一、内存和变量
实际应用中,一种常用方法是将浮点数组转换为theano.config.floatX型:
- 1.利用numpy.array(array,dtype=theano.config.floatX)创建数组;
- 2.将数组转换为array.as_type(theano.config.floatx),以使得在GPU上编译时,使用正确的类型。
例如,手动将数据传输到GPU(在此,默认为None),为此,需要使用float32值:
>>> theano.config.floatX = 'float32'
>>> a = T.matrix()
>>> b = a.transfer(None)
>>> b.eval({a:numpy.ones((2,2)).astype(theano.config.floatX)})
gpuarray.array([[ 1., 1.],
[ 1., 1.]], dtype=float32)
>>> theano.printing.debugprint(b)
GpuFromHost<None> [id A] ''
|<TensorType(float32, matrix)> [id B]
Transfer(device)函数(如transfer(‘cpu’))可允许数据从一个设备传输到另一个设备。这在部分计算图必须在不同设备上执行时非常有用。否则,Theano会在优化阶段自动向GPU增加传输函数:
>>> a = T.matrix('a')
>>> b = a ** 2
>>> sq = theano.function([a], b)
>>> theano.printing.debugprint(sq)
HostFromGpu(gpuarray) [id A] '' 2
|GpuElemwise{Sqr}[(0, 0)]<gpuarray> [id B] '' 1
|GpuFromHost<None> [id C] '' 0
|a [id D]
通过显示使用传输函数,Theano可免去返回到CPU的传输。将输出张量保存在GPU上可节省大量的传输成本:
>>> b = b.transfer(None)
>>> sq = theano.function([a],b)
>>> theano.printing.debugprint(sq)
GpuElemwise{Sqr}[(0, 0)]<gpuarray> [id A] '' 1
|GpuFromHost<None> [id B] '' 0
|a [id C]
Theano变量的默认设备为CPU:
>>> a = T.matrix('a')
>>> b = a.transfer('cpu')
>>> theano.printing.debugprint(b)
a [id A]
数值和符号变量之间的混合概念是共享变量。采用共享变量可通过避免传输而提高GPU的性能。通常,以标量零来初始化一个共享变量:
>>> state = theano.shared(0)
>>> state
<TensorType(int64, scalar)>
>>> state.get_value()
array(0)
>>> state.set_value(1)
>>> state.get_value()
array(1)
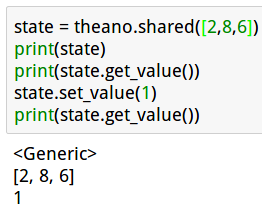
共享值是设计为在函数之间共享。也可看做一个内部状态。共享值可以在GPU或CPU上独立编译代码。默认情况下,是在默认设备(此处为cuda)上创建共享变量,除了标量整数值(如上述示例)。
还可以指定另一个设备,如cpu。在多个GPU实例情况下,将在Python命令行中定义设备,并决定在哪个设备上创建共享变量:
PATH=/usr/local/cuda-10.1/bin:$PATH THEANO_FLAGS=”contexts=dev0->cuda0;dev1->cuda1,floatX=float32,gpuarray.preallocate=0.8” python
from theano import theano
import theano.tensor as T
import numpy
theano.shared(numpy.random.random((1024,1024)).astype('float32'),target='dev0')
<GpuArrayType<dev1>(float32, (False, False))>
python
>>> import theano
Can not use cuDNN on context None: Use cuDNN 7.0.2 or higher for Volta.
