最近碰到了一个需求,需要根据公司的名称,生成一个临时的logo,并以base64图片的形式在网页上显示。这个问题拆解一下,可以分为如下两个问题:
- 显示什么?即公司名称中的哪一部分需要显示出来。
- 怎么显示?即怎么把文字转成图片,并处理好排版问题。
用python把文字转图片其实很好做,随便搜一下就能找到一大堆。我找到了一位大佬(Phodal Huang)的文字转图片的实现,本文中关于图片转文字的实现中有一部分参考了Phodal Huang大佬的实现(已和作者取得了二次开发的许可,且使用的字体为开源字体)。
参考文章介绍
文章地址:Python PIL 转换文字到Logo
实现效果:

因我这里有不少额外需求,且Phodal Huang大佬是用Python2实现的,而我要用python3,很多地方都不兼容,所以只能作为参考。下面记录我的实现过程。
转载请注明来源:https://blog.csdn.net/aaronjny/article/details/100140271
一、对文本信息进行处理
程序的输入可能是公司的全称,如北京市xxxx科技有限公司,也可能是简称,如轻松筹(这里不知道涉不涉及版权相关问题,如侵权请联系,我会修改删除)。显然,当输入的是完整公司名称时,直接将公司名称转换为图片并不友好,提取它的商号转成图片可能会更加合适。比如北京市xxxx科技有限公司,可以简单提取xxxx作为它的商号。
这部分的主要代码如下:
def extract_trade_name(self, text):
"""
对文本数据进行处理,提取商号
Args:
text: 待提取商号的文本
Returns:
str: 提取出的商号
"""
# 将全角括号转换为半角括号
text = text.replace('(', '(').replace(')', ')')
# 移除文本中的括号及括号内的内容
while '(' in text and ')' in text:
lindex = text.index('(')
rindex = text.index(')')
if lindex > rindex:
break
text = text[:lindex] + text[rindex + 1:]
# 使用特定字符切分字符串,如`/`,`-`等
split_chars = self.config_data['split_chars']
for ch in split_chars:
# 注意,这里是循环切割,最后text相当于在原text使用这些字符切割后,
# 最前面的一个元素
text = text.split(ch)[0]
# 移除城市特征
cities = self.config_data['cities']
for city in cities:
text = text.replace(city, '')
# 移除公司后缀
company_suffixes = self.config_data['company_suffixes']
for suffix in company_suffixes:
text = text.replace(suffix, '')
# 返回商号
return text
主要做的工作大致如下:
- 移除文本中的括号及括号内的内容
- 有多个商号信息时保留第一个,如
轻松筹/众筹空间,处理后的结果为轻松筹。 - 移除城市特征,如
北京、北京市。有一点要注意的是,先使用较长的城市特征去尝试,比如北京和北京市,如果先用北京去replace的话,最后会多一个市无法去掉。 - 移除公司后缀,如
科技有限公司、责任有限公司等。
我们可以做几个测试:
| 输入 | 输出 |
|---|---|
| 轻松筹/众筹空间 | 轻松筹 |
| 深圳刷宝科技有限公司 | 刷宝 |
| 京东数字科技控股有限公司 | 京东数字科技控股 |
| 深圳市宁远科技股份有限公司 | 宁远科技 |
| 一起牛(齐牛金融) | 一起牛 |
(以上所有公司名称,侵删)
效果可以接受。
二、对文本进行排版
当文本比较长的时候,可能会出现换行。但直接换行的话,容易把连贯的词语拆开,观感不太好。所以就想到了对文本进行分词,再根据分词结果安排每一行显示的内容,并对显示进行居中处理。
核心代码如下:
def cal_text_length(self, text):
"""
计算文本显示需要的单位长度数量。
英文字符为0.5单位长度,中文单位为1单位长度
Args:
text: 需要计算长度的本文
Returns:
float: 给定文本显示需要的单位长度数量
"""
length = 0
for ch in text:
if ch in self.letters:
length += 0.5
else:
length += 1
return length
def array_text(self, text):
"""
对给定文本进行分词,并根据分词结果和单词长度,安排文字在图片上显示的位置(通过加入换行和空白来实现)。
同时,计算文字在图片上占据的高和宽
Args:
text[str]: 需要显示的文本
Returns:
str,int,int: 处理后的文本,文本最大宽度,文本高度
"""
# 先对文本进行分词
words = list(jieba.cut(text))
