Matrix Weighted Intra Prediction(MIP)技术,即矩阵加权帧内预测技术,是VVC中新增加的一种帧内预测技术。其最初的思想来源于基于神经网络的帧内预测技术(JVET-J0037),即利用多层神经网络基于相邻已重建像素预测当前pu像素值。但是这种预测方式复杂度太高,经过权衡,发展出最后采纳的基于线性仿射变换的帧内预测技术。
Tracking route: N0217 -> M0043 -> L0199 -> K0196 -> J0037
其主要流程如下图:

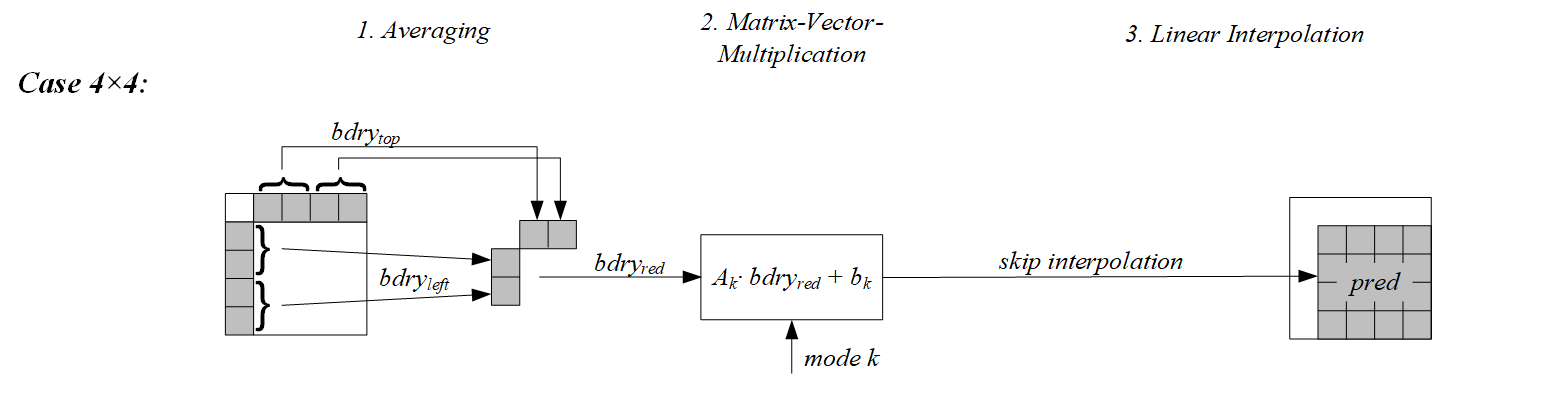
对于预测一个宽度为W和高度为H的矩形块PU,矩阵加权帧内预测(MIP)以块左侧的的H重建像素和块上方的W个重建像素作为输入(重建像素的获取和传统帧内预测相同),然后通过平均、矩阵向量乘法和线性插值获得最终预测像素。
1.平均
此步骤主要目的是对参考像素进行归一化,即根据块大小和形状,通过平均来获得4个或8个像素,具体为对于4x4的PU归一化为4个像素,对于其余形状的PU归一化为8个像素。
具体来说,首先对输入的长参考边界像素和
通过计算邻域平均的方法化为短参考边界像素
和
以减少预测过程中的计算量和模型参数存储空间。当W=H=4时,左边取2个上边取2个,共4个。其他情况下左边取4个,上边取4个,共8个。计算邻域平均是个下采样过程,如下:

然后将转换后的这两个短参考边界和
连接成最终的长度为4或者8的向量
,连接的方式如下:

其中,mode指的是MIP-mode。

2.矩阵向量相乘
通过对平均后获得的向量进行矩阵向量乘法,然后加上偏移量, 获得预测值
,其尺寸为
X
,其中
和
定义如下:

