对于XGBoost,相信大家都不陌生了,小白也曾经看了很多次,不过每次都没有很系统的学习,都是在使用过程中,遇到什么问题,就查什么问题,对于整个算法都是“星星点点”的学习,最近几天又看到了这个算法,小白就在学习中总结了一下这个算法的要点。
1.XGBoost描述
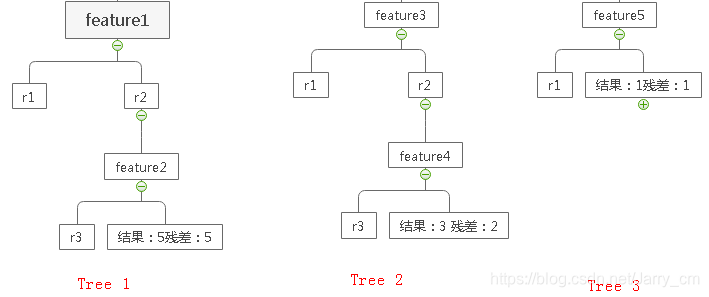
XGBoost是一种集成学习算法,通过回归树,每一次对残差(实际值与预测值之差)进行拟合,最后把预测值相加得到最终的预测值。
比如:灯泡的寿命是10年,经过三棵树的训练,第一颗树的训练结果为5年,那么残差为10-5=5年,在此基础上训练,第二棵树的训练结果为3年,残差为5-3=2年,接着第三棵树,训练结果为1年,残差为2-1=1年,结束,那么这棵树最终预测的寿命=5+3+1=9年,这个结果显然更接近于真实值。
2.浅析XGBoost思路
XGBoost是通过建立K个回归树,使树群的预测值趋近于真实值,且有尽量大的泛化能力,目标函数为:

其中,i:第i个样本,第一个函数:每个样本的预测误差和,误差越小越好,第二个函数:树的复杂度函数,越小泛化能力越强,复杂度越低。函数表达试为:

对于求解,使用二次最优化(贪心策略+最优化):决策时刻按照当前目标最优化决定。
选择feature分裂成两个节点,需要:
1)确定分裂用的feature。枚举所有feature,选择loss function效果最好的那个(关于粗暴枚举,Xgboost的做了改良,以并行方式同时计算每个feature的loss function);
2)如何确立节点的w以及最小的loss function二次函数的求最值(细节的会注意到,计算二次最值是不是有固定套路,导数=0的点)
那么整体就变成:选择一个feature分裂,计算loss function最小值,然后再选一个feature分裂,又得到一个loss function最小值,枚举完,找一个效果最好的,把树给分裂,就得到了小树苗。在分裂的时候,每次节点分裂,loss function被影响的只有这个节点的样本,因而每次分裂,计算分裂的增益(loss function的降低量)只需要关注打算分裂的那个节点的样本。接下来,继续分裂,按照上述的方式,形成一棵树,再形成一棵树,每次在上一次的预测基础上取最优进一步分裂/建树,这就是贪心策略!
3.XGBoost.分裂停止条件
凡是循环迭代的方式必定有停止条件:
(1)当引入的分裂带来的增益小于一个阀值的时候,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有点预剪枝的意思,阈值参数为 γ 正则项里叶子节点数 T 的系数;
(2)当树达到最大深度时则停止建立决策树,设置一个超参数max_depth,这个好理解吧,树太深很容易出现的情况学习局部样本,过拟合;
(3)当样本权重和小于设定阈值时则停止建树,这个解释一下,涉及到一个超参数-最小的样本权重和min_child_weight,和GBM的 min_child_leaf 参数类似,但不完全一样,大意就是一个叶子节点样本太少了,也终止同样是过拟合;
(4)貌似看到过有树的最大数量的…这个不确定
那节点分裂的时候是按照哪个顺序来的,比如第一次分裂后有两个叶子节点,先裂哪一个?答:同一层级的(多机)并行,确立如何分裂或者不分裂成为叶子节点
4.Xgboost的一些重点
1)w是最优化求出来的,不是平均值或规则指定的,这是XGBoost的一个创新;
2)loss function中包含了正则化防止过拟合的技术;
3)支持自定义loss function,只要能泰勒展开(能求一阶导和二阶导)就行;
4)支持并行化,这个地方有必要说明下,因为这是xgboost的闪光点,直接的效果是训练速度快,boosting技术中下一棵树依赖上述树的训练和预测,所以树与树之间应该是只能串行!但是在选择最佳分裂点,进行枚举的时候并行!(这个也是树形成最耗时的阶段)
5)XGBoost还特别设计了针对稀疏数据的算法
假设样本的第i个特征缺失时,无法利用该特征对样本进行划分,这里的做法是将该样本默认地分到指定的子节点,至于具体地分到哪个节点还需要某算法来计算,
算法的主要思想是,分别假设特征缺失的样本属于右子树和左子树,而且只在不缺失的样本上迭代,分别计算缺失样本属于右子树和左子树的增益,选择增益最大的方向为缺失数据的默认方向;
6)可实现后剪枝
7)交叉验证,方便选择最好的参数。
8)行采样、列采样,随机森林的套路(防止过拟合)
