一、从HTTP说起
我是通信专业出身的,以前在学校里系统的学过通信原理(樊昌信版)、信号与系统、数字信号处理等等许多关于通信方面的课程。虽然记得当时做了一些实验,但是总感觉和实际的应用扯不上关系。
后来随着工作的关系,不断的应用这些知识才慢慢的有了感觉。但是,当我想深入的了解HTTP时,从网上或者书店搜资料时发现了这么个状况:
网上的资料太杂、权威资料太难、正式资料太少
书籍就那几本:TCP/IP详解卷1和2(很厚)、HTTP权威指南(很厚)、HTTP/2基础教程(很厚)……
如果整天抱着这些书去学习,我想对于已经工作了的人效果一定不咋地,生命这么短暂还这么宝贵,如此浪费时间实属不该。
下面我将根据我的理解尽量用最朴实无华的语言说明所有关于HTTP的问题。当然,如果要想再深入的研究HTTP,还真得花些时间看看上面的书籍。
首先,一次完整的HTTP请求:(借鉴网上的一张图)
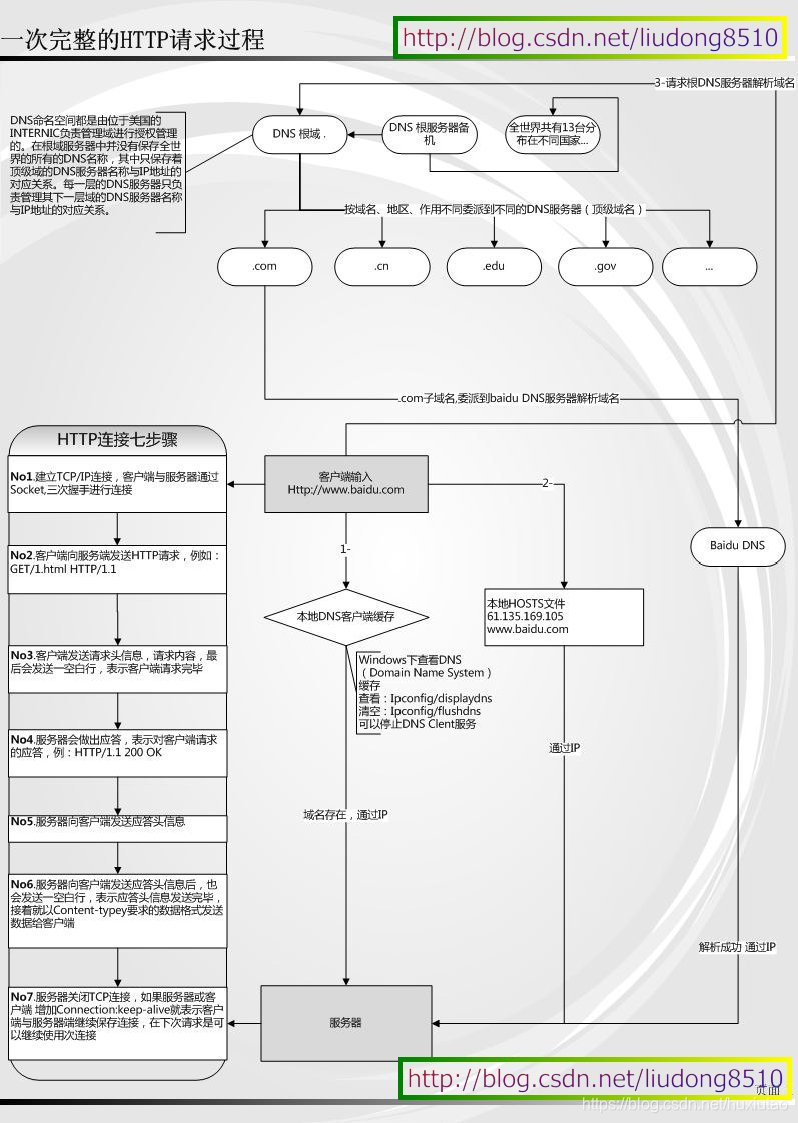
说明:客户端输入www.baidu.com,Enter后,上图中右半部分都是在讲如何找到服务器地址;左半部分(HTTP连接7步骤)讲的是找到服务器后如何通信。(https://blog.csdn.net/gdutxiaoxu/article/details/97885526)
怎么理解HTTP协议是无状态的无连接的的协议:https://www.jianshu.com/p/30744fbd1f01
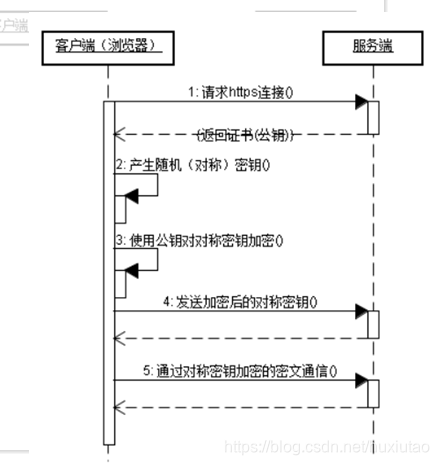
简单的理解HTTPS:
HTTPS相当于HTTP的安全版本了,是在http的基础之上加上ssl(Secure Socket Layer),端口号是443,是由SSL+Http协议构建的可进行加密传输、身份认证的网络协议。https在客户端(浏览器)与服务端(网站)传输加密的数据大概经历一下流程:
(1) 客户端将自己的has算法和加密算法发给服务器
(2) 服务器接收到客户端发来的加密算法和has算法,取出自己的加密算法与has算法,并将自己的身份信息以证书的形式发送给客户端,该证书信息包括公钥,网站地址,预计颁发机构等
(3) 客户端收到服务器发来的证书(即公钥),开始验证证书的合法性,如果证书信任,则生成一串随机的字符串数字作为私钥,并将私钥(密文)用证书(服务器的公钥)进行加密,发送给服务器
(4) 服务器收到客户端发来的数据之后,通过服务器自己的私钥进行解密客户端发来的数据(客户端的私钥),(这样双方都拥有私钥)再进行hash检验,如果结果一致,则将客户端发来的字符串(第3个步骤发送过来的字符串)通过加密发送给客户端
(5) 客户端解密,如果一致的话,就使用之前客户端随机生成的字符串进行对称加密算法进行加密.