Mapped name None to device cuda: GeForce RTX 2070 (0000:01:00.0)
>>> import theano.tensor as T
>>> import numpy
>>> theano.shared(numpy.random.random((1024,1024)).astype('float32'))
<GpuArrayType<None>(float32, matrix)>
二、 函数和自动微分
上节讲到了编译表达式的函数指令。本节将主要介绍上述函数中的下列参数:
def theano.function(inputs,
outputs=None,
updates=None,
givens=None,
allow_input_downcast=None,
mode=None,
profile=None)
现已使用allow_input_downcast特性将数据从float64转换为float32、int64转换为int32等。由于在优化和调试阶段会出现,还显示了mode和profile特性。
一个Theano函数的输入变量应包含在列表中,即使只是一个单输入变量。
对于输出,可以通过列表在多个输出情况下并行计算:
>>> a=T.matrix()
>>> ex = theano.function([a], [T.exp(a), T.log(a),a**2])
>>> aa = numpy.random.randn(3,3)
>>> aa
array([[-1.61796566, 0.41952652, 0.74597705],
[ 0.51071641, -0.57770566, 0.06313347],
[-0.40113569, -0.15598277, -0.85189313]])
>>> ex(aa.astype(theano.config.floatX))
[array([[ 0.19830169, 1.52124119, 2.10850048],
[ 1.66648459, 0.56118441, 1.0651691 ],
[ 0.66955918, 0.85557389, 0.42660654]], dtype=float32), array([[ nan, -0.86862856, -0.29306045],
[-0.67194086, nan, -2.7625041 ],
[ nan, nan, nan]], dtype=float32), array([[ 2.61781311, 0.1760025 , 0.55648178],
[ 0.26083121, 0.33374384, 0.00398584],
[ 0.16090983, 0.02433063, 0.7257219 ]], dtype=float32)]
第二个非常有用的特性是updates属性,用于在确定表达式后将新值设置为共享变量:
>>> w = theano.shared(1.0)
>>> x = T.scalar('x')
>>> y = w*x**2
>>> mul = theano.function([x],y,updates=[(w,w*x)])
>>> mul(4)
array(16.0)
>>> w.get_value()
array(4.0)
>>> mul(4)
array(64.0)
这种机制可作为一个内部状态来使用。共享变量w在函数之外进行定义。
利用givens参数可更改计算图中任意符号变量的值而不改变计算图。然后,在所有其他表达式中使用新值。
Theano的最后一个也是最重要的特征就是自动微分,这意味着Theano可计算上述所有张量算子的导数。这是通过theano.grad算子来实现微分计算的。
>>> a = T.scalar()
>>> pow = a**2
>>> g = theano.grad(pow, a)
>>> theano.printing.pydotprint(g)
The output file is available at /home/wc/.theano/compiledir_Linux-4.4--generic-x86_64-with-debian-jessie-sid-x86_64-3.5.4-64/theano.pydotprint.cuda.png
>>> theano.printing.pydotprint(theano.function([a],g))
The output file is available at /home/wc/.theano/compiledir_Linux-4.4--generic-x86_64-with-debian-jessie-sid-x86_64-3.5.4-64/theano.pydotprint.cuda.png
