Scala学习笔记
git地址
https://github.com/a18792721831/studyScala.git
1.变量
变量分为可变变量和不可变变量
可变变量用var修饰
不可变变量用val修饰
scala是在java虚拟机上运行的,所以,scala编译后也是class文件,那么使用class反编译文件,可以知道scala是如何实现的。
首先我们定义不同数据类型的变量:
package com.study
object Testsss {
def main(args: Array[String]): Unit = {
//int
var a: Int = 8
//double
var b: Double = 3.4
//long
var c: Long = 88888
//java.lang.String
var d: String = "hello"
//boolean
var e: Boolean = true
//float
var f: Float = 3.14f
//元组
var (g: String, h: Boolean) = ("test", true)
//数组?
var i: Array[String] = new Array[String](3)
i(0) = "hi "
i(1) = " , "
i(2) = " .... "
for (x <- 0 to i.length - 1) print(i(x))
i.foreach(x => println(i(x)))
println()
var j = Array("hello ", "xiao ", "hua ")
for (x <- 0 to j.length - 1)
print(j(x))
println()
//二维数组
var k = new Array[Array[String]](3)
for (x <- 0 to k.length - 1) {
var t = new Array[String](3)
for (y <- 0 to t.length - 1) {
t(y) = y + " "
}
k(x) = t
}
for (x <- 0 to k.length - 1) {
var t: Array[String] = k(x)
for (y <- 0 to t.length - 1) {
print(t(y))
}
println()
}
}
}
编译后生成了两个class文件

