什么是URL? ,URL的组成部分有哪些?
URL, 统一资源定位符, 是互联网上标准资源的地址;
组成分为四部分:1.协议部分,2.域名部分,3.资源路径部分,4.查询参数部分
简单叙述常用响应状态码
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
请简述浏览器访问HTTP服务器的过程。
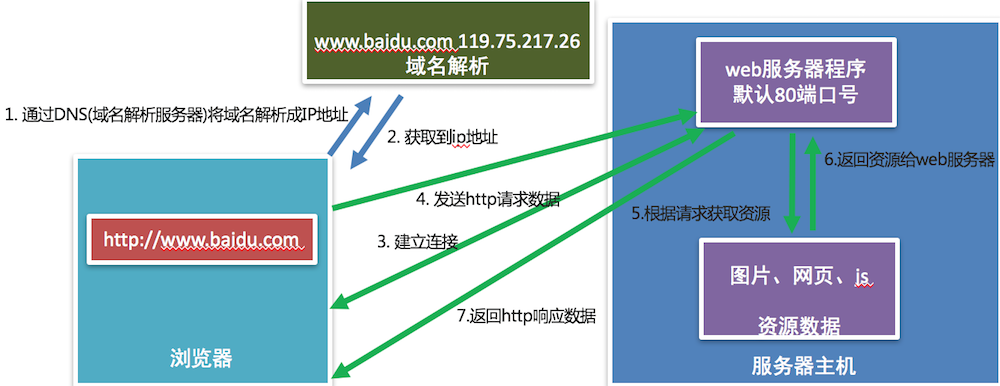
1. 用户输入网址.
2. 浏览器请求DNS服务器, 获取域名对应的IP地址.
3. 请求连接该IP地址服务器.
4. 发送资源请求. (HTTP协议)
5. web服务器接收到请求, 并解析请求, 判断用户意图.
6. 获取用户想要的资源.
7. 将资源返回给web服务器程序.
8. web服务器程序将资源数据通过网络发送给浏览器.
9. 浏览器解析请求的数据并且完成网页数据的显示.
简述HTTP协议格式。
请求报文格式:
1. 请求行:
实例:GET /test/tupian/cm HTTP/1.1
分成三部分:
(1)GET:HTTP请求方式
(2)/test/tupian/cm:请求Web服务器的目录地址(或者指令)
(3)HTTP/1.1: HTTP协议及其版本
2. 请求头: 包含了定义http传输时的操作参数
实例: Accept:text/xml
3. 空行
4. 请求体: 需要向服务器发送的请求信息(GET方式没有请求体)
响应报文格式:
1. 响应行:
实例: HTTP/1.1 200 OK
分成三部分:
(1)HTTP/1.1: HTTP协议及其版本
(2)200: 响应状态码
(3)OK: 状态描述
2. 响应头:和请求头相似, 包含了定义http传输时的操作参数
实例: Content-Type: text/html; charset=utf-8
3. 空行
4. 响应体: 需要呈献给用户的信息
send和recv的原理是什么?
send:要想发数据,必须得通过网卡发送数据,应用程序是无法直接通过网卡发送数据的,它需要调用操作系统接口,也就是说,应用程序把发送的数据先写入到发送缓冲区(内存中的一片空间),再由操作系统控制网卡把发送缓冲区的数据发送给服务端网卡 。
recv:应用软件无法直接通过网卡接收数据,它需要调用操作系统接口,由操作系统通过网卡接收数据,把接收的数据写入到接收缓冲区(内存中的一片空间),应用程序再从接收缓存区获取客户端发送的数据。
习题
1. 开辟两个子线程
2. 线程1设置为死循环, 每隔1秒打印一次"线程信息"
3. 线程2接收一个整数类型参数, 进程2循环的次数即为传入的整形数字, 每个1秒循环一次
4. 等子线程2结束的时候, 子线程1也跟着结束
import threading
def func1():
while True:
print("func1")
time.sleep(1)
def func2():
for i in range(n):
print("func2")
time.sleep(1)
if __name__ == '__main__':
t1 = threading.Thread(target=func1)
t2 = threading.Thread(target=func2)
t1..setDaemon(True)
t1.start()
t2.start()
t2.join()
举例说明 HTTP 需要用在什么场景下,web 服务器的作用是什么?
1.HTTP 一般用于浏览器和 web 服务器之间的网页相关资源传输。比如我们上网时打开网页时。
2.web服务器的主要作用就是 为浏览器提供所需的网页资源
HTTP 和 TCP 的关系。
TCP对应于传输层,HTTP对应于应用层,从本质上来说,二者没有可比性。
Http协议是建立在TCP协议基础之上的,当浏览器需要从服务器获取网页数据的时候,会发出一次Http请求。Http会通过TCP建立起一个到服务器的连接通道,当本次请求需要的数据完毕后,Http会立即将TCP连接断开,这个过程是很短的。所以Http连接是一种短连接,是一种无状态的连接。
TCP是底层协议,定义的是数据传输和连接方式的规范。
HTTP是应用层协议,定义的是传输数据的内容的规范。
HTTP协议中的数据是利用TCP协议传输的,所以支持HTTP就一定支持TCP。
请分别说出 协议部分、主机域名部分、资源路径部分、查询部分。
请根据URL 的结构 分析网址`https://docs.python.org/3/search.html?q=asyncio&check_keywords=yes&area=default`
协议部分是 https://
主机部分是 docs.python.org
资源路径部分是 /3/search.html
查询部分是 ?q=asyncio&check_keywords=yes&area=default
请求方式的get和post有什么区别和联系
联系:GET和POST是HTTP协议中的两种发送请求的方法。HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。
区别:GET是用来向获取服务器信息的,请求报文传输的信息只是用于描述所需资源的参数,返回的信息才是数据本身;
POST是用来向服务器传递数据的,其请求报文传递的信息就是数据本身,返回的报文只是操作的结果。
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。GET参数通过URL传递,POST放在Request body中。
习题
在返回指定页面数据的web服务器中,假如已经获取到了recv_request,那么请你实现从当前到封装好响应报文的代码
try:
with open("static" + request_path, "rb") as file:
file_data = file.read()
except Exception as e:
# 2.1 指定文件资源找不到, 返回404 页面
with open("static/error.html", "rb") as file:
file_data = file.read()
response_line = "HTTP/1.1 404 Not Found\r\n"
response_head = "Server: NBWS/1.0\r\n"
response_body = file_data
response_data = (response_line + response_head + "\r\n").encode("utf-8") + response_body
new_socket.send(response_data)
else:
# 2.2 构建响应报文,发送给浏览器
response_line = "HTTP/1.1 200 OK\r\n"
response_head = "Server: NBWS/1.0\r\n"
response_body = file_data
response_data = (response_line + response_head + "\r\n").encode("utf-8") + response_body
new_socket.send(response_data)
finally:
new_socket.close()