文章目录
说明
本文基于【MySQL】,使用命令行,实战讲解【SQL】的基本语法。
本文会主要围绕MySQL,讲解很多重要的语法,他们不算很难的知识,但也比最基本的insert、delete、update、select要高级很多了。阅读之前,请务必学会基本的增删改查(可以阅读下面的“必知必会”文章)。
必知必会
《MySQL系统命令+基础查询总结》
《MySQL命令行测试基础SQL》
建表
打算设计一个学生成绩表,只有语数英三门学科,另有总分。
学生则有自己的id和name,name不允许为空,id不允许为空且设为唯一的主键。
mysql> create table stu_grade
-> (id int primary key not null,
-> name varchar(10) not null,
-> chinese int default 0,
-> math int default 0,
-> english int default 0,
-> grade int default 0);
Query OK, 0 rows affected (0.92 sec)
我们查询test数据库中的所有数据表,能够找到新创建的表。
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| stu_grade |
+----------------+
1 row in set (0.00 sec)
全表查询,表元素集合为空:
mysql> select * from stu_grade;
Empty set (0.01 sec)
多行插入
上一次我们选择了一行一行的插入,但这样很麻烦也很低效,所以我们这里选择一次性插入六个数据元组,完成表内容的初始化:
mysql> insert into stu_grade values
-> ('1', 'Sam', '120', '145', '145', '410'),
-> ('2', 'Bob', '88', '98', '95', '278'),
-> ('3', 'Steven', '130', '108', '135', '373'),
-> ('4', 'Amy', '120', '120', '120', '360'),
-> ('5', 'Eleven', '130', '130', '140', '400'),
-> ('6', 'Miffy', '125', '145', '135', '405');
Query OK, 6 rows affected (0.39 sec)
Records: 6 Duplicates: 0 Warnings: 0
全表查询,可以看到我们初始化后的数据:
mysql> select * from stu_grade;
+----+--------+---------+------+---------+-------+
| id | name | chinese | math | english | grade |
+----+--------+---------+------+---------+-------+
| 1 | Sam | 120 | 145 | 145 | 410 |
| 2 | Bob | 88 | 98 | 95 | 278 |
| 3 | Steven | 130 | 108 | 135 | 373 |
| 4 | Amy | 120 | 120 | 120 | 360 |
| 5 | Eleven | 130 | 130 | 140 | 400 |
| 6 | Miffy | 125 | 145 | 135 | 405 |
+----+--------+---------+------+---------+-------+
6 rows in set (0.00 sec)
LIMIT语句
SELECT TOP、LIMIT、ROWNUM 三种SQL语法都能实现查询部分数据,它们使用效果基本相同,但实际上是不同数据库的查询语句。下面以 SELECT TOP 语句为例,先讲解语法本身再分别说明。
SELECT TOP 子句用于规定要返回的记录的数目,对于拥有数千+条记录的大型表来说,是非常有用的。
- SQL Server 支持 SELECT TOP 语法。
SELECT TOP number|percent column_name(s) FROM table_name; - MySQL 不支持 SELECT TOP 语句,但支持 LIMIT 语句来选取指定的条数数据。
SELECT column_name(s) FROM table_name LIMIT number; - Oracle 不支持 SELECT TOP 语句,但支持 ROWNUM 语句来选取指定的条数数据。
SELECT column_name(s) FROM table_name WHERE ROWNUM <= number;
我们使用MySQL的LIMIT语句查询上面的数据表,只查前5条数据:
mysql> select * from stu_grade limit 5;
+----+--------+---------+------+---------+-------+
| id | name | chinese | math | english | grade |
+----+--------+---------+------+---------+-------+
| 1 | Sam | 120 | 145 | 145 | 410 |
| 2 | Bob | 88 | 98 | 95 | 278 |
| 3 | Steven | 130 | 108 | 135 | 373 |
| 4 | Amy | 120 | 120 | 120 | 360 |
| 5 | Eleven | 130 | 130 | 140 | 400 |
+----+--------+---------+------+---------+-------+
5 rows in set (0.00 sec)
创建新表
我们建立一张新的表,用于表示学生的个人信息,为后面的演示做准备。
mysql> create table stu_info
-> (id int primary key not null,
-> name varchar(10) not null,
-> age int not null,
-> email varchar(20),
-> country varchar(10));
Query OK, 0 rows affected (0.70 sec)
mysql> select * from stu_info;
Empty set (0.00 sec)
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| stu_grade |
| stu_info |
+----------------+
2 rows in set (0.00 sec)
完成表数据的初始化,这部分的数据有在参考原先的第一张表,做到了学生id、name这两个同名属性二者一一对应(人工完成):