反编译后如下
package com.study;
import scala.reflect.ScalaSignature;
@ScalaSignature(bytes="")
public final class Testsss
{
public static void main(String[] paramArrayOfString)
{
Testsss..MODULE$.main(paramArrayOfString);
}
}
//
// Decompiled by Procyon v0.5.36
//
package com.study;
import java.lang.invoke.SerializedLambda;
import scala.MatchError;
import scala.Function1;
import scala.Predef$;
import scala.runtime.RichInt$;
import scala.runtime.ObjectRef;
import scala.Tuple2;
import scala.runtime.BoxesRunTime;
public final class Testsss$
{
public static final Testsss$ MODULE$;
static {
MODULE$ = new Testsss$();
}
public void main(final String[] args) {
final int a = 8;
final double b = 3.4;
final long c = 88888L;
final String d = "hello";
final boolean e = true;
final float f = 3.14f;
final Tuple2 tuple2 = new Tuple2((Object)"test", (Object)BoxesRunTime.boxToBoolean(true));
if (tuple2 != null) {
final String g = (String)tuple2._1();
final boolean h = tuple2._2$mcZ$sp();
if (g != null) {
final String s = g;
if (true) {
final Tuple2 tuple3 = new Tuple2((Object)s, (Object)BoxesRunTime.boxToBoolean(h));
final String g2 = (String)tuple3._1();
final boolean h2 = tuple3._2$mcZ$sp();
final ObjectRef i = ObjectRef.create((Object)new String[3]);
((String[])i.elem)[0] = "hi ";
((String[])i.elem)[1] = " , ";
((String[])i.elem)[2] = " .... ";
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])i.elem).length - 1).foreach$mVc$sp((Function1)(x -> Predef$.MODULE$.print((Object)((String[])i.elem)[x])));
Predef$.MODULE$.println();
final ObjectRef j = ObjectRef.create((Object)new String[] { "hello ", "xiao ", "hua " });
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])j.elem).length - 1).foreach$mVc$sp((Function1)(x -> Predef$.MODULE$.print((Object)((String[])j.elem)[x])));
Predef$.MODULE$.println();
final ObjectRef k = ObjectRef.create((Object)new String[3][]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[][])k.elem).length - 1).foreach$mVc$sp((Function1)(x -> {
final ObjectRef t = ObjectRef.create((Object)new String[3]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])t.elem).length - 1).foreach$mVc$sp((Function1)(y -> ((String[])t.elem)[y] = new StringBuilder(1).append(y).append(" ").toString()));
((String[][])k.elem)[x] = (String[])t.elem;
}));
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[][])k.elem).length - 1).foreach$mVc$sp((Function1)(x -> {
final ObjectRef t = ObjectRef.create((Object)((String[][])k.elem)[x]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])t.elem).length - 1).foreach$mVc$sp((Function1)(y -> Predef$.MODULE$.print((Object)((String[])t.elem)[y])));
Predef$.MODULE$.println();
}));
return;
}
}
}
throw new MatchError((Object)tuple2);
}
private Testsss$() {
}
}
可以看到,scala生成的类都是final类。
一个scala的object类会生成两个class文件。
带有$的是内部类
可以看到,scala生成了同名的内部类,内部类和scala生成的外部类有相同的作用域。
内部类分为四部分:
1.定义了一个内部类的共有静态最终实例
2.静态语句块进行new初始化
3.我们在scala中写的代码,操作,实际被编译到内部类的同名方法里
4.内部类是私有构造。
从这4个特点可以得出一些信息:
1.1.scala编译的内部类是单例模式,采用饿汉式的创建方式
问题,线程安全吗?从反编译的代码来看,好像是没有用锁的,那么,多线程可能不安全????
猜测,这里因为是使用饿汉式的方式进行初始化的单例对象。而饿汉式是在类加载后执行静态语句的。
所以,这里的线程安全应该是交给了类加载器去管理实现的。。
也就不会存在线程安全的问题。
1.2.scala编译后,内部类中所有的变量都是final修饰的。
那么,我们使用var定义有什么意义?
我们修改其中一个可变参数的值,然后重新编译,重新反编译,看看scala是如何实现的。
package com.study
object Testsss {
def main(args: Array[String]): Unit = {
//int
var a: Int = 8
a = 7
//double
var b: Double = 3.4
//long
var c: Long = 88888
//java.lang.String
var d: String = "hello"
//boolean
var e: Boolean = true
//float
var f: Float = 3.14f
//元组
var (g: String, h: Boolean) = ("test", true)
//数组?
var i: Array[String] = new Array[String](3)
i(0) = "hi "
i(1) = " , "
i(2) = " .... "
for (x <- 0 to i.length - 1) print(i(x))
// i.foreach(x => println(i(x)))
println()
var j = Array("hello ", "xiao ", "hua ")
for (x <- 0 to j.length - 1)
print(j(x))
println()
//二维数组
var k = new Array[Array[String]](3)
for (x <- 0 to k.length - 1) {
var t = new Array[String](3)
for (y <- 0 to t.length - 1) {
t(y) = y + " "
}
k(x) = t
}
for (x <- 0 to k.length - 1) {
var t: Array[String] = k(x)
for (y <- 0 to t.length - 1) {
print(t(y))
}
println()
}
}
}
反编译后
//
// Decompiled by Procyon v0.5.36
//
package com.study;
import java.lang.invoke.SerializedLambda;
import scala.MatchError;
import scala.Function1;
import scala.Predef$;
import scala.runtime.RichInt$;
import scala.runtime.ObjectRef;
import scala.Tuple2;
import scala.runtime.BoxesRunTime;
public final class Testsss$
{
public static final Testsss$ MODULE$;
static {
MODULE$ = new Testsss$();
}
public void main(final String[] args) {
int a = 8;
a = 7;
final double b = 3.4;
final long c = 88888L;
final String d = "hello";
final boolean e = true;
final float f = 3.14f;
final Tuple2 tuple2 = new Tuple2((Object)"test", (Object)BoxesRunTime.boxToBoolean(true));
if (tuple2 != null) {
final String g = (String)tuple2._1();
final boolean h = tuple2._2$mcZ$sp();
if (g != null) {
final String s = g;
if (true) {
final Tuple2 tuple3 = new Tuple2((Object)s, (Object)BoxesRunTime.boxToBoolean(h));
final String g2 = (String)tuple3._1();
final boolean h2 = tuple3._2$mcZ$sp();
final ObjectRef i = ObjectRef.create((Object)new String[3]);
((String[])i.elem)[0] = "hi ";
((String[])i.elem)[1] = " , ";
((String[])i.elem)[2] = " .... ";
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])i.elem).length - 1).foreach$mVc$sp((Function1)(x -> Predef$.MODULE$.print((Object)((String[])i.elem)[x])));
Predef$.MODULE$.println();
final ObjectRef j = ObjectRef.create((Object)new String[] { "hello ", "xiao ", "hua " });
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])j.elem).length - 1).foreach$mVc$sp((Function1)(x -> Predef$.MODULE$.print((Object)((String[])j.elem)[x])));
Predef$.MODULE$.println();
final ObjectRef k = ObjectRef.create((Object)new String[3][]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[][])k.elem).length - 1).foreach$mVc$sp((Function1)(x -> {
final ObjectRef t = ObjectRef.create((Object)new String[3]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])t.elem).length - 1).foreach$mVc$sp((Function1)(y -> ((String[])t.elem)[y] = new StringBuilder(1).append(y).append(" ").toString()));
((String[][])k.elem)[x] = (String[])t.elem;
}));
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[][])k.elem).length - 1).foreach$mVc$sp((Function1)(x -> {
final ObjectRef t = ObjectRef.create((Object)((String[][])k.elem)[x]);
RichInt$.MODULE$.to$extension(Predef$.MODULE$.intWrapper(0), ((String[])t.elem).length - 1).foreach$mVc$sp((Function1)(y -> Predef$.MODULE$.print((Object)((String[])t.elem)[y])));
Predef$.MODULE$.println();
}));
return;
}
}
}
throw new MatchError((Object)tuple2);
}
private Testsss$() {
}
}
可以看到,scala变量默认是final类型的,即使你使用var修饰,他在实现的时候依然用final实现的。
只有真正变量的值发生了改变,此时才去掉了final修饰。
如果我们先初始化为一个值a,然后将变量的值修改为b,然后在修改回a,那么编译器会进行优化吗?
类似上面,继续试验