1、HTTP的历史简介
先说重点,对于HTTP的历史,我大概总结如下:
- HTTP协议始于三⼗年前蒂姆·伯纳斯-李的⼀篇论⽂;
- HTTP/0.9是个简单的⽂本协议,只能获取⽂本资源;
- HTTP/1.0确⽴了⼤部分现在使⽤的技术,但它不是正式标准;
- HTTP/1.1是⽬前互联⽹上使⽤最⼴泛的协议,功能也非常完善;
- HTTP/2基于Google的SPDY协议,注重性能改善,但还未普及;
- HTTP/3基于Google的QUIC协议,是将来的发展方向。
有时间就看一下以下链接,不再赘述:
https://www.sohu.com/a/220049433_661013
值得一提的是,HTTP/1.1发布之后,整个互联⽹世界呈现出了爆发式的增⻓,度过了⼗多年的“快乐时光”,更涌现出了Facebook、Twitter、淘宝、京东等互联⽹新贵。
这期间也出现了⼀些对HTTP不满的意见,主要就是连接慢,⽆法跟上迅猛发展的互联⽹,但HTTP/1.1标准⼀直“岿然不动”,无奈之下⼈们只好发明各式各样的“⼩花招”来缓解这些问题,⽐如以前常⻅的切图、JS合并等⽹⻚优化⼿段。终于有⼀天,搜索巨头Google忍不住了,决定“揭竿⽽起”,就像⻢云说的“如果银⾏不改变,我们就改变银⾏”。那么,它是怎么“造反”的呢?Google⾸先开发了⾃⼰的浏览器Chrome,然后推出了新的SPDY协议,并在Chrome⾥应⽤于⾃家的服务器,如同⼗多年前的⽹景与微软⼀样,从实际的⽤户⽅来“倒逼”HTTP协议的变⾰,这也开启了第⼆次的“浏览器⼤战”。历史再次重演,不过这次的胜利者是Google,Chrome⽬前的全球的占有率超过了60%。“挟⽤户以号令天下”,Google借此顺势把SPDY推上了标准的宝座,互联⽹标准化组织以SPDY为基础开始制定新版本的HTTP协议,最终在2015年发布了HTTP/2,RFC编号7540。
HTTP/2的制定充分考虑了现今互联⽹的现状:宽带、移动、不安全,在⾼度兼容HTTP/1.1的同时在性能改善⽅⾯做了很⼤努⼒,主要的特点有:
- ⼆进制协议,不再是纯⽂本;
- 可发起多个请求,废弃了1.1⾥的管道;
- 使⽤专⽤算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,“事实上”要求加密通信。
在HTTP/2还处于草案之时,Google⼜发明了⼀个新的协议,叫做QUIC,⽽且还是相同的“套路”,继续在Chrome和⾃家服务器⾥试验着“玩”,依托它的庞⼤⽤户量和数据量,持续地推动QUIC协议成为互联⽹上的“既成事实”。
在去年,也就是2018年,互联⽹标准化组织IETF提议将“HTTP over QUIC”更名为“HTTP/3”并获得批准,HTTP/3正式进⼊了标准化制订阶段,也许两三年后就会正式发布,到时候我们很可能会跳过HTTP/2直接进⼊HTTP/3。
最后,虽然HTTP/2到今天已经四岁,也衍⽣出了gRPC等新协议,但由于HTTP/1.1实在是太过经典和强势,⽬前它的普及率还⽐较低,⼤多数⽹站使⽤的仍然还是20年前的HTTP/1.1。
2、HTTP到底是什么HTTP又不是什么,如果面试官问该如何回答?
HTTP,HyperText Transfer Protocol,是超文本传输协议的真正含义是:HTTP是⼀个在计算机世界⾥专⻔在两点之间传输⽂字、图⽚、⾳频、视频等超⽂本数据的约定和规范。
先看重点总结:
- HTTP是⼀个⽤在计算机世界⾥的协议,它确⽴了⼀种计算机之间交流通信的规范,以及相关的各种控制和错误处理⽅式。
- HTTP专⻔⽤来在两点之间传输数据,不能⽤于⼴播、寻址或路由。
- HTTP传输的是⽂字、图⽚、⾳频、视频等超⽂本数据。
- HTTP是构建互联⽹的重要基础技术,它没有实体,依赖许多其他的技术来实现,但同时许多技术也都依赖于它。
因为HTTP是⼀个协议,是⼀种计算机间通信的规范,所以它不存在“单独的实体”。但HTTP⼜与应⽤程序、操作系统、Web服务器密切相关,在它们之间的通信过程中存在,而且是⼀种“动态的存在”,是发生在网络连接、传输超⽂本数据时的⼀个“动态过程”。
HTTP不是互联网:互联网(Internet)是遍布于全球的许多⽹络互相连接⽽形成的⼀个巨⼤的国际⽹络,在它上⾯存放着各式各样的资源,也对应着各式各样的协议,例如超⽂本资源使⽤HTTP,普通⽂件使⽤FTP,电⼦邮件使⽤SMTP和POP3等。
HTTP不是HTML,HTTP不是⼀个孤⽴的协议。在互联⽹世界⾥,HTTP通常跑在TCP/IP协议栈之上,依靠IP协议实现寻址和路由、TCP协议实现可靠数据传输、DNS协议实现域名查找、SSL/TLS协议实现安全通信。此外,还有⼀些协议依赖于HTTP,例如WebSocket、HTTPDNS等。这些协议相互交织,构成了⼀个协议⽹,⽽HTTP则处于中⼼地位。
3、HTTP世界全览(上):与HTTP相关的各种概念
先说重点:
- 互联⽹上绝⼤部分资源都使⽤HTTP协议传输;
- 浏览器是HTTP协议⾥的请求⽅,即User Agent;
- 服务器是HTTP协议⾥的应答⽅,常⽤的有Apache和Nginx;
- CDN位于浏览器和服务器之间,主要起到缓存加速的作⽤;
- 爬⾍是另⼀类User Agent,是⾃动访问⽹络资源的程序。
关于爬虫:HTTP协议没有规定⽤户代理后⾯必须是“真正的⼈类”,它也完全可以是“机器⼈”,这些“机器⼈”的正式名称就叫做“爬 ⾍”(Crawler),实际上是⼀种可以⾃动访问Web资源的应⽤程序。 “爬⾍”这个名字⾮常形象,它们就像是⼀只只不知疲倦的、⾟勤的蚂蚁,在⽆边⽆际的⽹络上爬来爬去,不停地在⽹站间奔 ⾛,搜集抓取各种信息。据估计,互联⽹上⾄少有50%的流量都是由爬⾍产⽣的,某些特定领域的⽐例还会更⾼,也就是说,如果你的⽹站今天的访问 量是⼗万,那么⾥⾯⾄少有五六万是爬⾍机器⼈,⽽不是真实的⽤户。
绝⼤多数是由各⼤搜索引擎“放”出来的,抓取⽹⻚存⼊庞⼤的数据库,再建⽴关键字索引,这样我们才能够在搜索引擎中快速 地搜索到互联⽹⻆落⾥的⻚⾯。
爬⾍也有不好的⼀⾯,它会过度消耗⽹络资源,占⽤服务器和带宽,影响⽹站对真实数据的分析,甚⾄导致敏感信息泄漏。所 以,⼜出现了“反爬⾍”技术,通过各种⼿段来限制爬⾍。其中⼀项就是“君⼦协定”robots.txt,约定哪些该爬,哪些不该爬。
⽆论是“爬⾍”还是“反爬⾍”,⽤到的基本技术都是两个,⼀个是HTTP,另⼀个就是HTML。
