前言
你还在,你还在,头悬梁锥刺股。
下,下,下,表情包吗?
你还以为盗个图战胜小学生。
就能成为斗图王吗?
你还把会做图当成斗图资本吗?
你还为斗不过图而痛哭流泪吗?
No no no no no
No no no no no no no
人生苦短
Q群数十小学生变身斗图王的梦想
你可以复制
是时候写个爬虫了
前提准备
本次教程将为您讲解如何爬取斗图啦网的表情包,网址链接:http://www.doutula.com
为完美食用本次教程,需要亲先提前准备好以下编程环境:
python3【博主使用的是3.7】
requests库【版本无要求】
lxml库【需要含有etree模块的才行,博主使用的是4.3.3】
火狐浏览器【这个不一定,看个人习惯】
网页分析
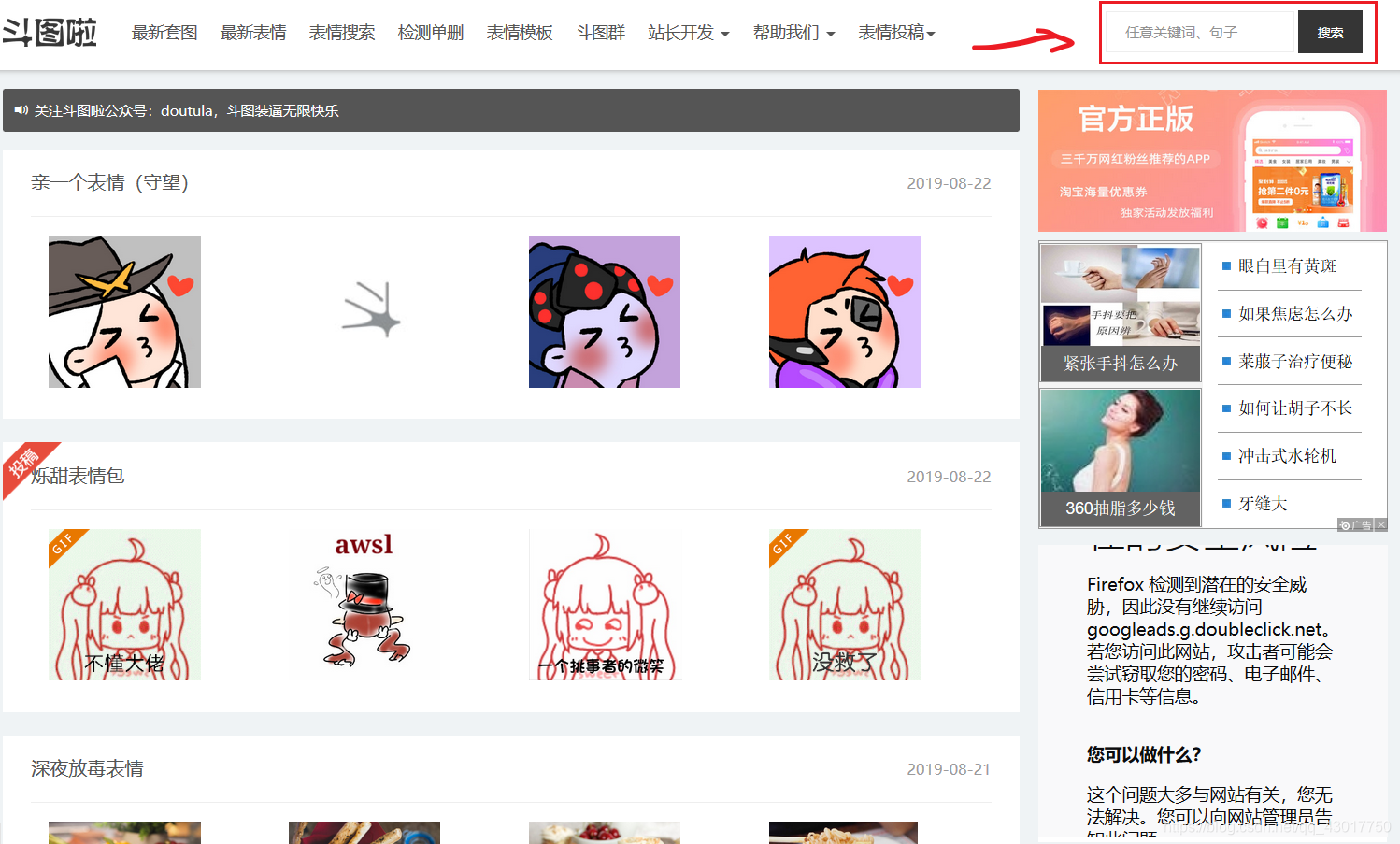