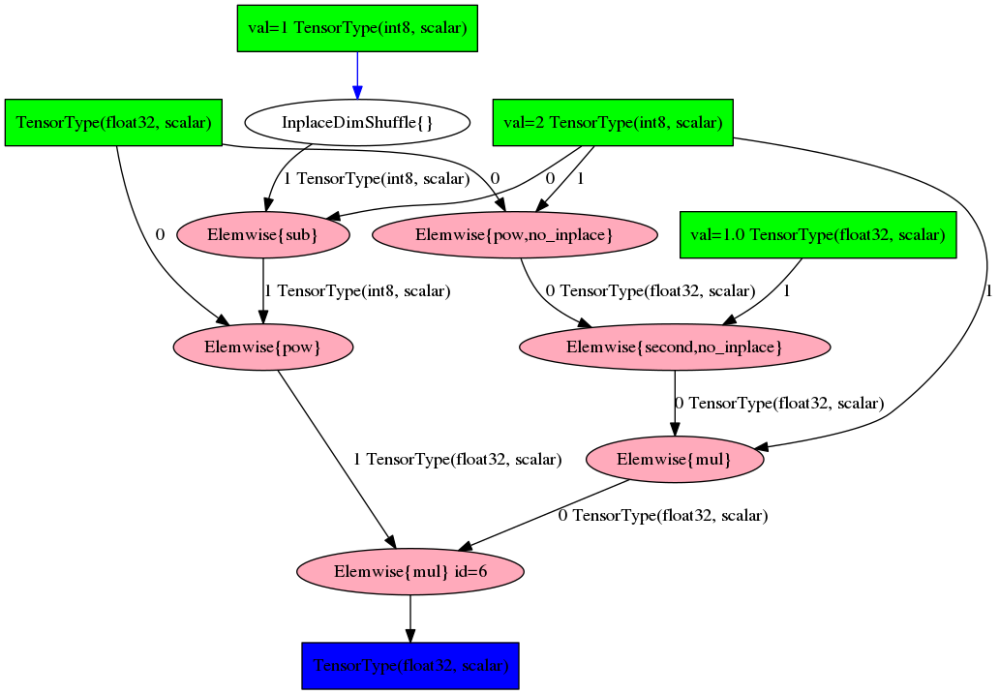
在优化计算图中,theano.grad计算相对于a的梯度a2,这是相当于2*a的符号表达式。
Ps:只能取标量梯度,但wrt变量可以是任意张量。
三、符号计算中的循环运算
Python中的for循环可在符号计算图之外作为一个普通的Python程序来使用。但是在计算图内部,不会编译普通的Python for循环,因此不会通过利用并行和代数库进行优化,也不能实现自动微分,如果GPU的计算子图已优化,还会产生大量的数据传输成本。
这就是设计符号算子T.scan来创建一个for循环以作为计算图中一个运算算子的原因。Theano会在计算图结构中展开循环,而整个展开后的循环将在目标架构上编译,并作为一部分计算图。具体如下:
def scan(fn,
sequences=None,
outputs_info=None,
non_sequences=None,
n_steps=None,
truncate_gradient=-1,
go_backwards=False,
mod=None,
name=None,
profile=False,
allow_gc=None,
strict=False)
scan算子对于实现数组循环、约减、映射、多维微分(如Jocobian矩阵或Hessian矩阵)和递归运算非常有用。
scan算子重复执行fn函数n_steps次。如果n_steps为None,则算子得到序列长度:
Notes:fn函数是一个构建符号计算图的函数,该函数只能调用一次。然而,该计算图可编译成Theano的另一个可重复调用的函数。有些用户尝试将编译的Theano函数作为fn,但这不可能实现。
序列是循环输入变量的列表。循环次数将对英语列表中的最短序列。如下所示:
a = T.matrices('a')
def fn(x):
return x+1
results, updates = theano.scan(fn, sequences=a)
f = theano.function([a], results, updates=updates)
f(numpy.ones((2,3)).astype(theano.config.floatX))
array([[ 2., 2., 2.],
[ 2., 2., 2.]], dtype=float32)
Scan算子对输入张量a中的所有元素执行函数,并保持与输入张量(2,3)相同的形状。
ps:实际应用中,最好是增加由theano.function中的theano.scan返回的更新值,即使这些更新值均为空。
fn函数的参数可能比较复杂。T.scan可在每一步中以参数列表调用fn函数,命令如下:
fn(sequences(if any), prior results(if needed), non-sequences(if any))
如下图所示,3个箭头指向fn函数,并表示循环中每一时间步长处的3种可能输入类型:
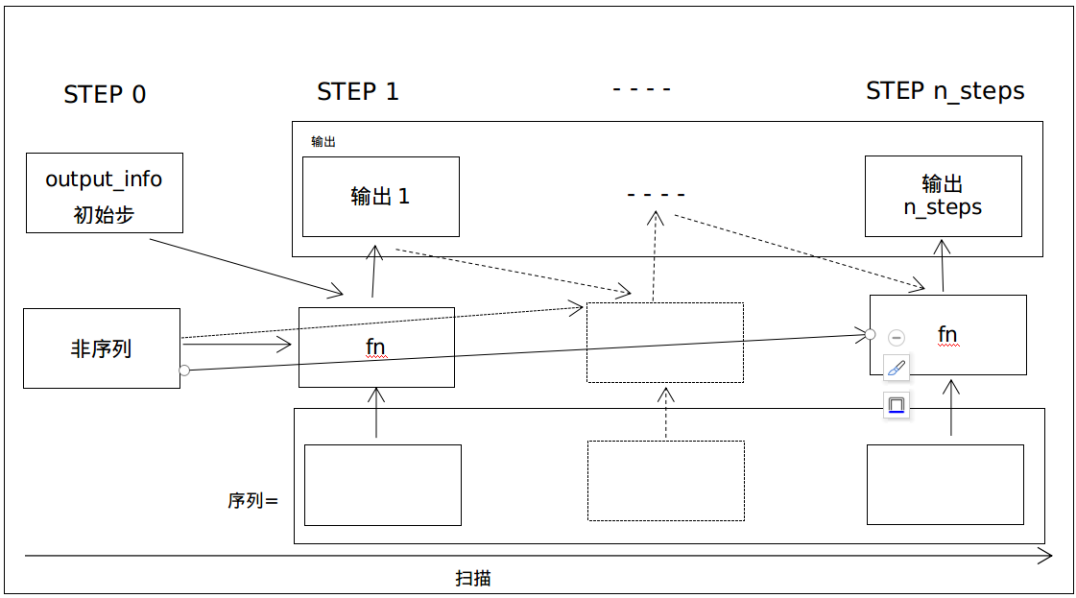 如果需要指定,output_info参数是指启动递归的初始状态。虽然参数名称可能会误解,但初始状态确实会给出最终状态的形状信息,以及所有其他状态。初始状态可看做第一个输出。最终的输出将是一个状态数组。
如果需要指定,output_info参数是指启动递归的初始状态。虽然参数名称可能会误解,但初始状态确实会给出最终状态的形状信息,以及所有其他状态。初始状态可看做第一个输出。最终的输出将是一个状态数组。
例如,要计算一个向量的累积和,且初始状态为在0处的和,可利用以下代码实现:
a = T.vector()
s0 = T.scalar("s0")
def fn(current_element, prior):
return prior + current_element
results, updates = theano.scan(fn=fn,outputs_info=s0, sequences=a)
f = theano.function([a, s0], results, updates=updates)
f([2,3,5],0)
array([ 2., 5., 10.], dtype=float32)
在设置outputs_info时,outputs_info和序列变量的第一个维度是时间步长。第二个维度是每个时间步长处的数据维度。
特别是,outputs_info具有第一步所需的前几个时间步长。
在此,给出一个相同示例,只是输入数据是每个时间步长处的一个向量,而不是标量:
a = T.matrix()
s0 = T.scalar("s0")