关于WAF:是近⼏年⽐较“⽕”的⼀个词,意思是“⽹络应⽤防⽕墙”。与硬件“防⽕墙”类似,它是应⽤层⾯的“防⽕墙”,专⻔检测HTTP 流量,是防护Web应⽤的安全技术。 WAF通常位于Web服务器之前,可以阻⽌如SQL注⼊、跨站脚本等攻击,⽬前应⽤较多的⼀个开源项⽬是ModSecurity,它能 够完全集成进Apache或Nginx。
Linux中的wget、curl等命令行工具也是基于http的,所以也是一种用户代理。
4、HTTP世界全览(下):与HTTP相关的各种协议
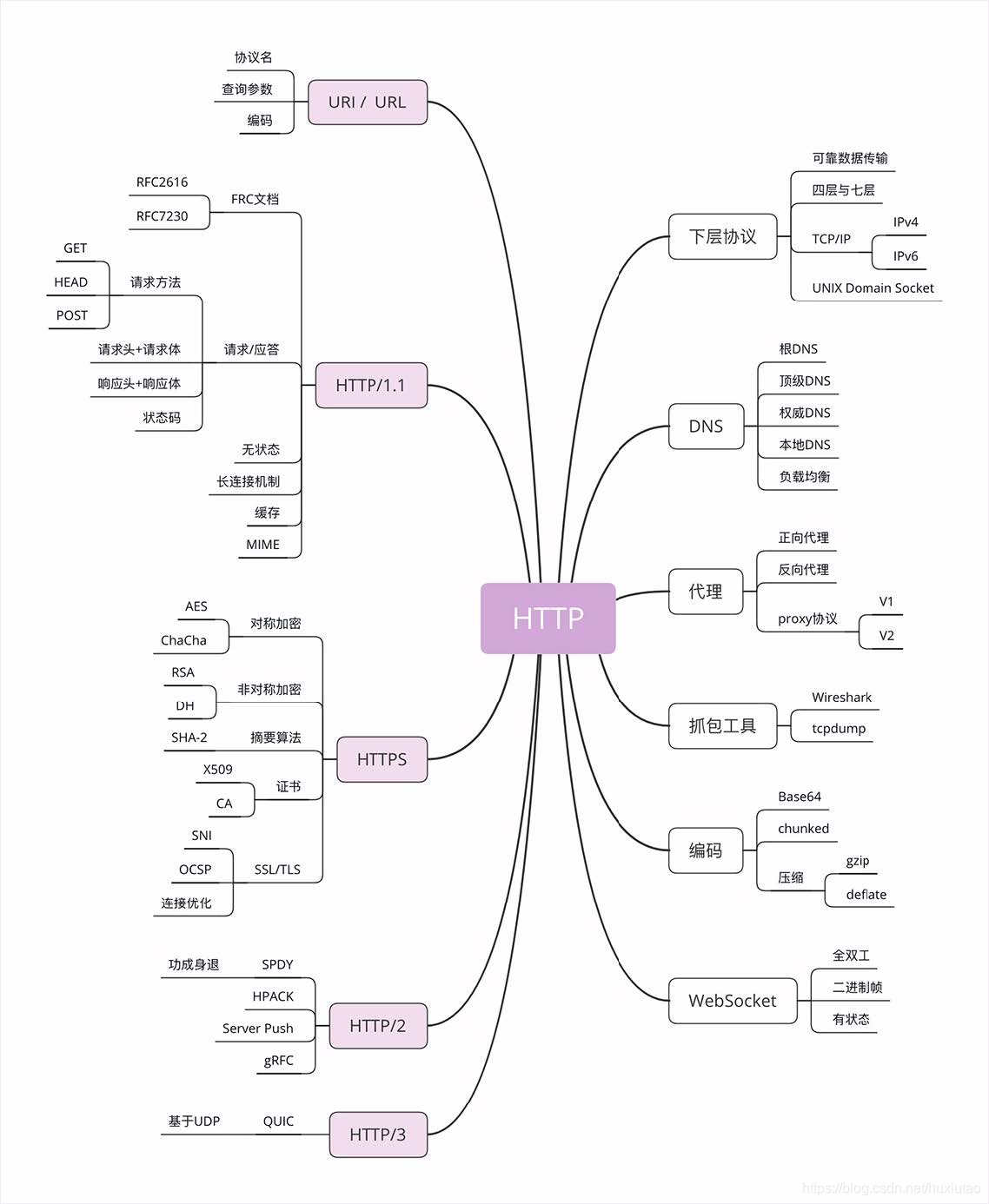
不得不提的TCP/IP协议:
TCP/IP协议实际上是⼀系列⽹络通信协议的统称,其中最核⼼的两个协议是TCP和IP,其他的还有UDP、ICMP、ARP等等, 共同构成了⼀个复杂但有层次的协议栈。
这个协议栈有四层,最上层是“应⽤层”,最下层是“链接层”,TCP和IP则在中间:TCP属于“传输层”,IP属于“⽹际层”。
IP协议是“Internet Protocol”的缩写,主要⽬的是解决寻址和路由问题,以及如何在两点间传送数据包
现在我们使⽤的IP协议⼤多数是v4版,地址是四个⽤“.”分隔的数字,例如“192.168.0.1”,总共有2^32,⼤约42亿个可以分配 的地址。看上去好像很多,但互联⽹的快速发展让地址的分配管理很快就“捉襟⻅肘”。所以,就⼜出现了v6版,使⽤8组“:”分 隔的数字作为地址,容量扩⼤了很多,有2^128个,在未来的⼏⼗年⾥应该是⾜够⽤了。
TCP协议是“Transmission Control Protocol”的缩写,意思是“传输控制协议”,它位于IP协议之上,基于IP协议提供可靠的、字节流形式的通信,是HTTP协议得以实现的基础。
“可靠”是指保证数据不丢失,“字节流”是指保证数据完整,所以在TCP协议的两端可以如同操作⽂件⼀样访问传输的数据,就像是读写在⼀个密闭的管道里“流动”的字节。
HTTP是⼀个"传输协议",但它不关⼼寻址、路由、数据完整性等传输细节,⽽要求这些⼯作都由下层来处理。因为互联⽹上最流⾏的是TCP/IP协议,⽽它刚好满⾜HTTP的要求,所以互联⽹上的HTTP协议就运⾏在了TCP/IP 上,HTTP也就可以更准确地称为“HTTP over TCP/IP”。
为什么会出现DNS?为什么要域名解析?
在TCP/IP协议中使⽤IP地址来标识计算机,数字形式的地址对于计算机来说是⽅便了,但对于⼈类来说却既难以记忆⼜难以输⼊。于是“域名系统”(Domain Name System)出现了,⽤有意义的名字来作为IP地址的等价替代。设想⼀下,你是愿意 记“95.211.80.227”这样枯燥的数字,还是“nginx.org”这样的词组呢? 在DNS中,“域名”(Domain Name)⼜称为“主机名”(Host),为了更好地标记不同国家或组织的主机,让名字更好记,所以,被设计成了⼀个有层次的结构。域名⽤“.”分隔成多个单词,级别从左到右逐级升⾼,最右边的被称为“顶级域名”。对于顶级域名,可能你随⼝就能说出⼏个, 例如表示商业公司的“com”、表示教育机构的“edu”,表示国家的“cn”“uk”等.
但想要使⽤TCP/IP协议来通信仍然要使⽤IP地址,所以需要把域名做⼀个转换,“映射”到它的真实IP,这就是所谓的“域名解析”。
目前全世界有13组根DNS服务器,下面再有许多的顶级DNS、权威DNS和更小的本地DNS,逐层递归地实现域名查询。
HTTP协议中并没有明确要求必须使⽤DNS,但实际上为了⽅便访问互联⽹上的Web服务器,通常都会使⽤DNS来定位或标记 主机名,间接地把DNS与HTTP绑在了⼀起。
有了TCP/IP和DNS,是不是我们就可以任意访问⽹络上的资源了呢?
其实还不行,DNS和IP地址只是标记了互联⽹上的主机,但主机上有那么多⽂本、图⽚、⻚⾯,到底要找哪⼀个呢?
所以就出现了URI(Uniform Resource Identifier),中⽂名称是 统⼀资源标识符,使⽤它就能够唯⼀地标记互联⽹上资源。
URI另⼀个更常⽤的表现形式是URL(Uniform Resource Locator), 统⼀资源定位符,也就是我们俗称的“⽹址”,它实际上 是URI的⼀个⼦集,不过因为这两者⼏乎是相同的,差异不⼤,所以通常不会做严格的区分。
HTTPS:“HTTP over SSL/TLS”:也就是运⾏在SSL/TLS协议上的HTTP。注意它的名字,这⾥是SSL/TLS,而不是TCP/IP,它是⼀个负责加密通信的安全协议,建⽴在TCP/IP之上,所以也是个可靠的传输协议,可以被用作HTTP的下层。
SSL/TLS:
SSL的全称是“Secure Socket Layer”,由⽹景公司发明,当发展到3.0时被标准化,改名为TLS,即“Transport Layer Security”,但由于历史的原因还是有很多⼈称之为SSL/TLS,或者直接简称为SSL。
SSL使⽤了许多密码学最先进的研究成果,综合了对称加密、⾮对称加密、摘要算法、数字签名、数字证书等技术,能够在不 安全的环境中为通信的双⽅创建出⼀个秘密的、安全的传输通道,为HTTP套上⼀副坚固的盔甲。
你可以在今后上⽹时留⼼看⼀下浏览器地址栏,如果有⼀个⼩锁头标志,那就表明⽹站启⽤了安全的HTTPS协议,⽽URI⾥的 协议名,也从“http”变成了“https”。
代理:
代理(Proxy)是HTTP协议中请求⽅和应答⽅中间的⼀个环节,作为“中转站”,既可以转发客户端的请求,也可以转发服务器 的应答。
代理有很多的种类,常⻅的有:
- 匿名代理:完全“隐匿”了被代理的机器,外界看到的只是代理服务器;
- 透明代理:顾名思义,它在传输过程中是“透明开放”的,外界既知道代理,也知道客户端;
- 正向代理:靠近客户端,代表客户端向服务器发送请求;
- 反向代理:靠近服务器端,代表服务器响应客户端的请求;
由于代理在传输过程中插⼊了⼀个“中间层”,所以可以在这个环节做很多有意思的事情,⽐如:
- 负载均衡:把访问请求均匀分散到多台机器,实现访问集群化;
- 内容缓存:暂存上下⾏的数据,减轻后端的压⼒;
- 安全防护:隐匿IP,使⽤WAF等⼯具抵御⽹络攻击,保护被代理的机器;
- 数据处理:提供压缩、加密等额外的功能。
关于HTTP的代理还有⼀个特殊的“代理协议”(proxy protocol),它由知名的代理软件HAProxy制订.