mysql> insert into stu_info
-> values('1', 'Sam', '19', '[email protected]', 'China'),
-> ('2', 'Bob', '20', '[email protected]', 'USA'),
-> ('3', 'Steven', '21', '[email protected]', 'UK'),
-> ('4', 'Amy', '19', '[email protected]', 'China'),
-> ('5', 'Eleven', '20', '[email protected]', 'China'),
-> ('6', 'Miffy', '24', '[email protected]', 'Japan');
Query OK, 6 rows affected (0.43 sec)
Records: 6 Duplicates: 0 Warnings: 0
使用全表查询做检验:
mysql> select * from stu_info;
+----+----------+-----+---------------------+---------+
| id | name | age | email | country |
+----+----------+-----+---------------------+---------+
| 1 | Sam | 19 | 123456789@qq.com | China |
| 2 | Bob | 20 | bobbob@gmail.com | USA |
| 3 | Steven | 21 | steven521@gmail.com | UK |
| 4 | Amy | 19 | amy20205205@163.com | China |
| 5 | Eleven | 20 | 11more11@163.com | China |
| 6 | Miffy | 24 | miffy521@126.com | Japan |
+----+----------+-----+---------------------+---------+
6 rows in set (0.00 sec)
LIKE操作符
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
如果你学过 Visual Basic 那种语法诡异的语言,应该就了解过LIKE,这个LIKE有一些正则匹配的感觉,使用LIKE的SQL查询被称为“模糊查询”。
基本语法格式:
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
所以我们就可以使用LIKE语句对stu_info表中的email属性进行匹配,下面匹配的是含有gmail的串:
mysql> select * from stu_info
-> where email like '%gmail%';
+----+--------+-----+---------------------+---------+
| id | name | age | email | country |
+----+--------+-----+---------------------+---------+
| 2 | Bob | 20 | bobbob@gmail.com | USA |
| 3 | Steven | 21 | steven521@gmail.com | UK |
+----+--------+-----+---------------------+---------+
2 rows in set (0.00 sec)
有LIKE,自然就有NOT LIKE,下面匹配了不符合“左@右”结构(右可以为空,左必须含有’o’)的email,查询结果为符合要求的整个元组:
mysql> select * from stu_info
-> where email not like '%o%@%';
+----+----------+-----+---------------------+---------+
| id | name | age | email | country |
+----+----------+-----+---------------------+---------+
| 1 | Sam | 19 | 123456789@qq.com | China |
| 3 | Steven | 21 | steven521@gmail.com | UK |
| 4 | Amy | 19 | amy20205205@163.com | China |
| 6 | Miffy | 24 | miffy521@126.com | Japan |
+----+----------+-----+---------------------+---------+
4 rows in set (0.00 sec)
学过正则表达式的我们都知道,正则都是由通配符的,LIKE自然也有。这里的通配符可用于替代字符串中的任何其他字符(注意是其他,如果只是自身需要用’\'反斜杠进行转义)。
SQL支持如下通配符:
| 通配符 | 匹配对象 |
|---|---|
| % | 0 个或多个字符 |
| _ | 任一单个字符 |
| [charlist] | 指定字符列表中的任一单个字符 |
| [^charlist] or [!charlist] | 不在指定字符列表中的任一单个字符 |
注意[charlist]里面不必使用逗号等分隔符分隔,例如[AbC]即可。
IN操作符
我们可以在 WHERE 子句中使用 IN 操作符规定多个值作为选择范围。
IN操作符后面跟的是一个元组,这个括号并非代表范围,而是一种枚举得到的元组,所有取值都在其中。
如果你学过Java的enum,和Python的tuple,那就不难理解了。
下面的语句查询条件要求学生年龄是19岁或者21岁:
mysql> select * from stu_info
-> where age in(19, 21);
+----+----------+-----+---------------------+---------+
| id | name | age | email | country |
+----+----------+-----+---------------------+---------+
| 1 | Sam | 19 | 123456789@qq.com | China |
| 3 | Steven | 21 | steven521@gmail.com | UK |
| 4 | Amy | 19 | amy20205205@163.com | China |
+----+----------+-----+---------------------+---------+
3 rows in set (0.00 sec)
既然都说是或了,in括号里面的值也是可以穷举的,那就可以换成or,没毛病:
mysql> select * from stu_info