def fn(current_element, prior):
return prior + current_element.sum()
results, updates = theano.scan(fn=fn,outputs_info=s0, sequences=a)
f = theano.function([a, s0], results, updates=updates)
f(numpy.ones((20,5)).astype(theano.config.floatX), 0)
array([ 2., 5., 10.], dtype=float32)
沿横轴(时间)运行20次可得到所有元素的累积和。注意:由output_info参数给定的初始状态(在此为0)不在输出序列中。
递归函数fn可以提供一些与循环步骤无关的固定数据,这要归功于non_sequences扫描参数:
a = T.vector()
s0 = T.scalar("s0")
def fn(current_element, prior, non_seq):
return non_seq*prior + current_element
results, updates = theano.scan(fn=fn,n_steps=10, sequences=a, outputs_info=T.constant(0.0), non_sequences=s0 )
f = theano.function([a, s0], results, updates=updates)
f(numpy.ones((20)).astype(theano.config.floatX), 5)
array([ 1.00000000e+00, 6.00000000e+00, 3.10000000e+01,
1.56000000e+02, 7.81000000e+02, 3.90600000e+03,
1.95310000e+04, 9.76560000e+04, 4.88281000e+05,
2.44140600e+06], dtype=float32)
在GPU优化计算图中的T.scan并未并行执行循环的不同迭代次数,即使实在非递归情况下。
四、配置、分析和调试
为了调试目的,Theano可以打印输出更详细的信息和提供不同的优化模式:
>>> theano.config.exception_verbosity='high'
>>> theano.config.mode
'Mode'
>>> theano.config.optimizer='fast_compile'
为了在Theano中使用config.optimizer值,必须设置模式为Mode,否则将使用config.mode值:
| config.mode/函数模式 | config.optimizer(*) | 描述 |
|---|---|---|
| FAST_RUN | fast_run | 默认:运行性能最佳、编译过程慢 |
| FAST_RUN | None | 禁用优化 |
| FAST_COMPILE | fast_compile | 减少优化次数,加快编译速度 |
| None | 采用默认模式,相当于FAST_RUN;optimizer=None | |
| NanGuardMode | NaNs、Infs和异常大的值都会产生错误 | |
| DebugMode | 编译过程中自检查和判断 |
config.mode中的相同参数可用于函数编译的Mode参数中:
f = theano.function([a, s0], results, updates=updates, mode=‘FAST_COMPILE’)
禁用优化和选择更多信息会有助于发现计算图中的错误。
为了在GPU上进行调试,需要设置一个同步执行环境变量,在.bashrc中写入如下代码
export CUDA_LAUNCH_BLOCKING=1
这是因为GPU是默认完全异步执行:
>>> os.environ.get('CUDA_LAUNCH_BLOCKING', '0')
'1'
为了确定计算图中的延迟问题,Theano提供了一种分析模式。
启动分析:
>>> theano.config.profile=True
启动内存分析:
>>> theano.config.profile_memory=True
启动优化阶段分析:
>>> theano.config.profile_optimizer=True
或在编译时直接分析:
>>> import theano
Can not use cuDNN on context None: Use cuDNN 7.0.2 or higher for Volta.