预测值的生成过程如下:
![]()
其中A是一个行 (W==4&H==4?4:8)列的矩阵,b为尺寸为
的向量。实际应用中,A和b都已经预先训练好,存储在集合
中,集合的索引与尺寸有关:
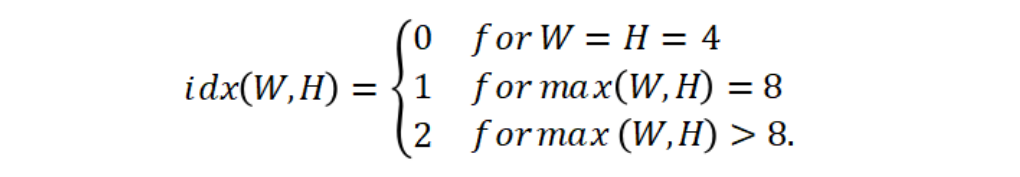
S0中包含mipMatrix4x4和mipBias4x4,S1中包含mipMatrix8x8和mipBias8x8,S2中包含mipMatrix16x16和mipBias16x16。
mipMatrix4x4里含18个16x4的矩阵,mipBias4x4里含18个16维的向量,用于4x4的块。
mipMatrix8x8里含10个16x8的矩阵,mipBias8x8里含10个16维的向量,用于4x8,8x4,8x8块。
mipMatrix16x16里含6个64x8的矩阵,mipBias16x16里含6个64维的向量,用于其他块。
注:
1、由getNumModesMip函数可知,4x4块有35种MIP模式,4x8,8x4,8x8块有19种MIP模式,其他情况有11种模式。而这里S0,S1,S2长度分别是18,10,6,比之前减半了。注意由getWeightIdx可知每2种模式共享一个矩阵和向量。
2、对于4xn,nx4(n>8)的块,由上面公式可知其对应的矩阵A应该是32x8,这里使用S2内的矩阵和向量进行计算,其中会丢掉矩阵中的32行和向量中的32个值。丢掉的行分别对应于生成的8x8矩阵中的x奇数位置和y的奇数位置。
3.插值
插值是一个上采样过程。通过上一步矩阵向量相乘获得一个向量,长度为
,它可以转换为一个
x
的矩阵,该矩阵一般小于W x H,因此需要在水平方向或者垂直方向或者水平垂直两个方向上进行插值。如果两个方向都需要插值,如果W<H先进行水平方向插值否则先进行垂直方向插值。
以WxH块的垂直插值为例,其中max(W,H)≧8且W≧H。
首先,将待插值的矩阵扩展到上面一行,如图1右半部分所示。上边一行按下式得到。
然后,对空余位置利用相邻值按下式进行插值。

从上面公式可以看出,当上采样2倍时即U_ver=2或H_ver=2,进行插值计算时不需要乘法运算。在其他情况下每次插值计算会进行不多于2次乘法运算。
插值改进- 只用移位操作 :
对于垂直方向的线性插值,首先对上下预测值进行加权,计算方式如下:

使用相邻的加权参考,于是垂直上采样可以写成以下形式:

水平方向插值可用相同的方式得出。
4.MIP模式的编码
对于帧内模式下的每个编码单元(CU),会发送是否将MIP模式应用于相应的预测单元(PU)的标志。 如果要应用MIP模式,则会发出MIP模式(preModeIntra)的信号。对于MIP模式,如下得出一个转置标志(isTransposed),该标志确定该模式是否被转置,MIP模式 Id(modeId)确定用于使用哪种MIP矩阵。
isTransposed = preModeIntra & 1
modeId = preModeIntra >> 1
VTM中根据CU尺寸,最多支持35中MIP预测模式。具体来说,对于&
尺寸的CU支持35种预测模式,max(W,H)=8和max(W,H)>8分别有19和11种预测模式。为了减少不同模式存储时的内存占用,两种模式可能会共用Metrix和offset,具体共用模式情况如下:

为降低模式传输消耗带宽资源,具体模式编码策略如下:
对于帧内编码CU,首先需要1bit标志位表明是否采用MIP模式,如果采用,额外1bit标识模式是否在MPM中,MIP支持3个MPM模式。MPM模式采用上下文截断二进制编码,非MPM模式采用定长编码。MPM的生成和传统帧内保持一致,MIP模式的获取通过预定义的映射表由传统帧内模式映射得出,如下: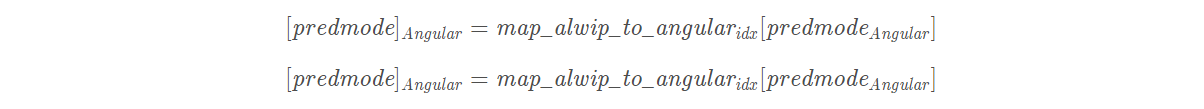
5.示例
1).对于4x4的块,从左边和上边参考行各取两个值组成一个4维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S0。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成一个4x4的矩阵不用进行插值直接作为预测矩阵。预测矩阵的每个值需要进行(4x16)/(4x4)=4次乘法运算。
2).对于8x8的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S1。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成预测矩阵的奇数位置值。然后在垂直和水平方向进行插值,由于这个插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x16)/(8x8)=2次乘法运算。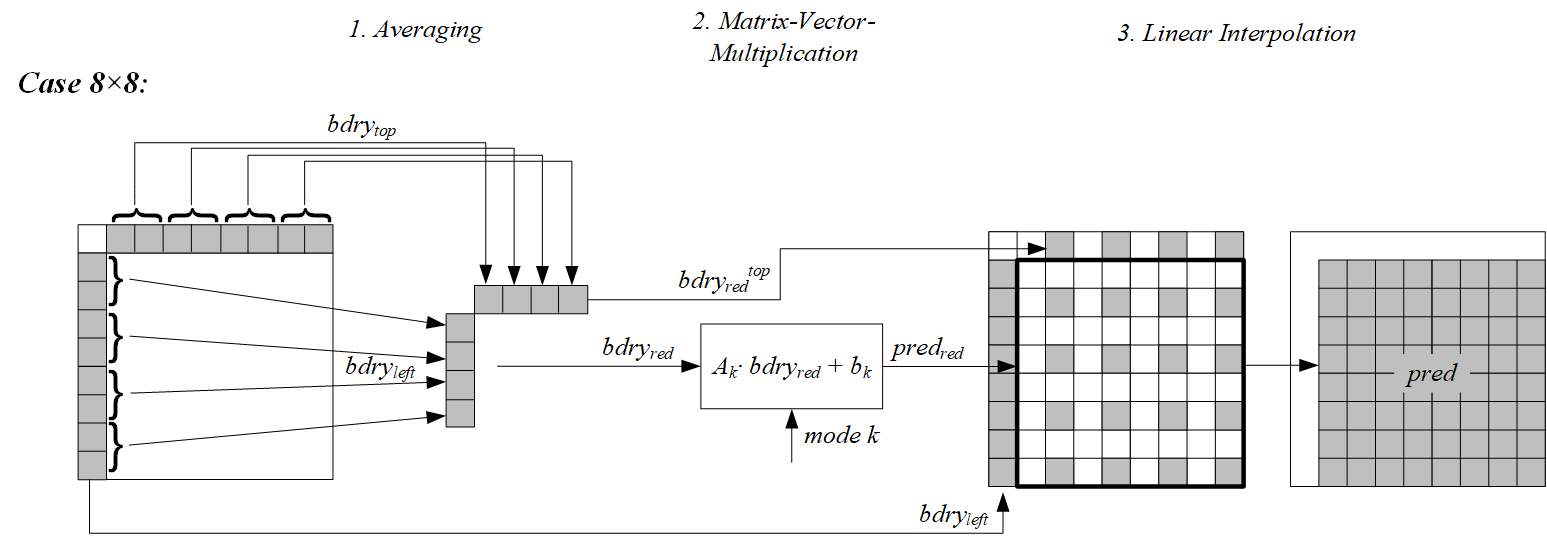
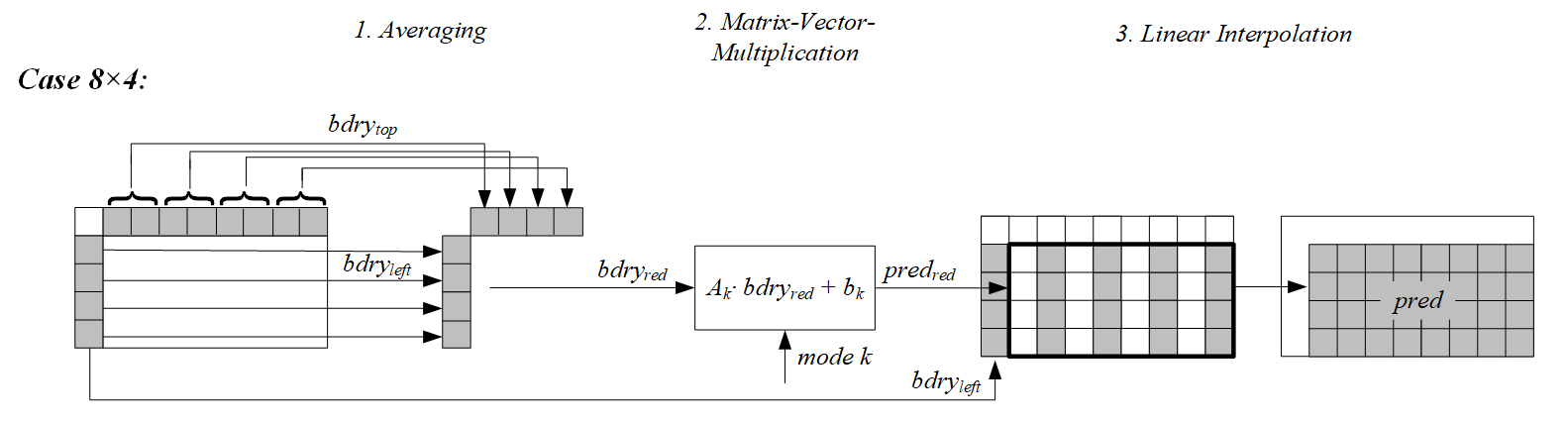