总结:
- TCP/IP是⽹络世界最常⽤的协议,HTTP通常运⾏在TCP/IP提供的可靠传输基础上;
- DNS域名是IP地址的等价替代,需要⽤域名解析实现到IP地址的映射;
- URI是⽤来标记互联⽹上资源的⼀个名字,由“协议名+主机名+路径”构成,俗称URL;
- HTTPS相当于“HTTP+SSL/TLS+TCP/IP”,为HTTP套了⼀个安全的外壳;
- 代理是HTTP传输过程中的“中转站”,可以实现缓存加速、负载均衡等功能。
5、常说的“四层”和“七层”到底是什么“五层”“六层”哪去了
TCP/IP 协议是⼀个“有层次的协议栈”。在⼯作中你⼀定经常听别⼈谈起什么“四层负载均衡”“七层负载均衡”,什么“⼆层转发”“三层路由”,那么你真正理解这些层次的 含义吗?⽹络分层的知识教科书上都有,但很多都是“泛泛⽽谈”,只有“学术价值”,于是就容易和实际应⽤“脱节”,造成的后果就是“似懂⾮懂”,真正⽤的时候往往会“⼀头雾⽔”。
TCP/IP当初的设计者真的是⾮常聪明,创造性地提出了“分层”的概念,把复杂的⽹络通信划分出多个层次,再给每⼀个层次分 配不同的职责,层次内只专⼼做⾃⼰的事情就好,⽤“分⽽治之”的思想把⼀个“⼤麻烦”拆分成了数个“⼩麻烦”,从⽽解决了⽹络 通信的难题。
第一个网络分层模型:TCP/IP模型
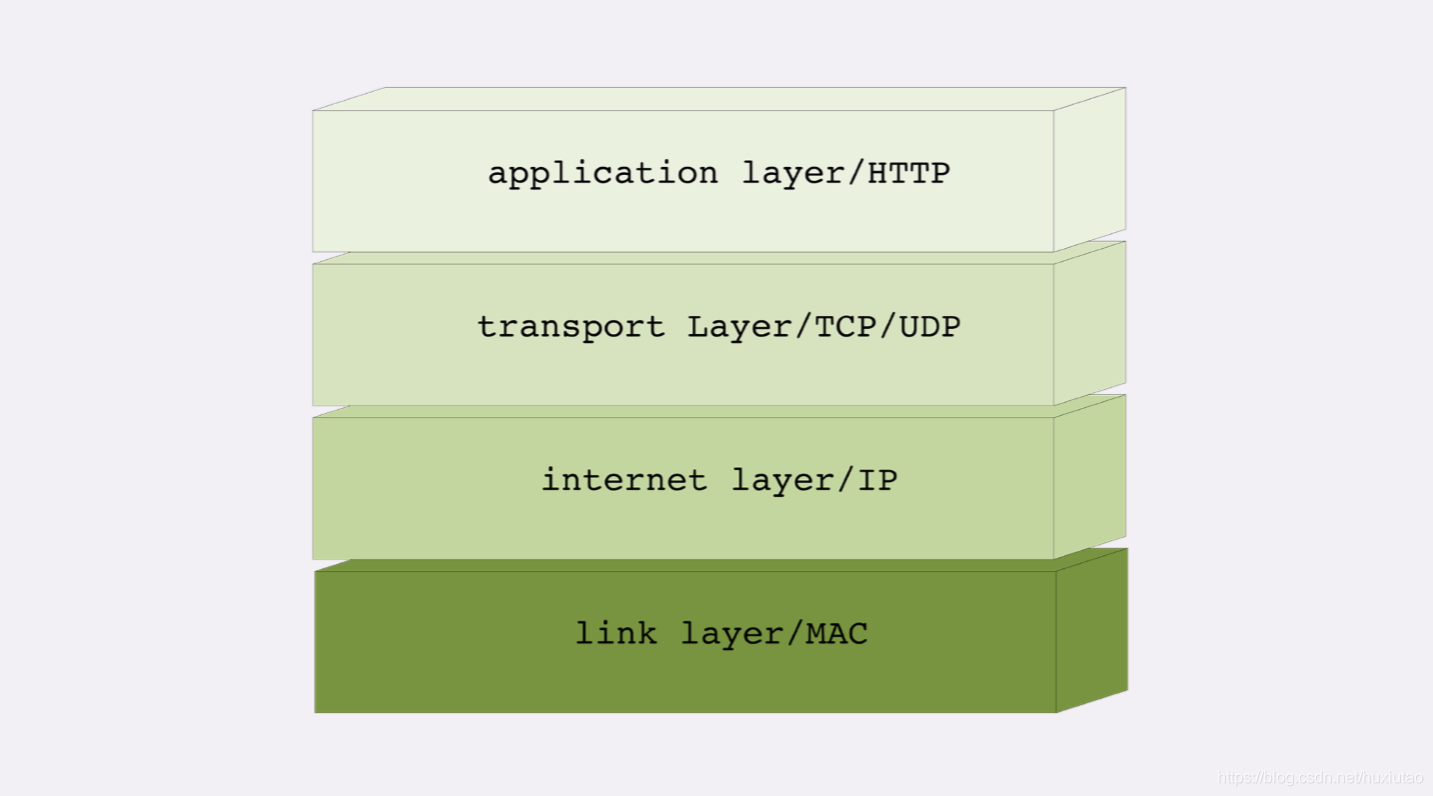
TCP/IP协议总共有四层,就像搭积⽊⼀样,每⼀层需要下层的⽀撑,同时⼜⽀撑着上层,任何⼀层被抽掉都可能会导致整个 协议栈坍塌
第⼀层叫“链接层”(link layer),负责在以太⽹、WiFi这样的底层⽹络上发送原始数据包,⼯作在⽹卡这个层次,使⽤MAC地 址来标记⽹络上的设备,所以有时候也叫MAC层。
第⼆层叫“⽹际层”或者“⽹络互连层”(internet layer),IP协议就处在这⼀层。因为IP协议定义了“IP地址”的概念,所以就可以 在“链接层”的基础上,⽤IP地址取代MAC地址,把许许多多的局域⽹、⼴域⽹连接成⼀个虚拟的巨⼤⽹络,在这个⽹络⾥找设 备时只要把IP地址再“翻译”成MAC地址就可以了。
第三层叫“传输层”(transport layer),这个层次协议的职责是保证数据在IP地址标记的两点之间“可靠”地传输,是TCP协议工作的层次,另外还有它的⼀个“⼩伙伴”UDP。 TCP是⼀个有状态的协议,需要先与对⽅建⽴连接然后才能发送数据,⽽且保证数据不丢失不重复。⽽UDP则⽐较简单,它 ⽆状态,不⽤事先建⽴连接就可以任意发送数据,但不保证数据⼀定会发到对⽅。两个协议的另⼀个重要区别在于数据的形 式。TCP的数据是连续的“字节流”,有先后顺序,⽽UDP则是分散的⼩数据包,是顺序发,乱序收。
协议栈的第四层叫“应⽤层”(application layer),由于下⾯的三层把基础打得⾮常好,所以在这⼀层就“百花⻬放”了,有各种 ⾯向具体应⽤的协议。例如Telnet、SSH、FTP、SMTP等等,当然还有我们的HTTP。
MAC层的传输单位是帧(frame),IP层的传输单位是包(packet),TCP层的传输单位是段(segment),HTTP的传输单 位则是消息或报⽂(message)。但这些名词并没有什么本质的区分,可以统称为数据包。
第二个网络分层模型:OSI模型
OSI,全称是“开放式系统互联通信参考模型”(Open System Interconnection Reference Model)