Mapped name None to device cuda: GeForce RTX 2070 (0000:01:00.0)
>>> import theano.tensor as T
>>> import numpy
>>> a = T.vector()
>>> s0 = T.scalar("s0")
>>> def fn(current_element, prior, non_seq):
... return non_seq*prior + current_element
...
>>> results, updates = theano.scan(fn=fn,n_steps=10, sequences=a, outputs_info=T.constant(0.0), non_sequences=s0 )
>>> f = theano.function([a,s0], results, updates=updates, profile=True)
>>> f(numpy.ones((20)).astype(theano.config.floatX), 5)
array([ 1.00000000e+00, 6.00000000e+00, 3.10000000e+01,
1.56000000e+02, 7.81000000e+02, 3.90600000e+03,
1.95310000e+04, 9.76560000e+04, 4.88281000e+05,
2.44140600e+06], dtype=float32)
>>> f.profile.summary()
Function profiling
==================
Message: <stdin>:1
Time in 1 calls to Function.__call__: 1.167798e-02s
Time in Function.fn.__call__: 1.135349e-02s (97.221%)
Time in thunks: 1.131868e-02s (96.923%)
Total compile time: 2.375718e+00s
Number of Apply nodes: 9
Theano Optimizer time: 8.343992e-01s
Theano validate time: 9.918213e-05s
Theano Linker time (includes C, CUDA code generation/compiling): 1.530395e+00s
Import time 5.969763e-03s
Node make_thunk time 1.530060e+00s
Node GpuIncSubtensor{Set;:int64:}(GpuAllocEmpty{dtype='float32', context_name=None}.0, GpuArrayConstant{[ 0.]}, Constant{1}) time 2.393835e-01s
Node for{gpu,scan_fn}(TensorConstant{10}, GpuSubtensor{:int8:}.0, GpuIncSubtensor{Set;:int64:}.0, GpuFromHost<None>.0) time 2.296596e-01s
Node GpuAllocEmpty{dtype='float32', context_name=None}(TensorConstant{11}) time 2.292364e-01s
Node HostFromGpu(gpuarray)(GpuSubtensor{int64::}.0) time 2.186446e-01s
Node GpuSubtensor{:int8:}(GpuFromHost<None>.0, Constant{10}) time 2.102511e-01s
Time in all call to theano.grad() 0.000000e+00s
Time since theano import 267.621s
Class
---
<% time> <sum %> <apply time> <time per call> <type> <#call> <#apply> <Class name>
94.7% 94.7% 0.011s 5.36e-03s C 2 2 theano.gpuarray.basic_ops.GpuFromHost
3.0% 97.7% 0.000s 3.39e-04s Py 1 1 theano.scan_module.scan_op.Scan
2.0% 99.8% 0.000s 2.32e-04s C 1 1 theano.gpuarray.subtensor.GpuIncSubtensor
0.1% 99.9% 0.000s 1.19e-05s C 1 1 theano.gpuarray.basic_ops.HostFromGpu
0.1% 99.9% 0.000s 6.91e-06s C 1 1 theano.tensor.subtensor.Subtensor
0.1% 100.0% 0.000s 2.98e-06s C 2 2 theano.gpuarray.subtensor.GpuSubtensor
0.0% 100.0% 0.000s 1.91e-06s C 1 1 theano.gpuarray.basic_ops.GpuAllocEmpty
... (remaining 0 Classes account for 0.00%(0.00s) of the runtime)
Ops
---
<% time> <sum %> <apply time> <time per call> <type> <#call> <#apply> <Op name>
94.7% 94.7% 0.011s 5.36e-03s C 2 2 GpuFromHost<None>
