,其实有套路
有很多办法,能够帮助我们管理好数据状态的变更。防止一些极端情况下出现的数据状态混乱的问题。
- 是否只需要保证数据的最终一致性。
在分布式系统中,有一个著名的CAP原则,我们往往会选择高可用以及分区容错来提高系统的吞吐量和可用性,但需要牺牲系统数据的强一致性,取而代之使用数据的最终一致性来保证系统的最终结果正确。
- 搞清业务逻辑,然后针对需要变更状态的数据,绘制一下各个状态的流转图。
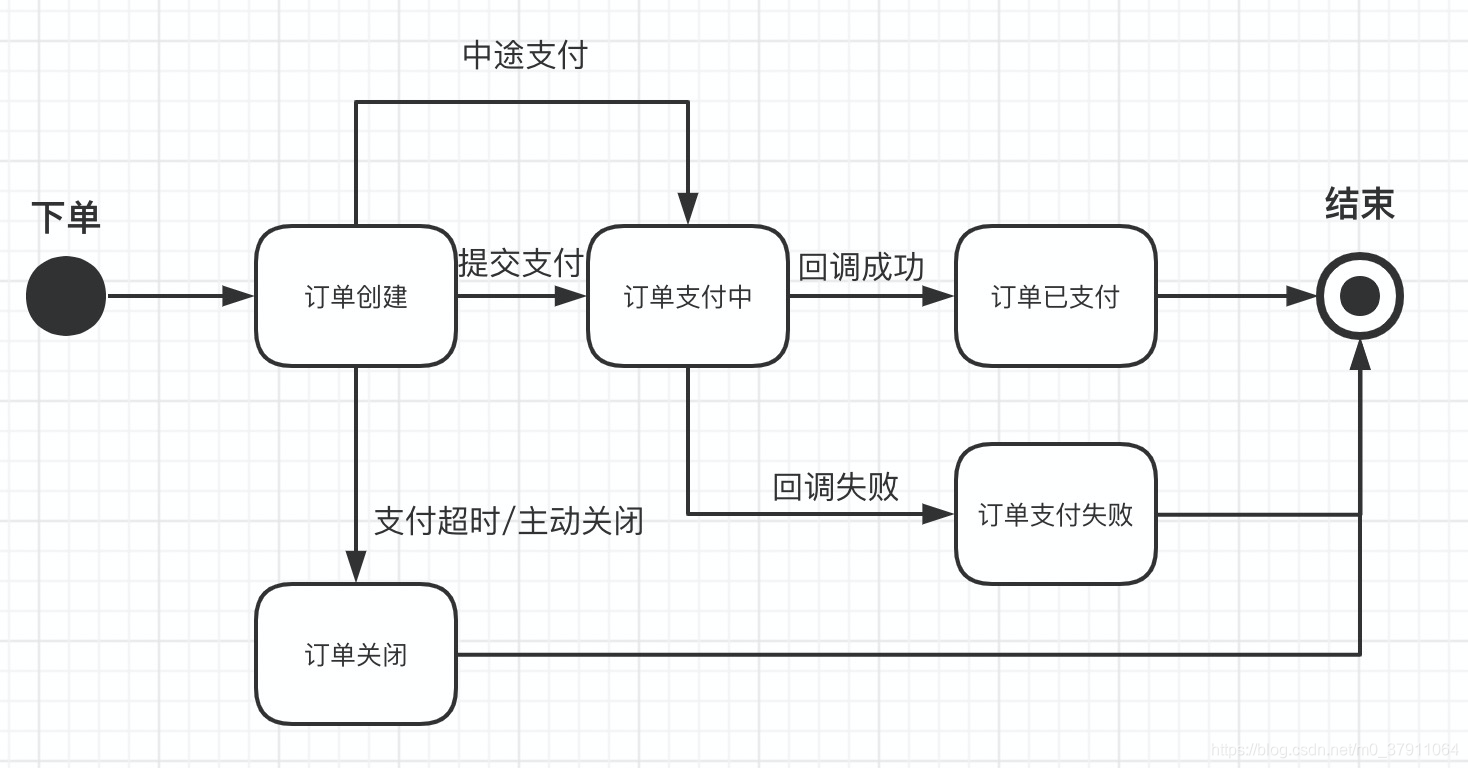
在图中,我们就能清晰地看到有状态的业务数据模型,在各个条件下的状态流转。这里有个套路:“与结束有直接箭头关联的状态,我们称之为最终状态,数据一旦进入最终状态,就不应该再被变更。” 这就能很好地指导我们去写这个业务数据的update,对于这种已经是终态的数据,我们在写SQL更新的时候,就能够写形如 stat <> 1 and stat <> 2…,来防止这些进入最终状态的数据,因为时序问题,又被更新成了中间状态,从而保证了数据的最终一致性!
- 业务逻辑复杂,状态非常多的时候,我们在写代码的时候,可以考虑使用状态机模式。
总结
上面这个例子,很好地解释了为什么一个业务系统运行了很久都没有出现问题,也很少发布版本,但是线上环境再某一天突然就出现了大量的问题。
很多问题,其实都是隐藏在高并发下,在一般的低负载情形下,是很难复现的。因此,有时候我们去做性能测试,并不单单是因为业务场景的并发需求有多高。而是有助于我们去评估系统的容量,对系统中的配置参数调优以及发现一些低负载情况下无法发现的程序bug。
今天的故事就到这里,希望大家能够有所收获。
