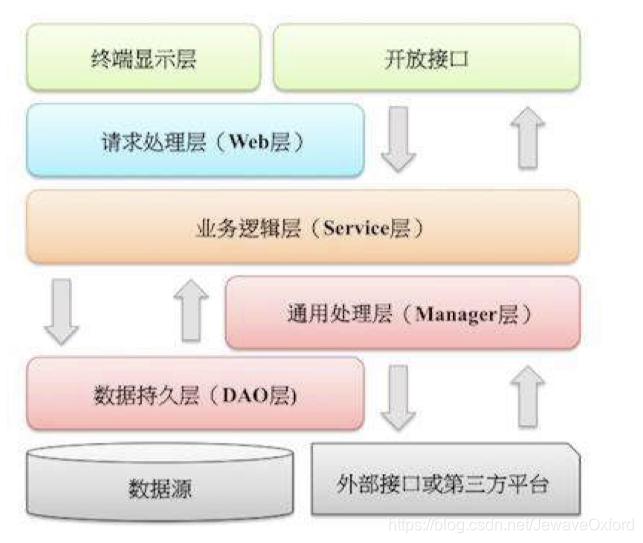
应用分层
- 默认上层依赖下层,箭头关系表示直接依赖(比如开放接口可以依赖于Web层,也可以直接依赖于Service层)
- 开放接口层: 可以直接封装Service方法暴露成RPC接口; 通过Web封装成接口; 进行网关安全控制,流量控制等
- 终端显示层: 各个端的模板渲染并执行显示的层. 当前主要是velocity渲染,JS渲染,JSP渲染,移动端展示等
- Web层: 主要对访问控制进行转发,各类基本参数校验,或者不复用业务的简单处理等
- Service层: 相对具体的业务逻辑服务层
- Manager层: 通用业务处理层,具有以下特征:
- 对第三方平台封装的层,预处理返回结果及转化异常信息
- 对Service层通用能力下沉,比如缓存方案,中间件通用处理
- 与DAO层交互,对多个DAO的组合复用
- DAO层: 数据访问层,与底层MySQL,Oracle,HBase等进行数据交互
- 外部接口或第三方平台: 包括其它部门的RPC开放接口,基础平台,其它企业的HTTP接口
- 分层异常处理规约:
- DAO层:
- 产生的异常类型有很多,无法用细粒度的异常进行catch
- 使用catch(Exception e) 方式,并throw new DAOException(e)
- 不需要打印日志,因为日志在Manager或者Service层一定需要捕获并打印到日志文件中去,如果同台服务器再打印日志,会浪费性能和存储
- Service层:
- 出现异常时,必须记录出错日志到磁盘,尽可能带上参数信息,相当于保护案发现场
- Manager层:
- 如果Manager层与Service同机部署,日志方式与DAO层处理一致
- 如果是单独部署,采用与Service一致的处理方式
- Web层:
- Web层绝对不允许继续往上抛异常,因为已经处于顶层
- 如果意识到这个异常将导致页面无法正常渲染,应该直接跳转到友好错误页面,加上用户容易理解的错误提示信息
- 开放接口层:
- 分层领域模型规约:
- DO: Data Object, 此对象与数据库表结构一一对应,通过DAO层向上传输数据源对象
- DTO: Data Transfer Object, 数据传输对象 ,Service或者Manager向外传输的对象
- BO: Business, 业务对象,由Service层输出的封装业务逻辑对象
- AO: Application Object, 应用对象,在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高
- VO: View Object, 显示层对象,通常是Web向模板渲染引擎层传输的对象
- Query: 数据查询对象,各层接收上层的查询请求. 注意超过2个参数的查询封装,禁止使用Map类来传输
二方库依赖规约
- 定义GAV遵循以下规则:
- GroupID格式: com.[公司/BU].业务线[.子业务线]
- 最多4级
- 子业务线可选
- com.taobao.jstorm, com.alibaba.dubbo.register
- ArtifactID格式: 产品线-模块名
- 语义不重复不遗漏
- 先到中央仓库查证一下
- dubbo-client, fastjson-api
- Version: 主版本号.次版本号.修订号
- 主版本号: 产品方向更改,或者大规模的API不兼容,或者架构不兼容升级
- 次版本号: 保持相对兼容性,增加主要功能特性,影响范围极小的API不兼容修改
- 修订号: 保持完全兼容性,修复BUG,新增次要功能特性
- 注意起始版本号为: 1.0.0,而不是 0.0.1.