打开斗图啦首页【http://www.doutula.com】。
我们可以看到有许多的表情包,但是我们不是每次都会发全部类型的表情包。
通常采取的是发送符合某个主题或关键字的表情包,所以我们就需要搜索功能。
在红框处的搜索框中输入【女装大佬】,尝试搜索以女装大佬为关键字的表情包,看看网址有何变化。
 搜索之后将会打开如下链接【http://www.doutula.com/search?keyword=女装大佬 】,页面内容如下:
搜索之后将会打开如下链接【http://www.doutula.com/search?keyword=女装大佬 】,页面内容如下:
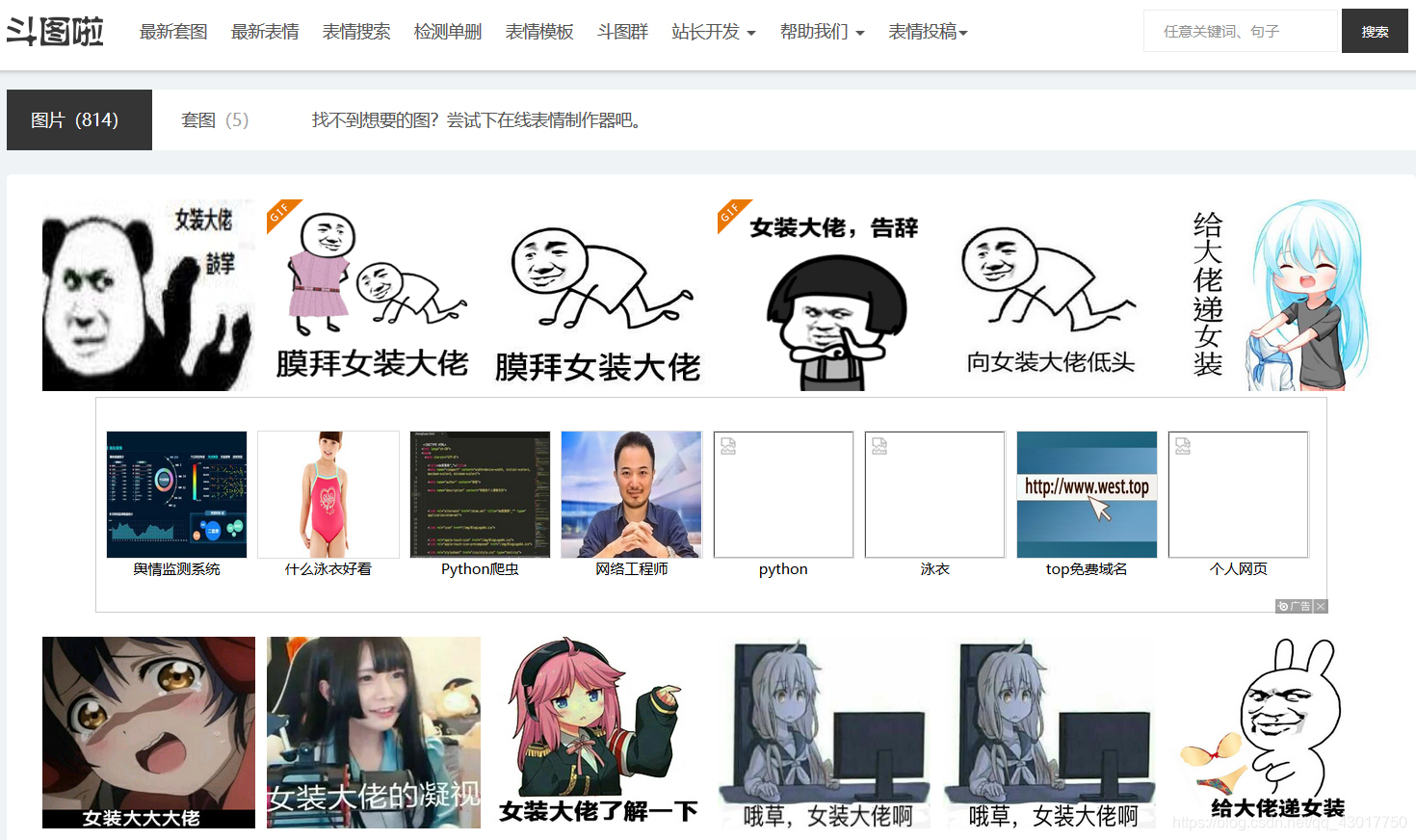 我们可以发现url中【keyword】的参数就是我们搜索的关键字【女装大佬】