# 用于按行保存要在图片上显示的文本的列表
_res = []
# 当前行缓存字符串
current_buff = ''
# 遍历分词结果,图片上每行最多显示6个单位长度,如果当前行长度超过6单位长度,
# 则另起一行,将单词加入到新行中
for word in words:
if self.cal_text_length(current_buff + word) <= 6:
current_buff = current_buff + word
else:
_res.append(current_buff)
current_buff = word
if current_buff:
_res.append(current_buff)
# 计算所有行中,最长的那一行的长度
max_width = max(map(self.cal_text_length, _res))
# 计算总行数
max_height = len(_res)
# 对上面的数据重新加工一下,通过添加空白的方式,使得文本居中显示
res = []
for seq in _res:
# 计算需要填充的空白数
padding_spaces = max_width - self.cal_text_length(seq)
# 进行填充
res.append(' ' * int(padding_spaces) + seq + ' ' * int(padding_spaces))
# 将所有行的文本使用换行符拼接成一个文本,返回(拼接后文本,最大宽度,最大高度)
return '\n'.join(res), max_width, max_height
这部分没有特别需要注意的地方,注释也比较清晰,就不多少了。效果嘛…整体显示效果好了不少,但是有个别的看起来还是比较别扭。emmmm,聊胜于无吧。
三、配色和字体选择
配色和字体方面的话,我就没自己折腾了。字体是直接使用了Phodal Huang大佬上传的字体,配色的话也是从给出的几种配色中选择了我比较喜欢的一种。
class Converter:
"""
能够将企业名称转换成logo的转换器
"""
def __init__(self, colors=None, font_path='NotoSansCJKsc-Regular.otf'):
# 文字配色
if colors:
self.bg_color, self.front_color = colors
else:
self.bg_color, self.front_color = '34495e', 'ecf0f1'
# 显示字体
self.font_path = font_path
# 用于处理文本的格式化器
self.text_formatter = TextFormatter()
配色给定的是16进制的颜色编码,需要转码成rgb。因为兼容问题,这部分我重新实现了下,并加了一些容错的处理。
@staticmethod
def hex2rgb(hex_color):
"""
将16进制颜色编码,转换为rgb格式
Args:
hex_color[str]: 16进制颜色编码
Returns:
tuple: (r,g,b)
"""
if isinstance(hex_color, str):
color = int(hex_color[:2], 16), int(hex_color[2:4], 16), int(hex_color[4:], 16)
elif (isinstance(hex_color, tuple) or isinstance(hex_color, list)) and len(hex_color) == 3:
color = hex_color
else:
raise Exception('给定的图片配色不正确!')
return color
接下来,就是文字转图片的核心代码了,可接受参数看方法注释,很清晰:
def text2image(self, text, font_size=48, width=400, height=140, need_extracted=True, need_arrayed=True,
show_image=False):
"""
将给定文字转换成指定大小的图片。
可以通过调整参数改变图片的效果。
Args:
text: 需要转换成图片的文本
font_size: 文字大小
width: 图片的宽度,默认 400
height: 图片的高度,默认 140
need_extracted: 如果给定的文本是公司名称,是否需要提取商号来生成图片,默认进行提取
need_arrayed: 是否需要通过分词等处理方法,对文本进行排列,获得更好的显示效果,默认进行处理
show_image: 是否显示图片,默认不显示
Returns:
str: 生成的图片的base64转码
"""
# 如果需要,从文本中提取商号,替代原文本
if need_extracted:
text = self.text_formatter.extract_trade_name(text)
print(text)
# 如果需要,对文本进行排列,以获得更好的显示效果
if need_arrayed:
text, max_width, max_height = self.text_formatter.array_text(text)