-> where age=19 or age=21;
+----+----------+-----+---------------------+---------+
| id | name | age | email | country |
+----+----------+-----+---------------------+---------+
| 1 | Sam | 19 | 123456789@qq.com | China |
| 3 | Steven | 21 | steven521@gmail.com | UK |
| 4 | Amy | 19 | amy20205205@163.com | China |
+----+----------+-----+---------------------+---------+
3 rows in set (0.00 sec)
BETWEEN操作符
BETWEEN 操作符用于选取介于两个值之间的数据范围内的值,这些值可以是数值、文本或者日期。
注意,特别是对于数值类型,between A and B 结构成立起码要求 A<=B。
基本语法格式:
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
在不同的数据库中,BETWEEN 会选取不同的区间,对区间端点的舍入有差别:
- 在某些数据库中,BETWEEN 选取开区间。
- 在某些数据库中,BETWEEN 选取闭区间。
- 在某些数据库中,BETWEEN 选取左闭右开区间。
其实标准SQL要求是开区间,但要记得MySQL是闭区间(两端点都取)。
于是,我们选取年龄在[19, 20]范围内的学生,也就是19 or 20,也就是in (19, 20):
mysql> select * from stu_info
-> where age between 19 and 20;
+----+----------+-----+---------------------+---------+
| id | name | age | email | country |
+----+----------+-----+---------------------+---------+
| 1 | Sam | 19 | 123456789@qq.com | China |
| 2 | Bob | 20 | bobbob@gmail.com | USA |
| 4 | Amy | 19 | amy20205205@163.com | China |
| 5 | Eleven | 20 | 11more11@163.com | China |
+----+----------+-----+---------------------+---------+
4 rows in set (0.00 sec)
BETWEEN可以与IN组合,也支持AND、OR,还可以使用NOT BETWEEN,这里就不举例了。
AS操作符
学习形式化逻辑查询语句的时候,我们就该知道,更名适用于表、属性等等很多很多东西。
使用AS可以完成更名,AS语句往往能降低编写SQL语句的编写复杂度和冗余度,也增强了可读性(可能吧)。
看下面的SQL语句就能知道,如果写的是stu_info.id, stu_info.name, … 这样的话,就太麻烦了,更名很方便的。(其实多表联合的时候,如果这个属性名只存在于某张表里,可以不使用’.’)
表级AS语法:
SELECT column_name(s)
FROM table_name AS alias_name;
列级AS语法:
SELECT column_name AS alias_name
FROM table_name;
注意在有些情况下,基于AS使用更名规则生成别名很有用:
- 在查询中涉及超过一个表
- 在查询中使用了函数
- 列名称很长或者可读性差
- 需要把两个列或者多个列结合在一起
下面以一个简单的多表查询做AS操作符的例子:
mysql> select i.id, i.name, i.email, g.chinese, g.math, g.english, g.grade
-> from stu_info as i, stu_grade as g
-> where i.id=g.id and i.name=g.name;
+----+--------+---------------------+---------+------+---------+-------+
| id | name | email | chinese | math | english | grade |
+----+--------+---------------------+---------+------+---------+-------+
| 1 | Sam | 123456789@qq.com | 120 | 145 | 145 | 410 |
| 2 | Bob | bobbob@gmail.com | 88 | 98 | 95 | 278 |
| 3 | Steven | steven521@gmail.com | 130 | 108 | 135 | 373 |
| 4 | Amy | amy20205205@163.com | 120 | 120 | 120 | 360 |
| 5 | Eleven | 11more11@163.com | 130 | 130 | 140 | 400 |
| 6 | Miffy | miffy521@126.com | 125 | 145 | 135 | 405 |
+----+--------+---------------------+---------+------+---------+-------+
6 rows in set (0.00 sec)
INSERT INTO SELECT语句
INSERT INTO 语句可以从一个表复制信息到另一个表。
标准的SQL语法格式是这样的:
SELECT *
INTO newtable [IN externaldb]
FROM table1;
下面的是有选择性的复制到新表中:
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;
可惜,MySQL 并不支持 SELECT INTO 语句,但支持 INSERT INTO SELECT,这个语法要求插入已存在的表中。
这种语法是这样的:
INSERT INTO table2
SELECT * FROM table1;
下面的是有选择性的复制到已存在的新表中:
INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;
其实MySQL貌似还可以这么搞:
CREATE TABLE new_table
AS
SELECT * FROM original_table
为了复制,我们需要创建一个简单的原表:
mysql> create table stu_best_friend (
-> id int primary key,
