利用所学的R语言,对于2019-ncov的数据进行处理,并预测新增和累计人数情况。
给的xlsx文件如下图:

导入数据
1.加入xlsx读取数据包,查看数据情况
library(xlsx)
data<-read.xlsx(‘D:b.xlsx’,colNames=FALSE,rowNames=TRUE,sheet=2,rows=1:4)
sheet表示excel中的sheet rows表示数据的多少行
2.直接在剪贴板读取.
在excel中复制数据,利用
data=read.table(“clipboard”,header=T)直接获取
数据处理
为了画图或者利用预测模型,需要对数据进行处理。
#数据转置
data<-t(data)
data<-data.frame(data)
这里,一般直接读取数据,日期并不是准确的,而是常规的显示为数字。所以需要对其进行转换:

每个日期计算好形式,再来分析。
#删除NA所在行
data<-data[-manyNAs(data),]
time<-change_date(data[,1])
data
#将时间由chr类型转换为时间序列类型
datatime<-as.POSIXct(time)
#各地区新增人数
hubei=data[,2]
feihubei=data[,3]
quanguo=data[,4]
dataup<-cbind(hubei,feihubei,quanguo)
Data<-xts(x=dataup,order.by =datatime)
#数据预处理结束
View(Data)

作出可视化处理
利用plot画图,也可用barplot进行直方图绘制,也可用stars绘制星相图。
可视化结果如图:

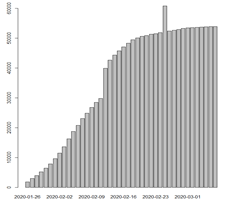
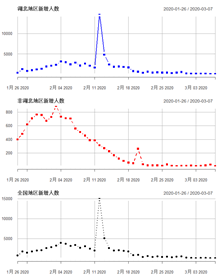
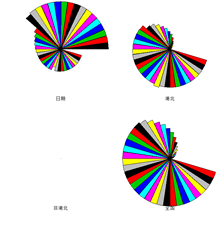
通过不同的折线图,直方图来分析疫情的走势情况,累计人数都在增长,越往后增长的速度越慢。
新增人数在到达峰值点后,持续的在降低。
时间序列预测 ARIMA模型
指数平滑法对于预测来说是非常有帮助的,而且它对时间序列上面连续的值之间相关性没有要求。但是,如果使用指数平滑法计算出预测区间那么预测误差必须是不相关的,而且必须是服从零均值、方差不变的正态分布。
即使指数平滑法对时间序列连续数值之间相关性没有要求,在某种情况下,我们可以通过考虑数据之间的相关性来创建更好的预测模型。自回归移动平均模型( ARIMA)包含一个确定(explicit)的统计模型用于处理时间序列的不规则部分,它也允许不规则部分可以自相关。
首先,先确定数据的差分。ARIMA 模型为平稳时间序列定义的。因此,如果你从一个非平稳的时间序列开始,首先你就需要做时间序列差分直到你得到一个平稳时间序列。如果你必须对时间序列做 d 阶差分才能得到一个平稳序列。
那么你就使用ARIMA(p,d,q)模型,其中d是差分的阶数。
针对非湖北地区:

一阶差分的图中可以看出,数据仍是不平稳的。继续差分,二次差分也是不平稳。三次差分后的时间序列在均值和方差上确实看起来像是平稳的,随着时间推移, 时间序列的水平和方差大致保持不变。因此,直接三次两次差分以得到平稳序列。
接着,选择合适的ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的 p值和q值。为了得到这些,通常需要检查平稳时间序列的(自)相关图和偏相关图。
“acf()”和“pacf 设定“plot=FALSE” 来得到自相关和偏相关的真实值。 自
相关图显示滞后1阶自相关值基本没有超过边界值,虽然5阶自相关值超出边界,那么很可能属于偶然出现的,而自相关值在其他上都没有超出显著边界, 而且我们可以期望1到20之间的会偶尔超出 95%的置信边界。
预测分析
最后,针对不同数据进行预测分析,利用forecast中的arima函数来进行预测分析,最后可得值得大小。
非湖北的累计人数预测情况:
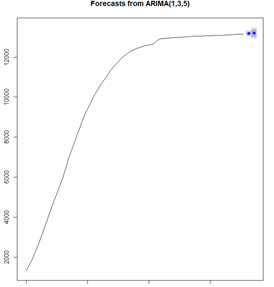
 其中,后两天的预测值为13172和13193。
其中,后两天的预测值为13172和13193。
结果分析
通过实际情况和预测情况对比:

从新增人数的预测表来看,整体预测效果较好,针对ARIMA模型,选取准确的p和q的值,能更好的进行预测。
所有R语言代码
新增人数sheet1(读入数据采用剪贴板)
library(SparkR)
library(DMwR)
library(xts)
library(xlsx)
library(lubridate)
library(stringr)
library(sqldf)
#为了读取数据方便,直接在剪贴板读取数据;
data=read.table("clipboard",header=T)
#数据转置
data<-t(data)
data<-data.frame(data)
data
#各地区新增人数
hubei<-data[,1]
hubei
feihubei<-data[,2]
feihubei
quanguo<-data[,3]
quanguo
Data<-data
#加上标题
dataup<-cbind(hubei,feihubei,quanguo)
Data<-xts(x=dataup,order.by =datatime)
#数据预处理结束
View(Data)
#做出新增人数图
par(mfrow=c(3,1))
plot(Data$hubei,type="b",pch=15,lty=1,col = "blue",main = "湖北地区新增人数")
plot(Data$feihubei,type="b",pch=15,lty=2,col = "red",main = "非湖北地区新增人数")
plot(Data$quanguo,type="b",pch=19,lty=3,col = "black",main = "全国地区新增人数")
par(mfrow=c(1,1))
#直方图
barplot(apply(Data,1,mean))
#星相图
par(mfrow=c(1,1))
stars(data1,full=T,draw.segments=T,key.loc = c(15,1))
#时间序列预测 ARIMA模型
#非湖北地区
par(mfrow=c(3,1))
feihubeidata<-xts(x=feihubei,order.by =datatime)
plot(Data$feihubei,type="l",col = "blue",main = "非湖北地区新增确诊人数")
#一阶差分
feihubei1<-diff(Data$feihubei,differences=1)
plot(feihubei1,xlab="时间",ylab="新增人数一阶差分",main="非湖北新增确诊一阶差分")
#二阶差分
feihubei2<-diff(feihubei1,differences=1)
plot(feihubei2,xlab="时间",ylab="新增人数二阶差分",main="非湖北新增确诊二阶差分")
#确定p,q的值
#由于有空值NA,先删除
feihubei2=na.omit(feihubei2,)
acf(feihubei2,lag.max=20,plot=FALSE)
pacf(feihubei2,lag.max=20,plot=FALSE)
par(mfrow=c(1,1))
#非湖北地区预测
library(forecast)
auto.arima(data$非湖北)
feihubeiyuce<-arima(x=Data$feihubei,order=c(0,2,2),method="ML")
Feihubeiyuce<-forecast(feihubeiyuce,h=2)
Feihubeiyuce
plot(Feihubeiyuce)
#湖北地区
par(mfrow=c(3,1))
plot(Data$hubei,type="l",col = "blue",main = "湖北新增人数")
#求一阶差分
hubei1<-diff(hubei)
plot(hubei1,type="l",xlab="时间",ylab="新增人数一阶差分",main="湖北新增人数一阶差分")
#求二阶差分
hubei2<-diff(hubei1)
plot(hubei2,type="l",xlab="时间",ylab="新增人数二阶差分",main="湖北新增人数二阶差分")
#确定p,q的值
hubei2=na.omit(hubei2,)
acf(hubei2,lag.max=20,plot=FALSE)
pacf(hubei2,lag.max=20,plot=FALSE)
#预测后两天人数变化情况
library(forecast)
auto.arima(data$湖北)
#利用forecast中的arima函数进行预测
yuce<-arima(x=hubei,order=c(0,2,1),method="ML")
hubeiyuce<-forecast(yuce,h=2)
hubeiyuce
plot(hubeiyuce)
#全国地区
par(mfrow=c(3,1))
plot(Data$quanguo,type="l",col = "blue",main = "全国新增人数")
#求一阶差分
quanguo1<-diff(quanguo)
plot(quanguo1,type="l",xlab="时间",ylab="新增人数一阶差分",main="全国新增人数一阶差分")
#求二阶差分
quanguo2<-diff(quanguo1)
plot(quanguo2,type="l",xlab="时间",ylab="新增人数二阶差分",main="全国新增人数二阶差分")
#确定p,q的值
quanguo2=na.omit(quanguo2,)
acf(quanguo2,lag.max=20,plot=FALSE)
pacf(quanguo2,lag.max=20,plot=FALSE)
#预测后两天人数变化情况
library(forecast)
auto.arima(data$全国)
#利用forecast中的arima函数进行预测
yuce<-arima(x=quanguo,order=c(0,2,8),method="ML")
quanguoyuce<-forecast(yuce,h=2)
quanguoyuce
plot(quanguoyuce)
累计数据 读入数据采用xlsx sheet2
library(SparkR)
library(DMwR)
library(xts)
library(xlsx)
library(lubridate)
library(stringr)
library(sqldf)
#读取数据,列表2的1到4行数据;这里直接读取,需要对日期进行修正
data<-read.xlsx('D:b.xlsx',colNames=FALSE,rowNames=TRUE,sheet=2,rows=1:4)
data1<-data
#数据转置
data<-t(data)
data<-data.frame(data)
#将得到的时间数据转为标准时间格式
data
change_date=function(date_str){