else:
max_width = self.text_formatter.cal_text_length(text)
max_height = 1
# 获取rgb配色
bg_color = self.hex2rgb(self.bg_color)
front_color = self.hex2rgb(self.front_color)
# 开始绘制
img = Image.new('RGB', (width, height), bg_color)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(self.font_path, font_size)
# 按字体大小缩放,计算真实宽高
w = max_width * font_size
h = max_height * font_size
# 居中
draw.text(((width - w) / 2, (height - h) / 2), text, font=font, fill=front_color)
del draw
# 转RGB
img = img.convert('RGB')
# 如果需要,就显示图片
if show_image:
img.show()
# 将图片转为base64字符串返回
output_buffer = BytesIO()
img.save(output_buffer, format='JPEG')
byte_data = output_buffer.getvalue()
base64_str = base64.b64encode(byte_data).decode('utf8')
return base64_str
把对文本的处理做成了可选参数,如果想要将文本原封不动地转成图片,直接将need_extracted和need_arrayed设为false即可,这两项默认开启。
如果想要本地生成的图片,将show_image设为true即可,默认关闭。
我们可以尝试生成一下图片,测试代码如下:
from text2logo import Converter
def run():
converter = Converter()
img_base64_str = converter.text2image(‘xxx’,show_image=True)
print(img_base64_str)
if __name__ == '__main__':
run()
输入1:
img_base64_str = converter.text2image(‘轻松筹/众筹空间’, font_size=100, show_image=True, need_extracted=True)
输出1:
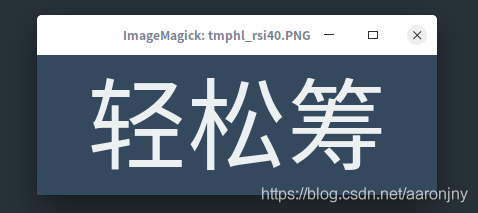
输入2:
img_base64_str = converter.text2image('深圳刷宝科技有限公司', font_size=100, show_image=True)
输出2:
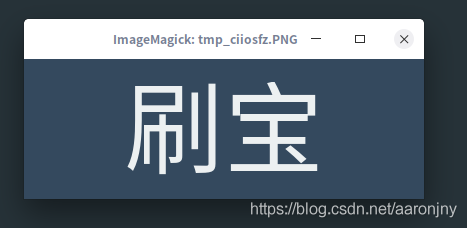
输入3:
img_base64_str = converter.text2image('京东数字科技控股有限公司', show_image=True)
输出3:

输入4:
img_base64_str = converter.text2image('深圳市宁远科技股份有限公司', font_size=64, show_image=True)
输出4:
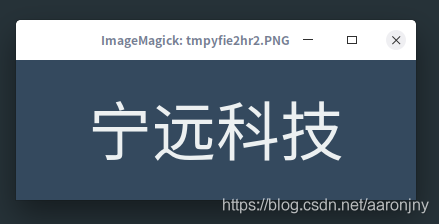
输入5:
img_base64_str = converter.text2image('一起牛(齐牛金融)', font_size=100, show_image=True)
输出5:

(以上所有公司名称和生成的图片,侵删)
整体来说,效果还不错,可以接受,能满足我的需求。
四、在网页中嵌入base64图片
从上面的代码可以看到,我的实现中文字转图片返回的是一个字符串,内容是生成的图片的base64编码。那么,如果我们拿到这个编码,怎么在网页中显示呢?
很简单,先创建一个最简单的html,然后在里面加上img标签。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img src="data:image/jpeg;base64, xxxxxxx"></img>
</div>
</body>
</html>
只需要将上面的xxxxxxx替换成我们获得的base64字符串即可。
让我们在浏览器里打开看一下:
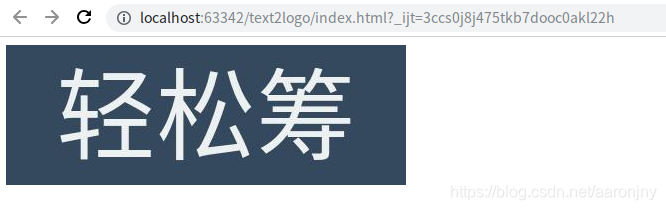
okay,完全没有问题,收工!
完整代码
完整代码以开源到github上,地址:
点击 text2logo 或访问 https://github.com/AaronJny/text2logo
彩笔一个,文章或代码中若存在问题,请斧正。
本文涉及到的全部公司名称均为随意从互联网上选取的,撰写本文也只为技术交流。本文涉及到的全部公司名称和生成的图片,如若侵犯了您的权益,请联系我。看到后我会即刻修改和删除,感谢您的谅解!