-> name varchar(10) not null,
-> friend_name varchar(10) not null);
Query OK, 0 rows affected (1.01 sec)
为其赋初值:
mysql> insert into stu_best_friend values
-> ('1', 'Sam', 'Tim'),
-> ('2', 'Bob', 'Sam'),
-> ('7', 'Kitty', 'Miffy');
Query OK, 3 rows affected (0.42 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into stu_best_friend values
-> ('3', 'Haris', 'Rookie');
Query OK, 1 row affected (0.41 sec)
先尝试手动创建表,再复制:
mysql> create table stu_best_friend_2 (
-> id int primary key,
-> name varchar(10) not null,
-> friend_name varchar(10) not null);
Query OK, 0 rows affected (0.91 sec)
mysql> insert into stu_best_friend_2
-> select * from stu_best_friend;
Query OK, 4 rows affected (0.44 sec)
Records: 4 Duplicates: 0 Warnings: 0
查查看:
mysql> select * from stu_best_friend_2;
+----+-------+-------------+
| id | name | friend_name |
+----+-------+-------------+
| 1 | Sam | Tim |
| 2 | Bob | Sam |
| 3 | Haris | Rookie |
| 7 | Kitty | Miffy |
+----+-------+-------------+
4 rows in set (0.00 sec)
我们删了这个表,再试试在表不存的时候的样子:
mysql> drop table stu_best_friend_2;
Query OK, 0 rows affected (0.55 sec)
mysql> insert into stu_best_friend_2
-> select * from stu_best_friend;
ERROR 1146 (42S02): Table 'test.stu_best_friend_2' doesn't exist
确实不行哇!
JOIN语句
JOIN 语句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
可以使用四种不同的JOIN语句:
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
得到的结果数:
- INNER JOIN <= MIN(LEFT JOIN, RIGHT JOIN)
- FULL JOIN >= MAX(LEFT JOIN, RIGHT JOIN)
- 当 INNER JOIN < MIN(LEFT JOIN, RIGHT JOIN) 时, FULL JOIN > MAX(LEFT JOIN, RIGHT JOIN)
这里还会涉及一个ON和WHERE的问题(使用JOIN时):
- ON 条件是在生成临时表时使用的条件,它不管 ON 中的条件是否为真,都会返回左边表中的记录。
- WHERE 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 LEFT JOIN 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
INNER JOIN
INNER JOIN 是最简单的JOIN语句。其实吧,INNER JOIN 与 JOIN 没啥区别,都是会从多个表中返回满足 JOIN 条件的所有行。
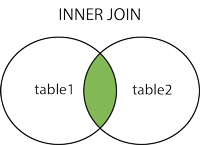
标准的SQL语法格式是这样的:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
或者是:
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;
下面是一个不加限制条件的 INNER JOIN:
mysql> select i.id, i.name, i.email, bf.id, bf.name, bf.friend_name
-> from stu_info as i
-> inner join stu_best_friend as bf;
+----+--------+---------------------+----+-------+-------------+
| id | name | email | id | name | friend_name |
+----+--------+---------------------+----+-------+-------------+
| 1 | Sam | 123456789@qq.com | 1 | Sam | Tim |
| 1 | Sam | 123456789@qq.com | 2 | Bob | Sam |
| 1 | Sam | 123456789@qq.com | 3 | Haris | Rookie |
| 1 | Sam | 123456789@qq.com | 7 | Kitty | Miffy |
| 2 | Bob | bobbob@gmail.com | 1 | Sam | Tim |
| 2 | Bob | bobbob@gmail.com | 2 | Bob | Sam |
| 2 | Bob | bobbob@gmail.com | 3 | Haris | Rookie |
| 2 | Bob | bobbob@gmail.com | 7 | Kitty | Miffy |
| 3 | Steven | steven521@gmail.com | 1 | Sam | Tim |
| 3 | Steven | steven521@gmail.com | 2 | Bob | Sam |
| 3 | Steven | steven521@gmail.com | 3 | Haris | Rookie |
| 3 | Steven | steven521@gmail.com | 7 | Kitty | Miffy |
| 4 | Amy | amy20205205@163.com | 1 | Sam | Tim |
| 4 | Amy | amy20205205@163.com | 2 | Bob | Sam |
