模型评估与选择
1. 性能度量
性能度量 是衡量模型泛化能力的评价标准,对模型泛化评估时,不仅需要有效的实验估计方法,还需要评价标准,这就是性能度量,具体有错误率与精度、查准率、查全率与F1、ROC与AUC等。
在预测任务中,给定数据集{ (x1,y1),(x2,y2),……,(xm,ym) },其中yi是xi的label,回归任务最常见的性能度量则是“均方误差”。
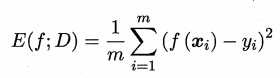
对于一般来说,对于数据分布 D 和概率密度函数 p(·),均方误差还可以写成下面公式:
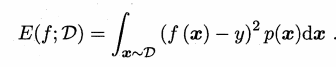
1.1. 错误率与精度
- 错误率:分类错误的样本数占样本总数的比例;

- 精度:分类正确的样本数占样本总数的比例。

1.2. 查准率、查全率与F1
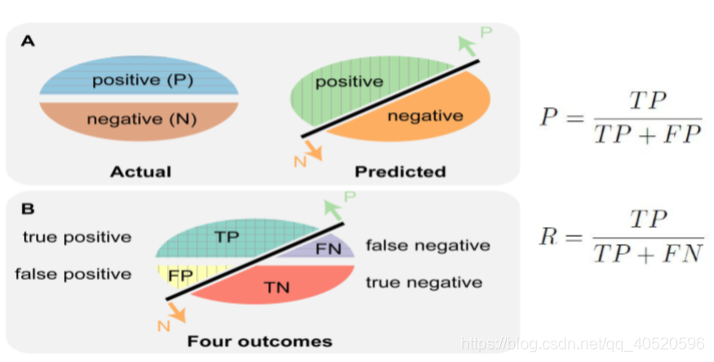
有时候错误率和精度不能满足任务要求,对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例TP(true positive) 、假正例FP(false positive) 、真反倒TN(true negative) 、假反例FN(false negative) 四种情形:
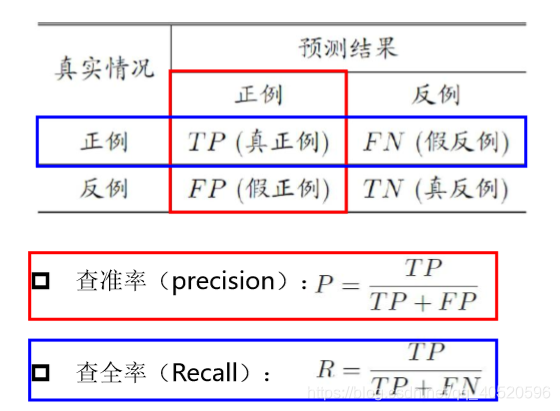
如下图可知道,查准率 和 查全率 是一对矛盾的度量,成负相关关系,一般来说,此消彼长。
通常只有在一些简单任务中,才可能使查全率和查准率都很高,通过 P-R 图可以直观地显示出学习器在样本总体上的查全率、 查准率情况,根据 P-R 图可以看出模型优劣,若一个学习器的 P-R 曲线被另一学习器的曲线完全"包住" , 则可断言后者的性能优于前者,如下图:
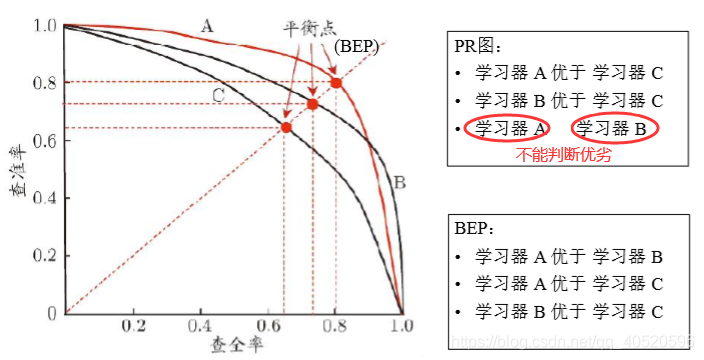
对于学习器A与学习器B不能判断时,这时引入"平衡点 " (Break-Event Point,简称 BEP),它是"查准率=查全率"时的取值,这样就可以判断优劣了,但 BEP 还是过于简化了些,更常用的是 F1 度量:
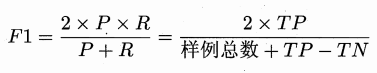
F1 度量的一般形式:Fβ,表达出对查准率/查全率的不同偏好。