TCP/IP发明于1970年代,当时除了它还有很多其他的⽹络协议,整个⽹络世界⽐较混乱。 这个时候国际标准组织(ISO)注意到了这种现象,感觉“野路⼦”太多,就想要来个“⼤⼀统”。于是设计出了⼀个新的⽹络分层 模型,想⽤这个新框架来统⼀既存的各种⽹络协议。
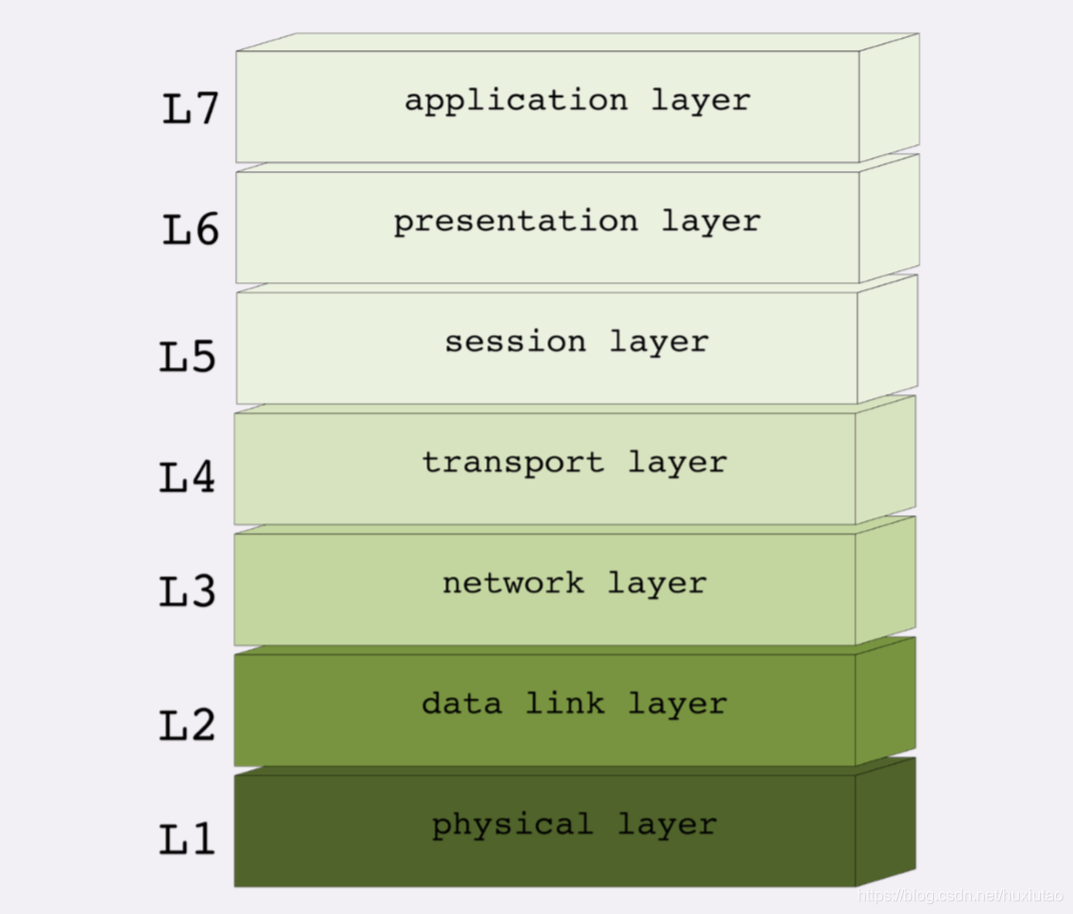
- 第⼀层:物理层,⽹络的物理形式,例如电缆、光纤、⽹卡、集线器等等;
- 第⼆层:数据链路层,它基本相当于TCP/IP的链接层;
- 第三层:⽹络层,相当于TCP/IP⾥的⽹际层;
- 第四层:传输层,相当于TCP/IP⾥的传输层;
- 第五层:会话层,维护⽹络中的连接状态,即保持会话和同步;
- 第六层:表示层,把数据转换为合适、可理解的语法和语义;
- 第七层:应⽤层,⾯向具体的应⽤传输数据
OSI分层模型在 发布的时候就明确地表明是⼀个“参考”,不是强制标准。在OSI模型之后,“四层”“七层”这样的说法就逐渐流⾏开了。不过在实际⼯作中你⼀定要注意,这种说法只 是“理论上”的层次,并不是与现实完全对应。
两个分层模型的映射关系:
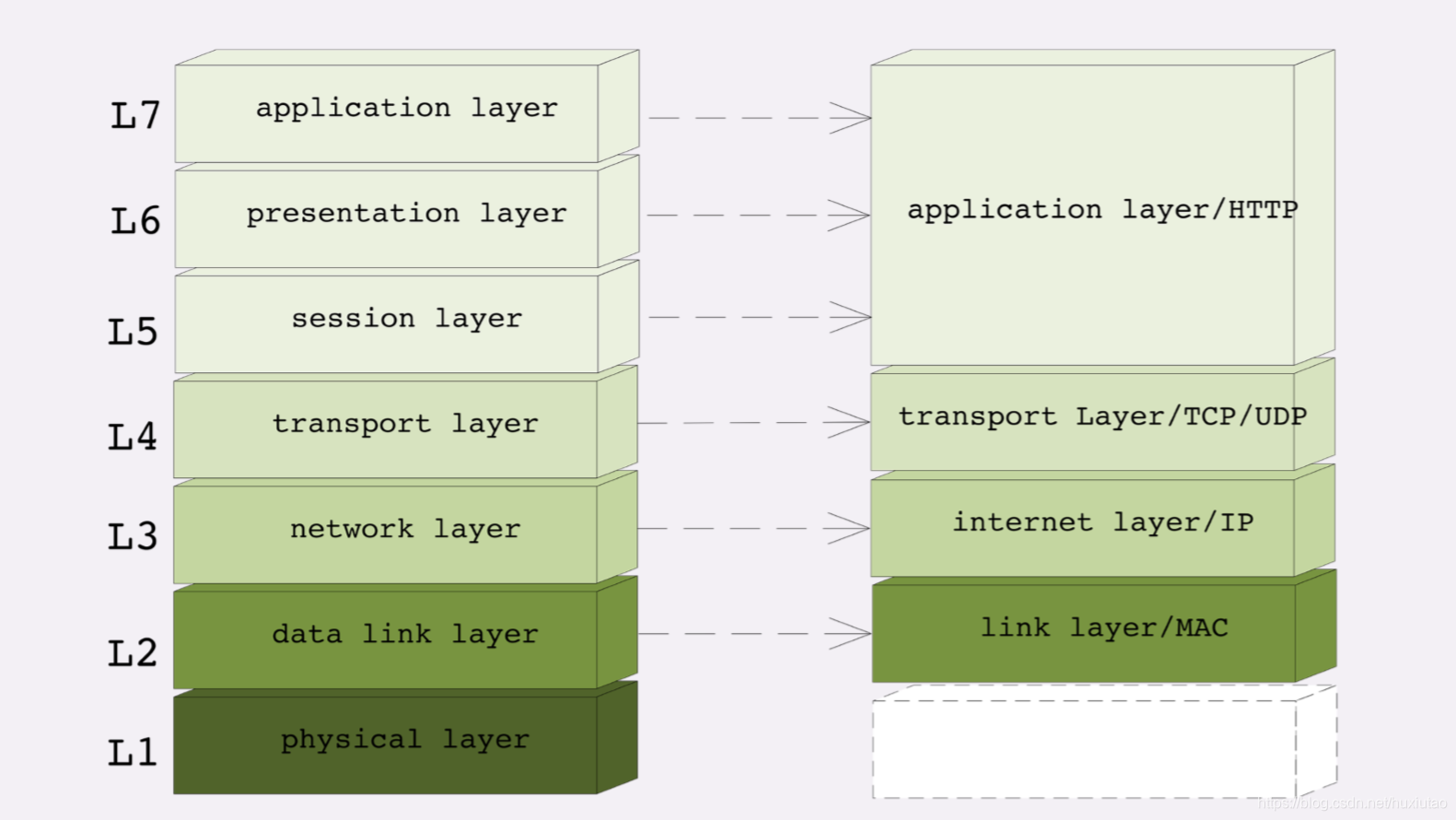
- 第⼀层:物理层,TCP/IP⾥⽆对应;
- 第⼆层:数据链路层,对应TCP/IP的链接层;
- 第三层:⽹络层,对应TCP/IP的⽹际层
- 第四层:传输层,对应TCP/IP的传输层;
- 第五、六、七层:统⼀对应到TCP/IP的应⽤层。
OSI的分层模型在四层以上分的太细,⽽TCP/IP实际应⽤时的会话管理、编码转换、压缩等和具体应⽤经常联系的很紧密,很 难分开。例如,HTTP协议就同时包含了连接管理和数据格式定义。
所谓的“四层负载均衡”就是指⼯作在传输层上,基于TCP/IP协议的特性,例如IP地址、端⼝号等实现对后端服务器的负载均 衡。
所谓的“七层负载均衡”就是指⼯作在应⽤层上,看到的是HTTP协议,解析HTTP报⽂⾥的URI、主机名、资源类型等数据,再 ⽤适当的策略转发给后端服务器。
总结:
- TCP/IP分为四层,核⼼是⼆层的IP和三层的TCP,HTTP在第四层
- OSI分为七层,基本对应TCP/IP,TCP在第四层,HTTP在第七层
- OSI可以映射到TCP/IP,但这期间⼀、五、六层消失
- ⽇常交流的时候我们通常使⽤OSI模型,⽤四层、七层等术语
- HTTP利⽤TCP/IP协议栈逐层打包再拆包,实现了数据传输,但下⾯的细节并不可⻅。
有⼀个辨别四层和七层⽐较好的(但不是绝对的)⼩窍⻔,“两个凡是”:凡是由操作系统负责处理的就是四层或四层以下,否 则,凡是需要由应⽤程序(也就是你⾃⼰写代码)负责处理的就是七层。
6、域名里有哪些门道
先说重点:
- 1.域名使⽤字符串来代替IP地址,⽅便⽤户记忆,本质上⼀个名字空间系统;
- 2.DNS就像是我们现实世界⾥的电话本、查号台,统管着互联⽹世界⾥的所有⽹站,是⼀个“超级⼤管家”;
- 3.DNS是⼀个树状的分布式查询系统,但为了提⾼查询效率,外围有多级的缓存;
- 4.使⽤DNS可以实现基于域名的负载均衡,既可以在内⽹,也可以在外⽹。
IP协议的职责是“⽹际互连”,它在MAC层之上,使⽤IP地址把MAC编号转换成了四位数字,这就对物理⽹卡的MAC地址做了 ⼀层抽象,发展出了许多的“新玩法”。 在IP地址之上再来⼀次抽象,把数字形式的IP地址转换成更有意义更好记的名字,在字符串 的层⾯上再增加“新玩法”。于是,DNS域名系统就这么出现了。