- 正式发布的类库必须先去中央仓库进行查证,使版本号有延续性,正式版本号不允许覆盖升级
- 线上应用不要依赖SNAPSHOT版本,除了安全包以外
- 不依赖SNAPSHOT版本是保证应用发布的幂等性
- 同时也可以加快编译时的打包构建
- 二方库的新增或升级,保持除功能点之外的其它jar包不变
- 如果有改变,必须明确评估和验证,建议进行dependency:resolve前后信息比对
- 如果仲裁结果完全不一致,那么通过dependency:tree命令,找出差异点,进行 < excludes > 排除jar包
- 二方库可以定义枚举类型,参数可以使用枚举类型,但是接口返回值不允许使用枚举类型或者包含枚举类型的POJO对象
- 依赖于一个二方库群时,必须定义一个统一的版本变量,避免版本号不一致
- 依赖springframework-core, -context, -beans. 都是同一个版本号,可以定义一个变量来保存版本
- ${spring.version}, 定义依赖的时候,引用该版本
- 禁止在子项目的pom依赖中出现相同的GroupId, 相同的ArtifactId, 但是不同的Version
- 在本地调试时会使用各子项目指定的版本号,但是合并成一个war, 只能有一个版本号出现在lib目录中
- 可能出现线下调试是正确的,发布到线上去出现故障问题
- 所以pom文件中的依赖声明放在 < dependencies > 语句块中,所有版本号仲裁放在 < dependencyManagement > 语句块中
- < dependencyManagement > 里只是声明版本,并不实现引入
- 需要子项目显式的声明依赖 ,version和scope都读取自父pom
- < dependencies > 所有声明在主pom的 < dependencies > 里的依赖都会自动导入,并默认被所有的子项目继承
- 二方库不要有配置项,最低限度不要再增加配置项
- 为了避免应用二方库的依赖冲突问题,二方库发布者应当遵循以下原则:
- 精简可控原则:
- 移除一切不必要的API和依赖,只包含Service API, 必要的领域模型对象, Utils类, 常量, 枚举等
- 如果依赖其它二方库,尽量是provided引入,让二方库使用者去依赖具体的版本号
- 无log的具体实现,只依赖日志框架
- 稳定可追溯原则:
- 每个版本的变化应该被记录,二方库维护信息,源码位置,都需要能够方便查到
- 除非用户主动升级版本,否则公共二方库的行为不应该发生变化
服务器规约
- 高并发的服务器要调小TCP协议的time_wait时间
- 操作系统默认240秒后,才会关闭处于time_wait状态的连接
- 在高并发访问下,服务器端会因为处于time_wait的连接数太多,可能无法建立新的连接
- 所以需要在服务器上调小此等待值
- 在linux服务器上通过变更 /etc/sysctl.conf文件去修改该缺省值(s)
net.ipv4.tcp_fin_timeout = 30
- 调大服务器所支持的最大文件句柄数(fd, File Descriptor)
- 主流操作系统的设计是将TCP/UDP连接采用与文件一样的方式去管理,即一个连接对应于一个fd
- 主流的linux服务器默认支持的最大fd数量为1024, 当并发连接数很大时很容易因为fd不足出现 “open too many files” 错误,导致新的连接无法建立
- 需要将linux服务器支持的最大句柄数调高数倍,与服务器内存数量相关
- 给JVM环境参数设置 -XX: +HeapDumpOnOutOfMemoryError 参数,使JVM遇到OOM场景时输出dump信息
- OOM的发生是有概率的,甚至相隔数月才出现一例,出错时的堆内信息对解决问题非常有帮助
- 在线上生产环境 ,JVM的Xms和Xmx设置一样大小的内存容量,避免在GC后调整堆大小带来的压力
- 服务器重定向
- 服务器内部重定向使用forward
- 服务器外部重定向地址使用URL拼装工具类来生成,否则会带来URL维护不一致问题和潜在的安全风险