| 4 | Amy | amy20205205@163.com | 3 | Haris | Rookie |
| 4 | Amy | amy20205205@163.com | 7 | Kitty | Miffy |
| 5 | Eleven | 11more11@163.com | 1 | Sam | Tim |
| 5 | Eleven | 11more11@163.com | 2 | Bob | Sam |
| 5 | Eleven | 11more11@163.com | 3 | Haris | Rookie |
| 5 | Eleven | 11more11@163.com | 7 | Kitty | Miffy |
| 6 | Miffy | miffy521@126.com | 1 | Sam | Tim |
| 6 | Miffy | miffy521@126.com | 2 | Bob | Sam |
| 6 | Miffy | miffy521@126.com | 3 | Haris | Rookie |
| 6 | Miffy | miffy521@126.com | 7 | Kitty | Miffy |
+----+--------+---------------------+----+-------+-------------+
24 rows in set (0.00 sec)
使用ON条件加以约束:
mysql> select i.id, i.name, i.email, bf.id, bf.name, bf.friend_name
-> from stu_info as i
-> inner join stu_best_friend as bf
-> on i.id=bf.id and i.name=bf.name;
+----+------+------------------+----+------+-------------+
| id | name | email | id | name | friend_name |
+----+------+------------------+----+------+-------------+
| 1 | Sam | 123456789@qq.com | 1 | Sam | Tim |
| 2 | Bob | bobbob@gmail.com | 2 | Bob | Sam |
+----+------+------------------+----+------+-------------+
2 rows in set (0.00 sec)
LEFT JOIN
LEFT JOIN 语句会从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
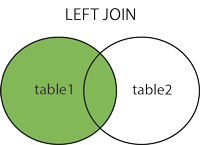
标准的SQL语法格式是这样的:
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
或者是:
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
我们改做左合并查询:
mysql> select i.id, i.name, i.email, bf.id, bf.name, bf.friend_name
-> from stu_info as i
-> left outer join stu_best_friend as bf
-> on i.id=bf.id and i.name=bf.name;
+----+--------+---------------------+------+------+-------------+
| id | name | email | id | name | friend_name |
+----+--------+---------------------+------+------+-------------+
| 1 | Sam | 123456789@qq.com | 1 | Sam | Tim |
| 2 | Bob | bobbob@gmail.com | 2 | Bob | Sam |
| 3 | Steven | steven521@gmail.com | NULL | NULL | NULL |
| 4 | Amy | amy20205205@163.com | NULL | NULL | NULL |
| 5 | Eleven | 11more11@163.com | NULL | NULL | NULL |
| 6 | Miffy | miffy521@126.com | NULL | NULL | NULL |
+----+--------+---------------------+------+------+-------------+
6 rows in set (0.00 sec)
RIGHT JOIN
RIGHT JOIN 语句从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
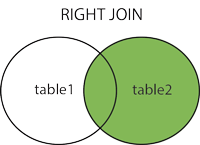
标准的SQL语法格式是这样的:
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
或者是:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
我们改做右合并查询:
mysql> select i.id, i.name, i.email, bf.id, bf.name, bf.friend_name
-> from stu_info as i
-> right outer join stu_best_friend as bf
-> on i.id=bf.id and i.name=bf.name;
+------+------+------------------+----+-------+-------------+
| id | name | email | id | name | friend_name |
+------+------+------------------+----+-------+-------------+
| 1 | Sam | 123456789@qq.com | 1 | Sam | Tim |
| 2 | Bob | bobbob@gmail.com | 2 | Bob | Sam |
| NULL | NULL | NULL | 3 | Haris | Rookie |
| NULL | NULL | NULL | 7 | Kitty | Miffy |
+------+------+------------------+----+-------+-------------+
4 rows in set (0.00 sec)
FULL JOIN
FULL OUTER JOIN 语句只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.