例如域名“time.mytest.org”,这⾥的“org”就是顶级域名,“mytest”是⼆级域名,“time”则是主机名。使⽤这 个域名,DNS就会把它转换成相应的IP地址,你就可以访问这个网站了。
域名不仅能够代替IP地址,还有许多其他的⽤途。
在Apache、Nginx这样的Web服务器⾥,域名可以⽤来标识虚拟主机,决定由哪个虚拟主机来对外提供服务,⽐如在Nginx⾥ 就会使⽤“server_name”指令。
域名本质上还是个名字空间系统,使⽤多级域名就可以划分出不同的国家、地区、组织、公司、部⻔,每个域名都是独⼀⽆⼆ 的,可以作为⼀种身份的标识。
就像IP地址必须转换成MAC地址才能访问主机⼀样,域名也必须要转换成IP地址,这个过程就是“域名解析”。
⽬前全世界有⼏亿个站点,有⼏⼗亿⽹⺠,⽽每天⽹络上发⽣的HTTP流量更是天⽂数字。这些请求绝⼤多数都是基于域名来 访问⽹站的,所以DNS就成了互联⽹的重要基础设施,必须要保证域名解析稳定可靠、快速⾼效。
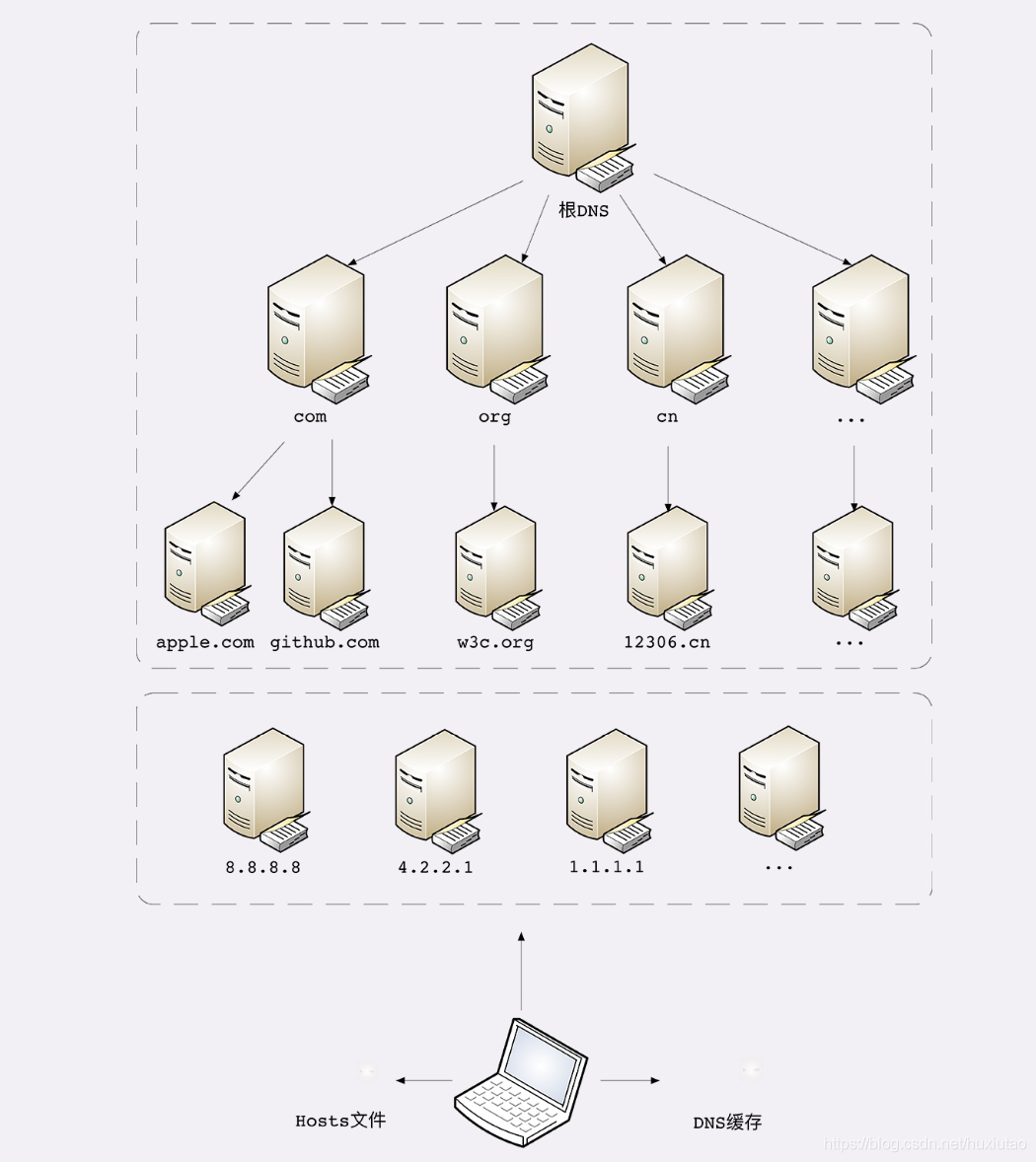
DNS的核⼼系统是⼀个三层的树状、分布式服务,基本对应域名的结构:
- 根域名服务器(Root DNS Server)
管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的IP地址 - 顶级域名服务器(Top-level DNS Server)
管理各⾃域名下的权威域名服务器,⽐如com顶级域名服务器可以返回 apple.com域名服务器的IP地址; - 权威域名服务器(Authoritative DNS Server)
管理⾃⼰域名下主机的IP地址,⽐如apple.com权威域名服务器可以返回 www.apple.com的IP地址。

在这⾥根域名服务器是关键,它必须是众所周知的,否则下⾯的各级服务器就⽆从谈起了。⽬前全世界共有13组根域名服务 器,⼜有数百台的镜像,保证⼀定能够被访问到。
有了这个系统以后,任何⼀个域名都可以在这个树形结构⾥从顶⾄下进⾏查询,就好像是把域名从右到左顺序⾛了⼀遍,最终 就获得了域名对应的IP地址。
例如,你要访问“www.apple.com”,就要进⾏下⾯的三次查询:
- 访问根域名服务器,它会告诉你“com”顶级域名服务器的地址;
- 访问“com”顶级域名服务器,它再告诉你“apple.com”域名服务器的地址;
- 最后访问“apple.com”域名服务器,就得到了“www.apple.com”的地址.
虽然核⼼的DNS系统遍布全球,服务能⼒很强也很稳定,但如果全世界的⽹⺠都往这个系统⾥挤,即使不挤瘫痪了,访问速 度也会很慢。
所以在核⼼DNS系统之外,还有两种⼿段⽤来减轻域名解析的压⼒,并且能够更快地获取结果,基本思路就是“缓存”。
⾸先,许多⼤公司、⽹络运⾏商都会建⽴⾃⼰的DNS服务器,作为⽤户DNS查询的代理,代替⽤户访问核⼼DNS系统。这 些“野⽣”服务器被称为“⾮权威域名服务器”,可以缓存之前的查询结果,如果已经有了记录,就⽆需再向根服务器发起查询, 直接返回对应的IP地址。
这些DNS服务器的数量要⽐核⼼系统的服务器多很多,⽽且⼤多部署在离⽤户很近的地⽅。⽐较知名的DNS有Google 的“8.8.8.8”,Microsoft的“4.2.2.1”,还有CloudFlare的“1.1.1.1”等等。