date_str_norm= str_extract(date_str, '\\d{4}-\\d{1,2}-\\d{1,2}|\\d{4}/\\d{1,2}/\\d{1,2}|\\d{8}')
norm_index=which(!is.na(date_str_norm))
int_index=which(is.na(date_str_norm))
date_str_int = date_str[int_index]
date_str_int=round(as.numeric(as.character(date_str_int)), 0)
date_str_int = as.character(ymd('1899-12-30') + days(date_str_int))
date_str[norm_index]= as.character(ymd(date_str_norm[norm_index]))
date_str[int_index] = date_str_int
return (date_str)
}
#删除NA所在行
data<-data[-manyNAs(data),]
time<-change_date(data[,1])
data
#将时间由chr类型转换为时间序列类型
datatime<-as.POSIXct(time)
#各地区新增人数
hubei=data[,2]
feihubei=data[,3]
quanguo=data[,4]
dataup<-cbind(hubei,feihubei,quanguo)
Data<-xts(x=dataup,order.by =datatime)
#数据预处理结束
View(Data)
#做出累计人数图
par(mfrow=c(3,1))
plot(Data$hubei,type="b",pch=15,lty=1,col = "blue",main = "湖北地区累计人数")
plot(Data$feihubei,type="b",pch=15,lty=2,col = "red",main = "非湖北地区累计人数")
plot(Data$quanguo,type="b",pch=19,lty=3,col = "black",main = "全国地区累计人数")
par(mfrow=c(1,1))
#直方图
barplot(apply(Data,1,mean))
#星相图
par(mfrow=c(1,1))
stars(data1,full=T,draw.segments=T,key.loc = c(15,1))
#时间序列预测 ARIMA模型
#非湖北地区
par(mfrow=c(4,1))
feihubeidata<-xts(x=feihubei,order.by =datatime)
plot(Data$feihubei,type="l",col = "blue",main = "非湖北地区累计确诊人数")
#一阶差分
feihubei1<-diff(Data$feihubei,differences=1)
plot(feihubei1,xlab="时间",ylab="新增人数一阶差分",main="非湖北累计确诊一阶差分")
#二阶差分
feihubei2<-diff(feihubei1,differences=1)
plot(feihubei2,xlab="时间",ylab="新增人数二阶差分",main="非湖北累计确诊二阶差分")
#三阶差分
feihubei3<-diff(feihubei2)
plot(feihubei3,xlab="时间",ylab="新增人数三阶差分",main="非湖北累计确诊三阶差分")
feihubei3=na.omit(feihubei3,)
#确定p,q的值
acf(feihubei3,lag.max=20,plot=FALSE)
pacf(feihubei3,lag.max=20,plot=FALSE)
par(mfrow=c(1,1))
#非湖北地区预测
library(forecast)
auto.arima(data$非湖北)
feihubeiyuce<-arima(x=Data$feihubei,order=c(1,3,3),method="ML")
Feihubeiyuce<-forecast(feihubeiyuce,h=2)
Feihubeiyuce
plot(Feihubeiyuce)
#湖北地区
par(mfrow=c(3,1))
plot(Data$hubei,type="l",col = "blue",main = "湖北累计人数")
#求一阶差分
hubei1<-diff(hubei)
plot(hubei1,type="l",xlab="时间",ylab="累计人数一阶差分",main="湖北累计人数一阶差分")
#求二阶差分
hubei2<-diff(hubei1)
plot(hubei2,type="l",xlab="时间",ylab="累计人数二阶差分",main="湖北累计人数二阶差分")
#确定p,q的值
hubei2=na.omit(hubei2,)
acf(hubei2,lag.max=20,plot=FALSE)
pacf(hubei2,lag.max=20,plot=FALSE)
#预测后两天人数变化情况
library(forecast)
auto.arima(data$湖北)
#利用forecast中的arima函数进行预测
yuce<-arima(x=hubei,order=c(1,2,4),method="ML")
hubeiyuce<-forecast(yuce,h=2)
hubeiyuce
plot(hubeiyuce)
#全国地区
par(mfrow=c(3,1))
plot(Data$quanguo,type="l",col = "blue",main = "全国累计人数")
#求一阶差分
quanguo1<-diff(quanguo)
plot(quanguo1,type="l",xlab="时间",ylab="累计人数一阶差分",main="全国累计人数一阶差分")
#求二阶差分
quanguo2<-diff(quanguo1)
plot(quanguo2,type="l",xlab="时间",ylab="累计人数二阶差分",main="全国累计人数二阶差分")
#确定p,q的值
quanguo2=na.omit(quanguo2,)
acf(quanguo2,lag.max=20,plot=FALSE)
pacf(quanguo2,lag.max=20,plot=FALSE)
#预测后两天人数变化情况
library(forecast)
auto.arima(data$全国)
#利用forecast中的arima函数进行预测
yuce<-arima(x=quanguo,order=c(0,2,12),method="ML")
quanguoyuce<-forecast(yuce,h=2)
quanguoyuce
plot(quanguoyuce)