FULL OUTER JOIN 语句相当于结合了 LEFT JOIN 和 RIGHT JOIN 的结果,也相当于LEFT OUTER JOIN + UNION + RIGHT OUTER JOIN。
虽说Oracle支持,但MySQL是不支持FULL OUTER JOIN的,但仍然可以同过LEFT OUTER JOIN + UNION + RIGHT OUTER JOIN实现。
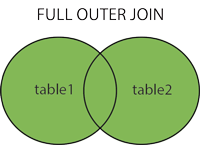
标准的SQL语法格式是这样的:
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
我们使用MySQL尝试使用FULL OUTER JOIN,失败:
mysql> select i.id, i.name, i.email, bf.id, bf.name, bf.friend_name
-> from stu_info as i
-> full outer join stu_best_friend as bf
-> on i.id=bf.id and i.name=bf.name;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'full outer join stu_best_friend as bf
on i.id=bf.id and i.name=bf.name' at line 3
UNION操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列,这些列也必须拥有相似的数据类型,对应多个SELECT语句的列顺序要相同(不能有任何不同)。
下面我们就做一个测试,这个语句查了语文过125或者数学过130的学生(其实也就相当于用了个OR):
mysql> select * from stu_grade
-> where chinese > 125
-> union
-> select * from stu_grade
-> where math > 130;
+----+--------+---------+------+---------+-------+
| id | name | chinese | math | english | grade |
+----+--------+---------+------+---------+-------+
| 3 | Steven | 130 | 108 | 135 | 373 |
| 5 | Eleven | 130 | 130 | 140 | 400 |
| 1 | Sam | 120 | 145 | 145 | 410 |
| 6 | Miffy | 125 | 145 | 135 | 405 |
+----+--------+---------+------+---------+-------+
4 rows in set (0.35 sec)
不难发现,上面数据顺序都乱了,我们可能希望它是有序的。
而使用UNION的查询结果自然可以使用ORDER BY进行排序了,只是有些问题要注意:
- 只有在所有查询结果都合并在一起之后,才能使用一次ORDER BY。不能使用两次,必须在最后用。
- 使用ORDER BY排序时,使用别名会很方便,但必须要使得两个结果的别名保持一致。
- 不一定非要用别名,其实甚至还使用列号。
下面就基于grade属性给一个降序排列:
mysql> select * from stu_grade
-> where chinese > 125
-> union
-> select * from stu_grade
-> where math > 130
-> order by grade desc;
+----+--------+---------+------+---------+-------+
| id | name | chinese | math | english | grade |
+----+--------+---------+------+---------+-------+
| 1 | Sam | 120 | 145 | 145 | 410 |
| 6 | Miffy | 125 | 145 | 135 | 405 |
| 5 | Eleven | 130 | 130 | 140 | 400 |
| 3 | Steven | 130 | 108 | 135 | 373 |
+----+--------+---------+------+---------+-------+
4 rows in set (0.00 sec)
约束相关
约束用于规定表中的数据规则,违反约束的增删改查不能成立。
SQL约束主可能在两种情况下被加入:
- 建表时随着CREATE TABLE语句被附加(可以看我前面建表用的primary key、not null这些,其实就是建表加入的约束)。
- 建表之后随时使用ALTER TABLE语句修改表的结构(后面专门会演示这个)。
SQL约束的去除你可以随时进行,要使用ALTER TABLE语句+DROP语句。
SQL中主要的六种约束:
- NOT NULL:指示某列不能存储 NULL 值(挺好使的,我前面也用过)。
- UNIQUE:保证某列的每行必须有唯一的值,不能重复,一般适用于ID这种(不过ID很可能是主键,就不必UNIQUE)。
- PRIMARY KEY:指定主键,唯一性,不能指定两个。这个玩意相当于NOT NULL + UNIQUE。它能确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。不过要记得这个和索引不一样啊!