3.对于8x4的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S1。完成矩阵向量相乘和偏移值相加后得到一个16维的向量。这个16维向量形成预测矩阵的奇数行值和所有的列值。然后在水平方向进行插值,由于这个插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x16)/(8x4)=4次乘法运算。4x8块处理过程类似。
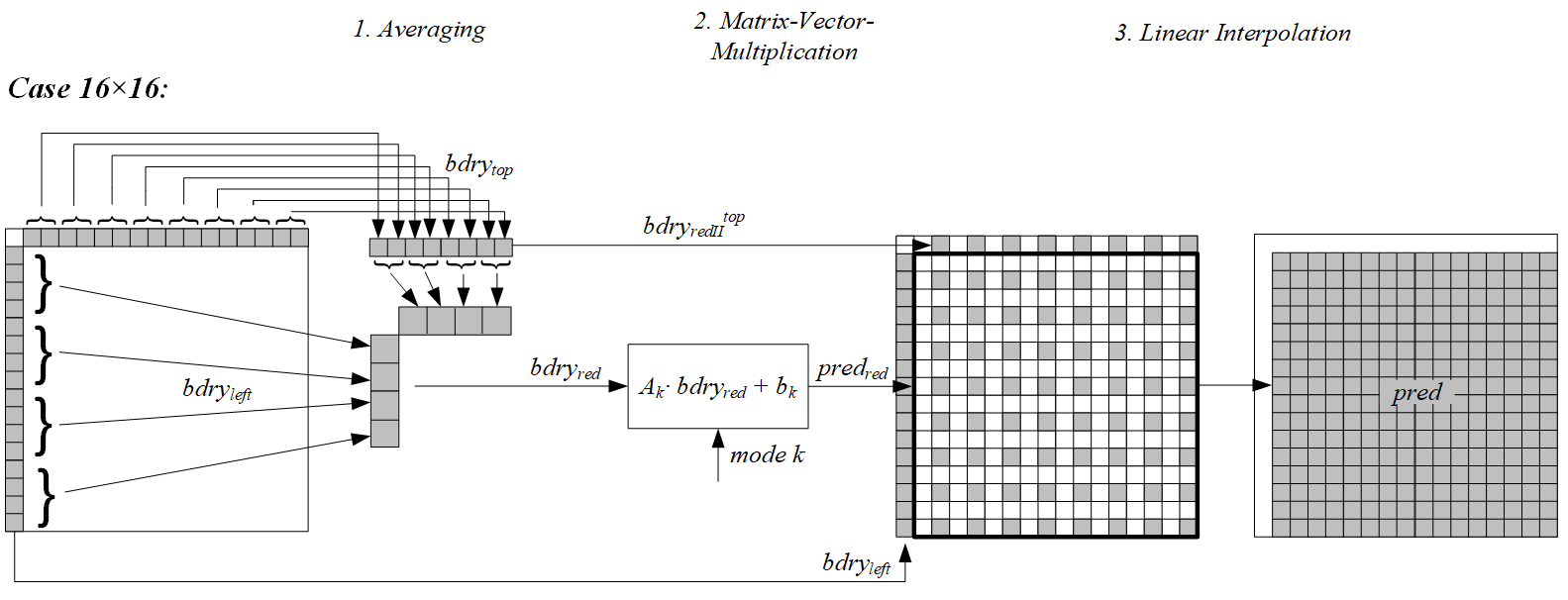
4.对于16x16的块,从左边和上边参考行各取4个值组成一个8维的向量。将该向量进行矩阵向量相乘运算,矩阵取自于S2。完成矩阵向量相乘和偏移值相加后得到一个64维的向量。这个64维向量形成预测矩阵的奇数行值和奇数列值。然后在垂直和水平方向进行插值,由于插值过程不需要进行乘法运算,所以预测矩阵的每个值需要进行(8x64)/(16x16)=2次乘法运算。
对于更大尺寸的块处理过程类似,很容易计算出每个样点乘法运算次数小于4。
对于Wx8,W>8的块,生成的8x8预测矩阵包含所有行和奇数列,所以只需要在水平方向进行插值。预测矩阵的每个值需要进行(8x64)/(Wx8)=64/W次乘法运算。当W=16时,它的线性插值过程不需要乘法运算。当W>16时,每个像素插值过程需要的乘法运算少于2次。所以每个像素总的乘法运算小于等于4次。8xW类似。
对于Wx4的块,矩阵相乘时要去掉矩阵的奇数行,最终只需要在水平方向进行插值。预测矩阵的每个值需要进行(8x32)/(Wx4)=64/W次乘法运算。当W=16时,它的线性插值过程不需要乘法运算。当W>16时,每个像素插值过程需要的乘法运算少于2次。所以每个像素总的乘法运算小于等于4次。4xW类似。
