今天,想要学习爬虫,因此度娘一tong搜,爬虫是个啥?爬虫能做啥?咋用爬虫做个好玩的东西?
于是我搜了爬虫游戏,结果,我我我我。。。真的发现了好玩的东西。。、
此处手动 [[ 笑哭 ]]
好玩的就是它,狂点此处
一个爬虫游戏,你要对爬虫有那么点理解,就好比我,emmmm,就真的是只有一点理解,,,

进去了,然后开始游戏,按照步骤开始游戏,结果发现好像你朋友给你发的整人的对不对,我也感觉是,然后。。。这时爬虫游戏啊,老铁,想什么呢,你还能就一直输么
作为程序猿,当然是写程序解决了,没有什么是一段代码解决不了的,有的话就两段
而且要写的是一个爬虫程序
基本流程
1)分析页面
F12 查看网页源代码,分析发现,需要输入的数字就在 <h3> 标签里面,so,我们只需要把这个数取出来,放 url 最后,组成新的 url 然后进行访问,循环此步骤,就代替了人为操作了,至于循环到最后会发生什么,试了才知道,嘿嘿

2)发起请求:
通过url向服务器发起request请求,请求可以包含额外的header信息。
使用 第三方库 requests,发送 get 请求,并且为了模拟浏览器行为,添加一个头部字段 User-Agent
num = 93147 # 第一次让输入的数字
url = 'http://www.heibanke.com/lesson/crawler_ex00/' + str(num)
r = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
})
3)获取响应内容 :
响应内容通过返回值获取,可以打印查看获取的信息
text = r.text
print(text)
4)解析内容
先找到 <h3> 所在的行,这个网页比较简单,只有一个 <h3> 标签,获取到之后再获取出数字,更新 url ,再次发送请求,重复以上步骤
获取数字:利用正则表达式
[\u4e00-\u9fa5]+ 匹配的是至少一个汉字,紧接着是五个数字,然后一个 . ,然后0个或者多个空格,然后匹配0个或者多个汉字,最后匹配0个或者多个 .
其中 ret[0] 是 <h3> 标签所在行
ret[1] 是正则表达式中第一对括号中匹配到的内容
ret[2] 是正则表达式中第二对括号中匹配到的内容,就是我们需要的数字
ret = re.match(R'(<h3>[\u4e00-\u9fa5]+)(\d{5}).\s*[\u4e00-\u9fa5]*.*</h3>', h3)
num = ret[2]
在此期间打印一些友好的提示信息,如果这个是有尽头的,只需要最后一步做个特殊处理即可
完整代码:
import requests
import re
num = 25338 # 第一次让输入的数字
count = 0
try:
while True:
url = 'http://www.heibanke.com/lesson/crawler_ex00/' + str(num)
r = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
})
print(url, '第 ', count, ' 次')
count += 1
text = r.text # text就是得到的html页面内容
pos1 = text.find("<h3>") # 分析可知,这个简单的网页只有一个<h3>标签
pos2 = text.find("</h3>") # 数字就在这个标签内,因此先将标签内容获取到
h3 = text[pos1:pos2+5]
ret = re.match(R'(<h3>[\u4e00-\u9fa5]+)(\d{5}).\s*[\u4e00-\u9fa5]*.*</h3>', h3)
num = ret[2]
except ValueError as e:
print('value error: ', e);
finally:
print(text)
最终正则表达式匹配错处,异常 TypeError,捕捉异常,并最后将 html 内容打印出来,观察
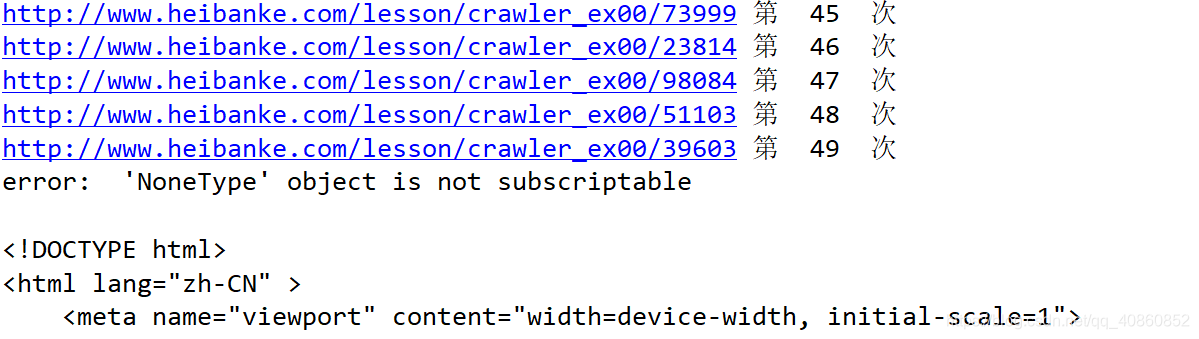
正则表达式匹配错处,原来是因为这。。。。哈哈哈哈哈哈,这个游戏真好玩,爬虫真好玩!

将最后一次的 url 直接输入到浏览器中我们看结果:过关成功!