- FOREIGN KEY:是外键,保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK:保证列中的值符合指定的条件(这个条件就是相当于布尔表达式)。
- DEFAULT:规定没有给列赋值时的默认值(比如0啊)。
标准的SQL语法格式是这样的:
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
我们由于事先没指定外键,所以为stu_grade的id属性指定一个外键,参照stu_info的id:
mysql> alter table stu_grade
-> add foreign key(id)
-> references stu_info(id);
Query OK, 6 rows affected (1.28 sec)
Records: 6 Duplicates: 0 Warnings: 0
去除刚才加的外键,我们发现不能使用id删:
mysql> alter table stu_grade
-> drop foreign key id;
ERROR 1091 (42000): Can't DROP 'id'; check that column/key exists
这可怎么办呢?
答案是:查一下表的结构:
mysql> show create table stu_grade;
+-----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stu_grade | CREATE TABLE `stu_grade` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`chinese` int(11) DEFAULT '0',
`math` int(11) DEFAULT '0',
`english` int(11) DEFAULT '0',
`grade` int(11) DEFAULT '0',
PRIMARY KEY (`id`),
CONSTRAINT `stu_grade_ibfk_1` FOREIGN KEY (`id`) REFERENCES `stu_info` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
看到CONSTRAINT `stu_grade_ibfk_1` FOREIGN KEY (`id`) REFERENCES `stu_info` (`id`)了吗?
我们固然可以不指定标识的值,但MySQL会自动地帮我们定一个值,需要用它来删除:
mysql> alter table stu_grade
-> drop foreign key stu_grade_ibfk_1;
Query OK, 0 rows affected (0.49 sec)
Records: 0 Duplicates: 0 Warnings: 0
我们不妨再查一下:
mysql> show create table stu_grade;
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stu_grade | CREATE TABLE `stu_grade` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`chinese` int(11) DEFAULT '0',
`math` int(11) DEFAULT '0',
`english` int(11) DEFAULT '0',
`grade` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
哦,这个外键约束没啦!
接下来我们要尝试自己顶一个约束名称,并尝试一下传说中的CHECK约束:
mysql> alter table stu_grade
-> add constraint cc check(id>0);
Query OK, 6 rows affected (1.14 sec)
Records: 6 Duplicates: 0 Warnings: 0
查查表结构:
mysql> show create table stu_grade;
+-----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stu_grade | CREATE TABLE `stu_grade` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`chinese` int(11) DEFAULT '0',
`math` int(11) DEFAULT '0',
`english` int(11) DEFAULT '0',
`grade` int(11) DEFAULT '0',
PRIMARY KEY (`id`),
CONSTRAINT `cc` CHECK ((`id` > 0))
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
顺利加入!
再删除:
mysql> alter table stu_grade
-> drop check cc;
Query OK, 0 rows affected (0.43 sec)
Records: 0 Duplicates: 0 Warnings: 0
删除后,查询表结构确认:
mysql> show create table stu_grade;
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stu_grade | CREATE TABLE `stu_grade` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`chinese` int(11) DEFAULT '0',
`math` int(11) DEFAULT '0',
`english` int(11) DEFAULT '0',
`grade` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
CREATE INDEX语句
CREATE INDEX语句就是用来创建索引的!
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据,不需要扫描全表(注意select*是经典的全表扫描,在数据量大的时候很慢)。
MySQL的索引基于B+树实现,这些我们在这里就先不细说了。
标准SQL语法允许创建两种索引:
-
简单的、允许重复值的索引:
CREATE INDEX index_name ON table_name (column_name) -
唯一索引
CREATE UNIQUE INDEX index_name ON table_name (column_name)
我们做一下建立索引的简单尝试:
mysql> create unique index index_id
-> on stu_info(id);
Query OK, 0 rows affected (0.70 sec)
Records: 0 Duplicates: 0 Warnings: 0
也可以使用DROP语句删除索引:
mysql> drop index index_id on stu_info;
Query OK, 0 rows affected (0.61 sec)
Records: 0 Duplicates: 0 Warnings: 0
完美退出
mysql> \q
Bye
总结
讲了这么多,有语法,有排坑点拨,也有实战演练,不知道大家看完之后可有收获?
写了这么久,希望得到大家的支持!谢谢!