1.3. ROC与AUC

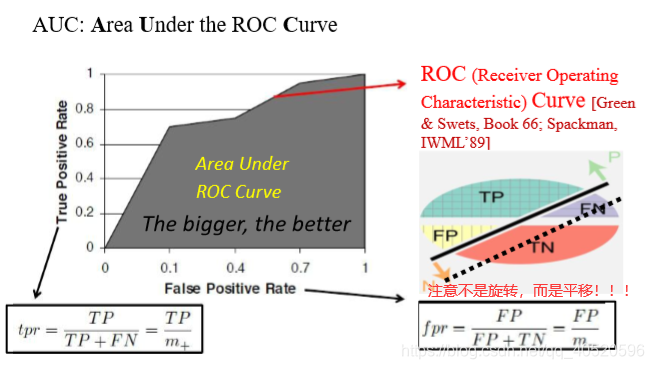
之前说的查准率 和 查全率 是一对矛盾的度量,成负相关关系。而现在的TPR 和 FPR 则是成正相关关系。进行学习器的比较时, 与 P-R 图相似, 若一个学习器的 ROC 曲线被另一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;若两个学习器的 ROC 曲线发生交叉,则难以断言两者孰优孰劣。此时如果一定要进行比较, 则较为合理的判据是比较 ROC 曲线下的面积,即 AUC (Area Under ROC Curve)。
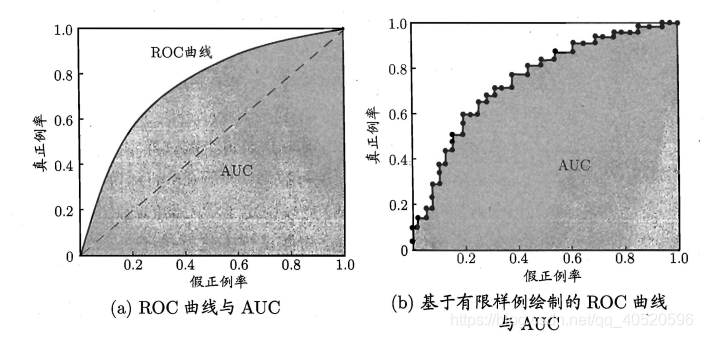
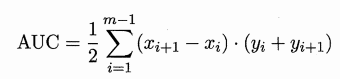
Q1:因为对于横平竖直的标准折线用,为什么不是 ?
A1:给定 m+个正例和 m- 个反例,因此设前一个标记点坐标为 (x,y) , 当前若为真正例,则对应标记点的坐标为 (x, );当前若为假正例,则对应标记点的坐标为 ( ,y) ,然后用线段连接相邻点即得;但是图(b)中的ROC曲线只是个特例罢了,因为当模型对某个正样例和某个反样例给出的预测值相同时,便会划分新增两个样例为正例,于是其中一个分类正确一个分类错误,那么下一个点的坐标为 ,此时ROC曲线中便会出现斜线,这时候 不成立。
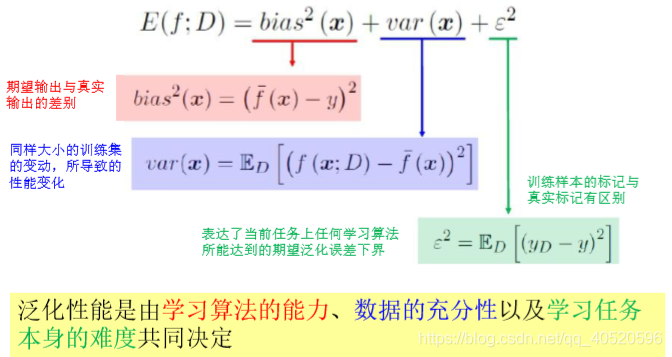
2. 方差、噪声和偏差
2.1. 泛化误差概念
对测试样本 x,令 yD 为 x 在数据集中的标记, y 为 x 的真实标记, f(x; D) 为训练集 D 上学得模型 f 在 x 上的预测输出:
- 期望:
- 方差:
- 噪声:
- 偏差:
泛化误差:
推导:为什么 ?
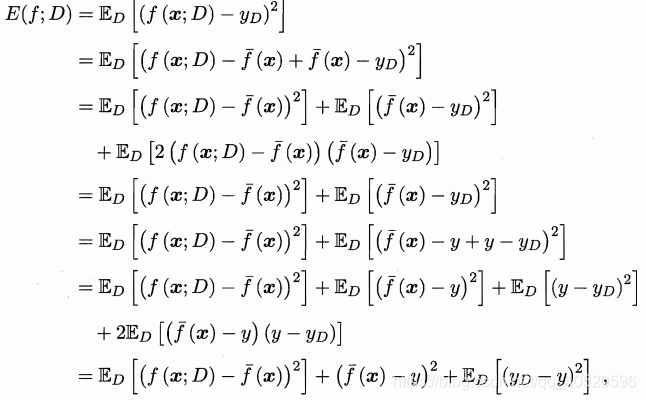

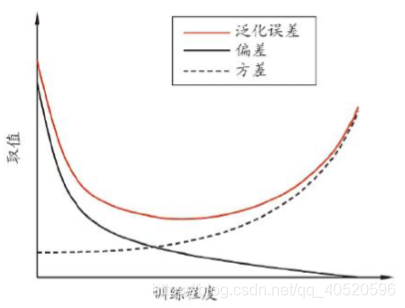
2.2. 偏差方差窘境
一般来说,偏差与方差是有冲突的,即 偏差一方差窘境(bias-variance dilemma)。 如下图所示,假定我们能控制学习算法的训练程度,则:
- 训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以便学习器产生显著变化,此时偏差主导了泛化错误率;
- 随着训练进行,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;
- 在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动又都会导致学习器发生显著变化。