其次,操作系统⾥也会对DNS解析结果做缓存,如果你之前访问过“www.apple.com”,那么下⼀次在浏览器⾥再输⼊这个⽹址 的时候就不会再跑到DNS那⾥去问了,直接在操作系统⾥就可以拿到IP地址。
另外,操作系统⾥还有⼀个特殊的“主机映射”⽂件,通常是⼀个可编辑的⽂本,在Linux⾥是“/etc/hosts”,在Windows⾥是“C:\WINDOWS\system32\drivers\etc\hosts”,如果操作系统在缓存⾥找不到DNS记录,就会找这个⽂件。
有了上⾯的“野⽣”DNS服务器、操作系统缓存和hosts⽂件后,很多域名解析的⼯作就都不⽤“跋⼭涉⽔”了,直接在本地或本机 就能解决,不仅⽅便了⽤户,也减轻了各级DNS服务器的压⼒,效率就⼤⼤提升了。
下⾯的这张图⽐较完整地表示了现在的DNS架构。
在Nginx⾥有这么⼀条配置指令“resolver”,它就是⽤来配置DNS服务器的,如果没有它,那么Nginx就⽆法查询域名对应的 IP,也就⽆法反向代理到外部的⽹站。
resolver 8.8.8.8 valid=30s; #指定Google的DNS,缓存30秒
域名的“新玩法”
有了域名,⼜有了可以稳定⼯作的解析系统,于是我们就可以实现⽐IP地址更多的“新玩法”了。
第⼀种,也是最简单的,“重定向”。因为域名代替了IP地址,所以可以让对外服务的域名不变,⽽主机的IP地址任意变动。当主机有情况需要下线、迁移时,可以更改DNS记录,让域名指向其他的机器。
⽐如,你有⼀台“buy.tv”的服务器要临时停机维护,那你就可以通知DNS服务器:“我这个buy.tv域名的地址变了啊,原先是 1.2.3.4,现在是5.6.7.8,麻烦你改⼀下。”DNS于是就修改内部的IP地址映射关系,之后再有访问buy.tv的请求就不⾛1.2.3.4 这台主机,改由5.6.7.8来处理,这样就可以保证业务服务不中断。
第二种,因为域名是⼀个名字空间,所以可以使⽤bind9等开源软件搭建⼀个在内部使⽤的DNS,作为名字服务器。这样我们开发的各种内部服务就都⽤域名来标记,⽐如数据库服务都⽤域名“mysql.inner.app”,商品服务都⽤“goods.inner.app”,发起⽹络通信时也就不必再使⽤写死的IP地址了,可以直接⽤域名,⽽且这种⽅式也兼具了第⼀种“玩法”的优势。
第三种,“玩法”包含了前两种,也就是基于域名实现的负载均衡。
这种“玩法”也有两种⽅式,两种⽅式可以混⽤。
- 第⼀种⽅式,因为域名解析可以返回多个IP地址,所以⼀个域名可以对应多台主机,客户端收到多个IP地址后,就可以⾃⼰使⽤轮询算法依次向服务器发起请求,实现负载均衡。
- 第⼆种⽅式,域名解析可以配置内部的策略,返回离客户端最近的主机,或者返回当前服务质量最好的主机,这样在DNS端 把请求分发到不同的服务器,实现负载均衡。
前⾯我们说的都是可信的DNS,如果有⼀些不怀好意的DNS,那么它也可以在域名这⽅⾯“做⼿脚”,弄⼀些⽐较“恶意”的“玩 法”,举两个例⼦:
- “域名屏蔽”,对域名直接不解析,返回错误,让你⽆法拿到IP地址,也就⽆法访问⽹站;
- “域名劫持”,也叫“域名污染”,你要访问A⽹站,但DNS给了你B⽹站。
域名总长度限制在253个字符以内,而每一级域名长度不超过63个字符。域名是大小写无关的。
7、自己动手,搭建HTTP实验环境
8、键入网址再按下回车,后面究竟发生了什么
9、HTTP报文是什么样子的
10、应该如何理解请求方法
11、你能写出正确的网址吗
二、TCP原理
1、TCP协议到底是怎么解决网络传输不可靠的呢?
