利用R通过顺企网根据公司名称爬取企业地址
有时我们有公司名称数据但是没有地址,需要根据公司名称找出企业的地址,描述其空间布局,如果数据量很大,手动在网页中操作费时费力,R语言提供了一个解决的办法,前提是该网站能够与机器交互(即没有反爬机制,或者有但限制较小)。其过程如下
1. 首先读取数据并作简单处理
打开顺企网检索某个公司
发现其链接是以下形式,其特征是字符串+“公司名称”构成了一个完整的链接

因此可以对每个公司名称构建url地址,然后根据url地址获取页面信息
#library packeges
> library(readxl)
> library(xml2)
> library(rvest)
> library(stringr)
> #import data
> qy <- read_xlsx("qy_sample.xlsx")
New names:
1. `2016母公司` -> `2016母公司...2`
2. `2016母公司` -> `2016母公司...3`
> qy <- qy[,4]
> names(qy) <- "name"
> #delete repeated data
> qy <- qy[!duplicated(qy),]
> qy$ul <- "http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q="
> qy$url <- paste(qy$ul,qy$name,sep = "")
> qy <- qy[,c(1,3)]
> head(qy)
# A tibble: 6 x 2
name url
<chr> <chr>
1 宁波横河模具股份有限公司 http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=宁波横河模~
2 深圳市朗科智能电气股份有限公司~ http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=深圳市朗科~
3 深圳市联得自动化装备股份有限公司~ http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=深圳市联得~
4 武汉理工光科股份有限公司 http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=武汉理工光~
5 深圳市科信通信技术股份有限公司~ http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=深圳市科信~
6 武汉精测电子集团股份有限公司~ http://so.11467.com/cse/search?s=662286683871513660&ie=utf-8&q=武汉精测电~
2. 根据url地址爬取页面信息
其代码如下:
#create for circulation
n <- length(qy$name)
url_sec <- data.frame()
for (i in 1:n) {
url_i <- read_html(qy$url[i],encoding = "UTF-8") %>% html_nodes(".c-title") %>%html_children() %>%
html_attrs() %>% data.frame() %>% t()
url.sec_i <- url_i[1,3]
name_i <- qy[i,1]
da_i <- cbind(name_i,url.sec_i)
url_sec <- rbind(url_sec,da_i)
print(i)
print(name_i)
}
但是我们只爬取了以下页面信息,还没有获取需要的公司地址信息

最匹配的往往是第一个,然我们尝试打开第一个结果
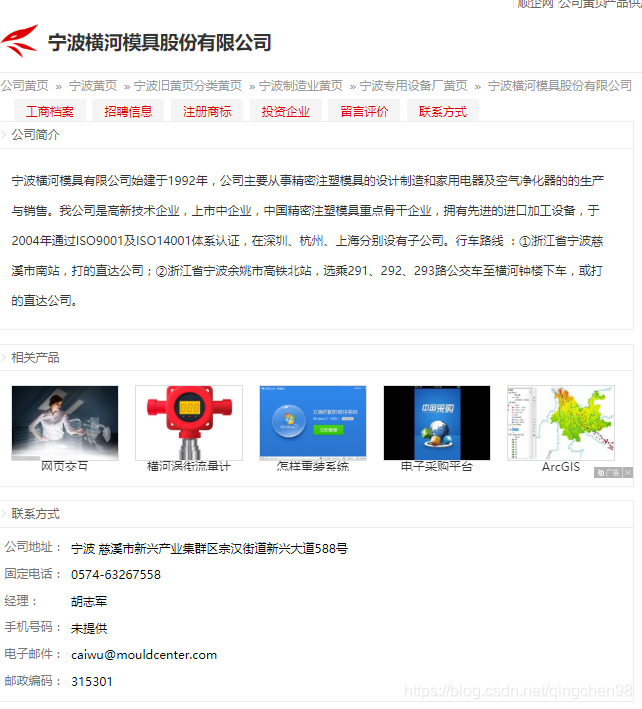
可以看出这个页面的信息正是我们需要的!第二步已经提取了每个公司的页面地址,因此通过二次爬虫即可。
#create for circulation again
n.1 <- length(url_sec$name)
qy.da <- data.frame()
for (i in 1:n.1) {
address.1_i <- read_html(url_sec$url.sec_i[i],encoding = "UTF-8") %>%
html_nodes(".codl") %>% html_text()
address_i <- address.1_i[1]
name_i <- url_sec$name[i]
qy.da_i <- cbind(name_i,address_i)
qy.da <- rbind(qy.da,qy.da_i)
print(i)
print(name_i)
}
其结果如下:

然后提取其中的公司地址,最后根据公司名称与原表匹配即可,匹配问题可参考以前写的文章。