根据反编译的代码看出,编译器没有进行优化,此时变量也没有用final修饰。
1.3.scala元组最多放22个值
继续看反编译的代码,发现scala对元组做了语法糖。
在scala中直接用元括弧括起来就行。
实际编译时,生成了Tuple2对象
scala.Tuple2
我们看scala库

我们做个试验,如果大于22个,会不会编译失败?
果真编译失败
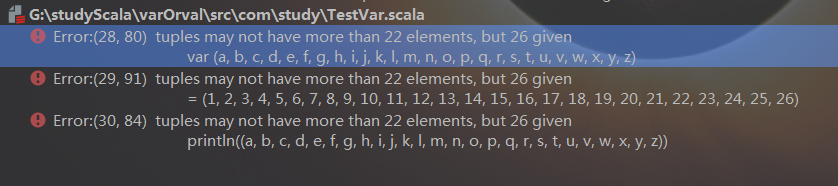
所以,scala中Tuple,Product,Function最大长度都是22个,超过会编译异常。
1.4.元组存储都是以Object存储

理论上元组可以放任何值,所以元组存储数据使用Object存储。
从元组中取数据时,因为此时元组中存储的是Object,所以,取出来后,需要向下转型。
使用强制类型转换进行转。
1.5.scala中声明的同时进行初始化最优
我们在scala中写了一个数组,用2种方式实现:
1.先声明大小,然后在进行赋值
2.在声明的同时赋值,不指定大小
scala如下:

我们看看反编译后的代码:

区别倒是不太大,第一种需要多步完成,第二种一步到位。
1.6.scala for(a <- 0 to n) <- 语法糖
scala中的语法糖,实际上调用的是foreach方法,然后用lambda的方式执行foreach里面的操作。

1.7.scala => 语法糖
在scala中有这样一种写法:
定义一个变量,然后将函数赋值给变量:

我们看下Java代码
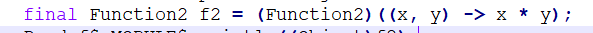
可以看到, => 语法糖将后面的内容,即lambda表达式直接强转为Function.
在scala的库中,有
和jdk8中的lambda完全是一个东西:

2.函数
scala函数使用def进行定义。
scala函数比较有意思。
- 1.当函数体比较小时,可以省略华括弧
- 2.函数可以当做变量的值
- 3.函数没有参数,可以省略元括弧
- 4.函数名字可以包含符号。
2.1 函数定义
2.1.1 无参函数

在scala语言中,如果函数没有参数,可以省略小括弧,同时如果函数的操作只有一行,可以直接用等号引出。类似定义变量赋值一样。
上面的代码等价:
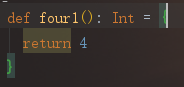
很明显第一种写法更加简单明了。
告诉你,four就是4,等价于4.
其实这个定义和变量是一样的,只是关键词不同,最终使用的结果是一样的。
接下来就看看class被反编译后的Java代码吧

可以看出,反编译后的java代码和我们第二种写法很类似的。
2.1.2 有参函数
除了无参函数,当然有有参函数。


可以看出scala代码和Java代码进行比较,scala代码的密度较大。
同时也更加简单明了。
2.1.3 可变参数函数
在Java中就有可变参数方法,scala中当然有。

对应的Java代码

可以发现Java代码比scala还少,帆船了?。
没有,只是Java有 -> 语法糖,而scala中废弃了这个 -> 语法糖

scala在不使用java的 -> 语法糖,然后封装了自己的 => 语法糖。。
嗯,不知道为啥。。。。
猜到一点,Java的 -> 无法进行转换:

转为
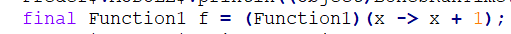
所以,scala不使用 -> ,而是自己封装了 =>
所以scala的可变参数函数和Java都差不多,用类似数组结构存储可变参数。
2.2 函数部分应用
你可以使用下划线“_”部分应用一个函数,结果将得到另一个函数。Scala使用下划线表示不同上下文中的不同事物,你通常可以把它看作是一个没有命名的神奇通配符。
假设有函数:

是的,发现了一个和java不一样的地方,scala的参数可以分开写。。。。
这个函数的Java代码如下:

调用

部分应用:

Java代码
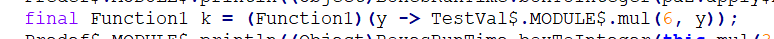
发现这个部分应用是用lambda的方式调用元函数的。
部分应用后调用

当然的,常规的函数,在任意参数都可以部分应用:
在看个例子


将 _看作lambda中的局部变量就行。
如果需要多个 _可以在 _后面加入数字即可。
_1
2.3 柯里化函数
首先贴一张百度百科的图解释什么是柯里化

通俗的讲
允许别人一会在你的函数上应用一些参数,然后又应用另外的一些参数。
例如一个乘法函数,在一个场景需要选择乘数,而另一个场景需要选择被乘数。
实际上就是部分应用。
只不过,部分应用是使用柯里化原理实现的。
这两个是一个玩意。