其中最为关键的一点是利用了滑动窗口协议,维持发送方/接受方缓冲区,其实该协议很简单,但是你要从书本上来看原理那就非常复杂了。发送方和接受方各自维持一个缓冲区,互相商定包的重传机制、ACK机制等等。这里通过图说一下基本原理:
(1) 没有滑动窗口时:
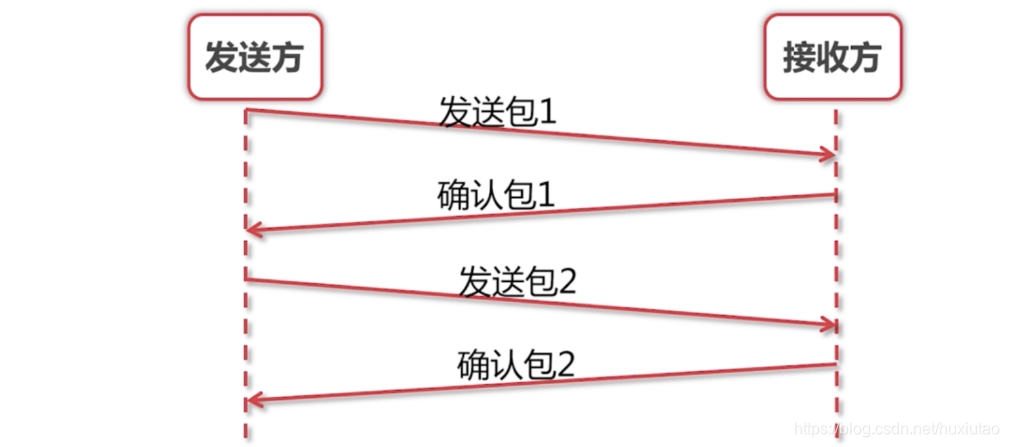
发送一次,等待确认一次,然后再发下一个。
很显然,这种方式的吞吐量很小。
(2) 改进方案——一次发多个数据包,一起等待确认
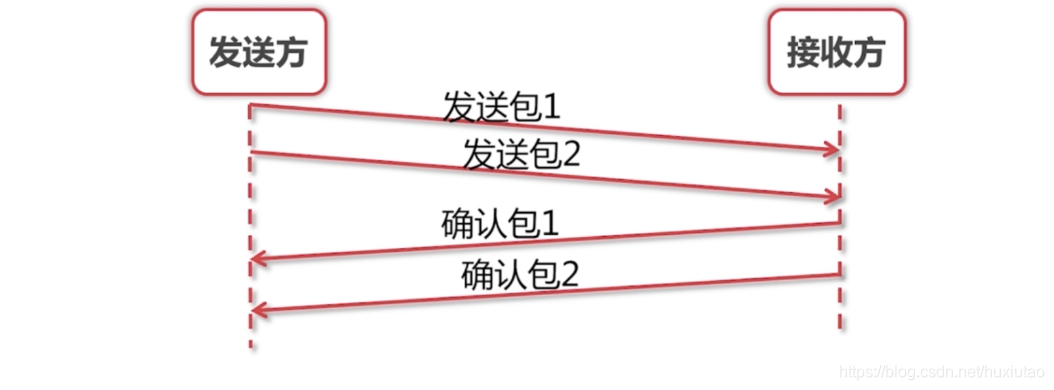
正常情况下:
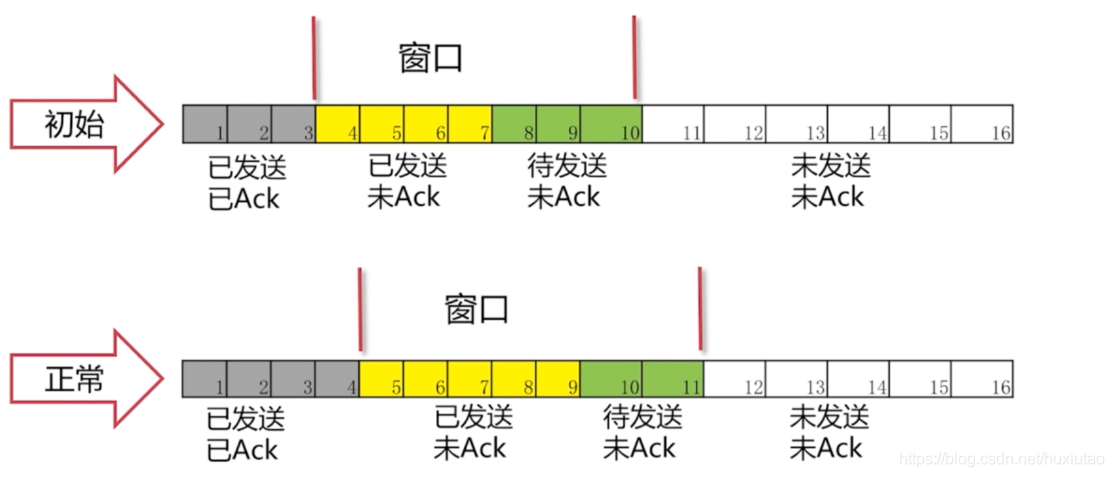
从上图可以看出,正常情况下,4收到ACK后,窗口向右移动一格,也就是将11读进发送内存准备发送。
如果出现丢Ack包的情况:
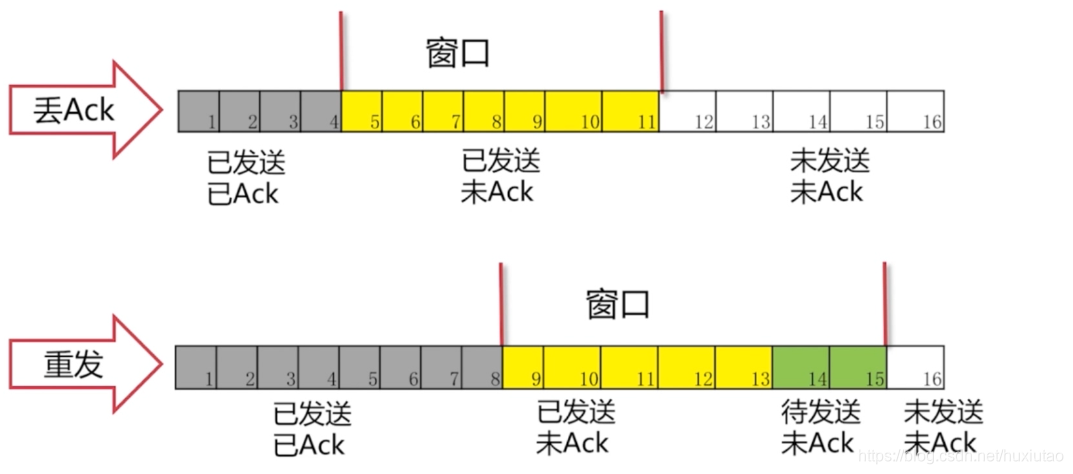
从上图可以看出,如果此时5的ACK没有收到,那么6、7、8、9、10、11都会等着,因为这是有顺序的返回ACK,这样就保证了顺序性。
如果等了一会5还是没有收到ACK,那么就会重发,重发后5收到ACK后,同时也收到了6/7/8的ACK,那么窗口会继续向右移动。
滑动窗口不仅仅用于流量控制,还可以进行拥塞控制,而且窗口大小在传输过程中是可以调整的,而且大小为0是合法的(如果你发的太快,我来不及收,我就会设置为0,你就先不要发了,等我处理完后,我再给你一个新的窗口大小,你再发)。
2、通过网络抓包可以更深的理解