9)Shrinkage,前面例子讲的是预测值为每个回归树预测值的加和,这里也可以是加权。举一个例子,比如第一棵树预测值为9,label为10,第二棵树才学1,再后面的树其实结果不是很重要了,所以给他打个折扣,比如5折,这就可以发挥了啦,以此类推,这是为了防止过拟合,如果对于“伪残差”学习,那更像梯度下降里面的学习率;
10)XGBoost还支持设置样本权重,这个权重体现在梯度g和二阶梯度h上,是不是有点adaboost的意思,重点关注某些样本
5.XGBoost参数
在运行XGBoost程序之前,必须设置三种类型的参数:通用类型参数(general parameters)、booster参数和学习任务参数(task parameters)。
一般类型参数general parameters –参数决定在提升的过程中用哪种booster,常见的booster有树模型和线性模型。
Booster参数-该参数的设置依赖于我们选择哪一种booster模型。
学习任务参数task parameters-参数的设置决定着哪一种学习场景,例如,回归任务会使用不同的参数来控制着排序任务。
命令行参数-一般和xgboost的CL版本相关。
5.1Booster参数:
1. eta[默认是0.3] 和GBM中的learning rate参数类似。通过减少每一步的权重,可以提高模型的鲁棒性。典型值0.01-0.2
2. min_child_weight[默认是1] 决定最小叶子节点样本权重和。当它的值较大时,可以避免模型学习到局部的特殊样本。但如果这个值过高,会导致欠拟合。这个参数需要用cv来调整
3. max_depth [默认是6] 树的最大深度,这个值也是用来避免过拟合的3-10
4. max_leaf_nodes 树上最大的节点或叶子的数量,可以代替max_depth的作用,应为如果生成的是二叉树,一个深度为n的树最多生成2n个叶子,如果定义了这个参数max_depth会被忽略
5. gamma[默认是0] 在节点分裂时,只有在分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数值越大,算法越保守。
6. max_delta_step[默认是0] 这参数限制每颗树权重改变的最大步长。如果是0意味着没有约束。如果是正值那么这个算法会更保守,通常不需要设置。
7. subsample[默认是1] 这个参数控制对于每棵树,随机采样的比例。减小这个参数的值算法会更加保守,避免过拟合。但是这个值设置的过小,它可能会导致欠拟合。典型值:0.5-1
8. colsample_bytree[默认是1] 用来控制每颗树随机采样的列数的占比每一列是一个特征0.5-1
9. colsample_bylevel[默认是1] 用来控制的每一级的每一次分裂,对列数的采样的占比。
10. lambda[默认是1] 权重的L2正则化项
11. alpha[默认是1] 权重的L1正则化项
12. scale_pos_weight[默认是1] 各类样本十分不平衡时,把这个参数设置为一个正数,可以使算法更快收敛。
5.2通用参数
1. booster[默认是gbtree]
选择每次迭代的模型,有两种选择:gbtree基于树的模型、gbliner线性模型
2. silent[默认是0]
当这个参数值为1的时候,静默模式开启,不会输出任何信息。一般这个参数保持默认的0,这样可以帮我们更好的理解模型。
3. nthread[默认值为最大可能的线程数]
这个参数用来进行多线程控制,应当输入系统的核数,如果你希望使用cpu全部的核,就不要输入这个参数,算法会自动检测。
5.3学习目标参数
1. objective[默认是reg:linear]
这个参数定义需要被最小化的损失函数。最常用的值有:binary:logistic二分类的逻辑回归,返回预测的概率非类别。multi:softmax使用softmax的多分类器,返回预测的类别。在这种情况下,你还要多设置一个参数:num_class类别数目。
2. eval_metric[默认值取决于objective参数的取之]
对于有效数据的度量方法。对于回归问题,默认值是rmse,对于分类问题,默认是error。典型值有:rmse均方根误差;mae平均绝对误差;logloss负对数似然函数值;error二分类错误率;merror多分类错误率;mlogloss多分类损失函数;auc曲线下面积。
3. seed[默认是0]
随机数的种子,设置它可以复现随机数据的结果,也可以用于调整参数。
以上就是小白最近看到的一些关于XGBoost的内容,可能零零散散大家都看到过,我这里是总结一下,方便自己以后的学习积累。