3.0% 97.7% 0.000s 3.39e-04s Py 1 1 for{gpu,scan_fn}
2.0% 99.8% 0.000s 2.32e-04s C 1 1 GpuIncSubtensor{Set;:int64:}
0.1% 99.9% 0.000s 1.19e-05s C 1 1 HostFromGpu(gpuarray)
0.1% 99.9% 0.000s 6.91e-06s C 1 1 Subtensor{int64::}
0.0% 100.0% 0.000s 4.05e-06s C 1 1 GpuSubtensor{:int8:}
0.0% 100.0% 0.000s 1.91e-06s C 1 1 GpuAllocEmpty{dtype='float32', context_name=None}
0.0% 100.0% 0.000s 1.91e-06s C 1 1 GpuSubtensor{int64::}
... (remaining 0 Ops account for 0.00%(0.00s) of the runtime)
Apply
------
<% time> <sum %> <apply time> <time per call> <#call> <id> <Apply name>
94.7% 94.7% 0.011s 1.07e-02s 1 4 GpuFromHost<None>(Subtensor{int64::}.0)
3.0% 97.7% 0.000s 3.39e-04s 1 6 for{gpu,scan_fn}(TensorConstant{10}, GpuSubtensor{:int8:}.0, GpuIncSubtensor{Set;:int64:}.0, GpuFromHost<None>.0)
2.0% 99.7% 0.000s 2.32e-04s 1 2 GpuIncSubtensor{Set;:int64:}(GpuAllocEmpty{dtype='float32', context_name=None}.0, GpuArrayConstant{[ 0.]}, Constant{1})
0.1% 99.8% 0.000s 1.19e-05s 1 8 HostFromGpu(gpuarray)(GpuSubtensor{int64::}.0)
0.1% 99.9% 0.000s 6.91e-06s 1 3 Subtensor{int64::}(<TensorType(float32, vector)>, Constant{0})
0.0% 99.9% 0.000s 5.01e-06s 1 0 GpuFromHost<None>(s0)
0.0% 100.0% 0.000s 4.05e-06s 1 5 GpuSubtensor{:int8:}(GpuFromHost<None>.0, Constant{10})
0.0% 100.0% 0.000s 1.91e-06s 1 7 GpuSubtensor{int64::}(for{gpu,scan_fn}.0, Constant{1})
0.0% 100.0% 0.000s 1.91e-06s 1 1 GpuAllocEmpty{dtype='float32', context_name=None}(TensorConstant{11})
... (remaining 0 Apply instances account for 0.00%(0.00s) of the runtime)
Scan overhead:
<Scan op time(s)> <sub scan fct time(s)> <sub scan op time(s)> <sub scan fct time(% scan op time)> <sub scan op time(% scan op time)> <node>
One scan node do not have its inner profile enabled. If you enable Theano profiler with 'theano.function(..., profile=True)', you must manually enable the profiling for each scan too: 'theano.scan_module.scan(...,profile=True)'. Or use Theano flag 'profile=True'.
No scan have its inner profile enabled.
Some info useful for gpu:
Spent 0.000s(3.05%) in cpu Op, 0.000s(2.12%) in gpu Op and 0.011s(94.83%) transfert Op
Theano function input that are float64
<fct name> <input name> <input type> <str input>
List of apply that don't have float64 as input but have float64 in outputs
(Useful to know if we forgot some cast when using floatX=float32 or gpu code)
<Apply> <Apply position> <fct name> <inputs type> <outputs type>
Here are tips to potentially make your code run faster
(if you think of new ones, suggest them on the mailing list).
Test them first, as they are not guaranteed to always provide a speedup.
Sorry, no tip for today.