我们可以发现url中【keyword】的参数就是我们搜索的关键字【女装大佬】
我们可以大胆的猜测下通过修改【keyword】的值就可以得到对应关键字的表情包的搜索页。
尝试一:
修改【keyword】的值为【金馆长】,看看能否打开金馆长的搜索页面。修改后的网址为:
【http://www.doutula.com/search?keyword=金馆长】
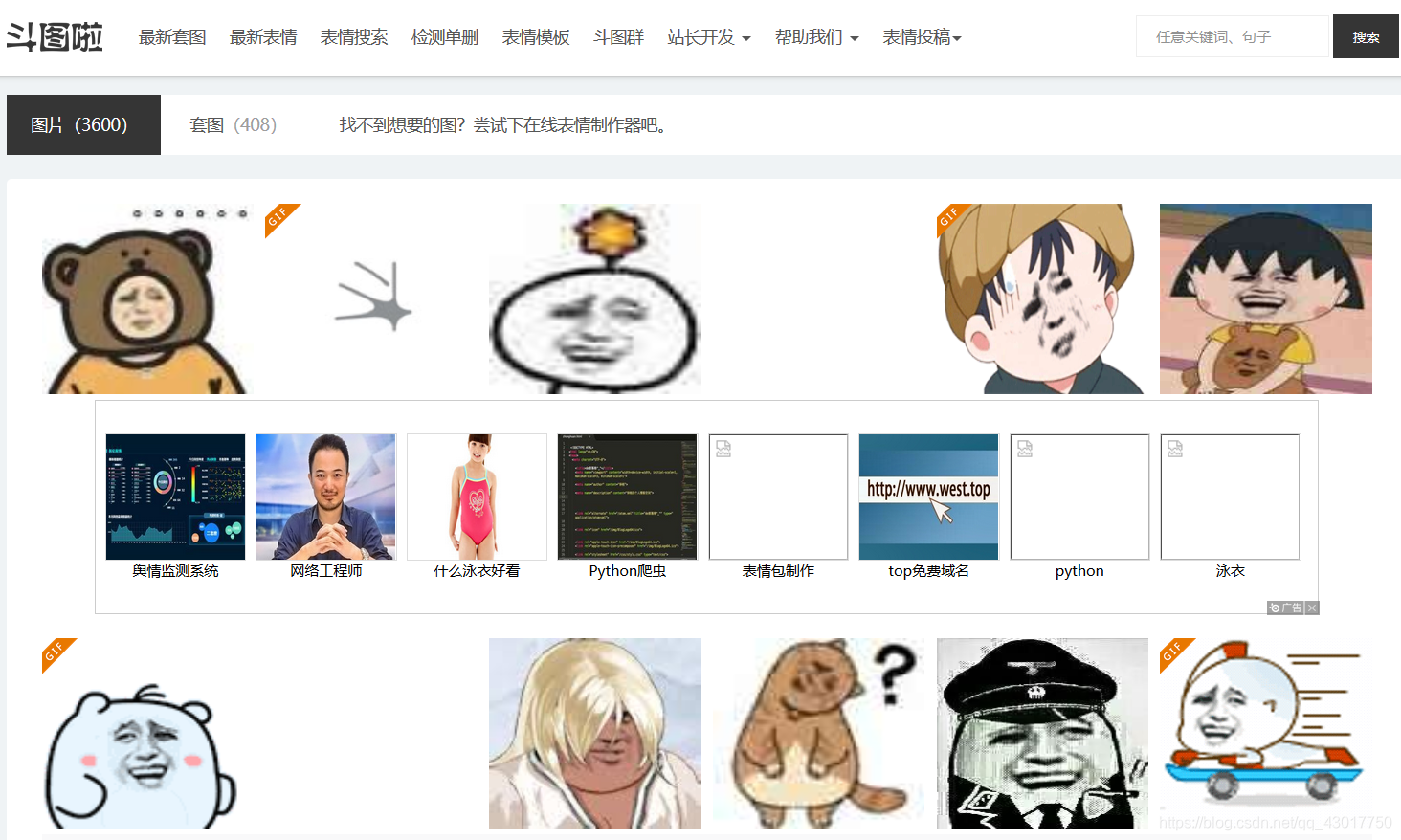 看着页面上桀骜不羁的笑脸,就知道我们打开了金馆长表情包的搜索页
看着页面上桀骜不羁的笑脸,就知道我们打开了金馆长表情包的搜索页
我们再做一次尝试验证我们的想法。
尝试二:
修改【keyword】的值为【你好骚啊】,看看能否打开【品如的衣柜】。修改后的网址为:
http://www.doutula.com/search?keyword=你好骚啊
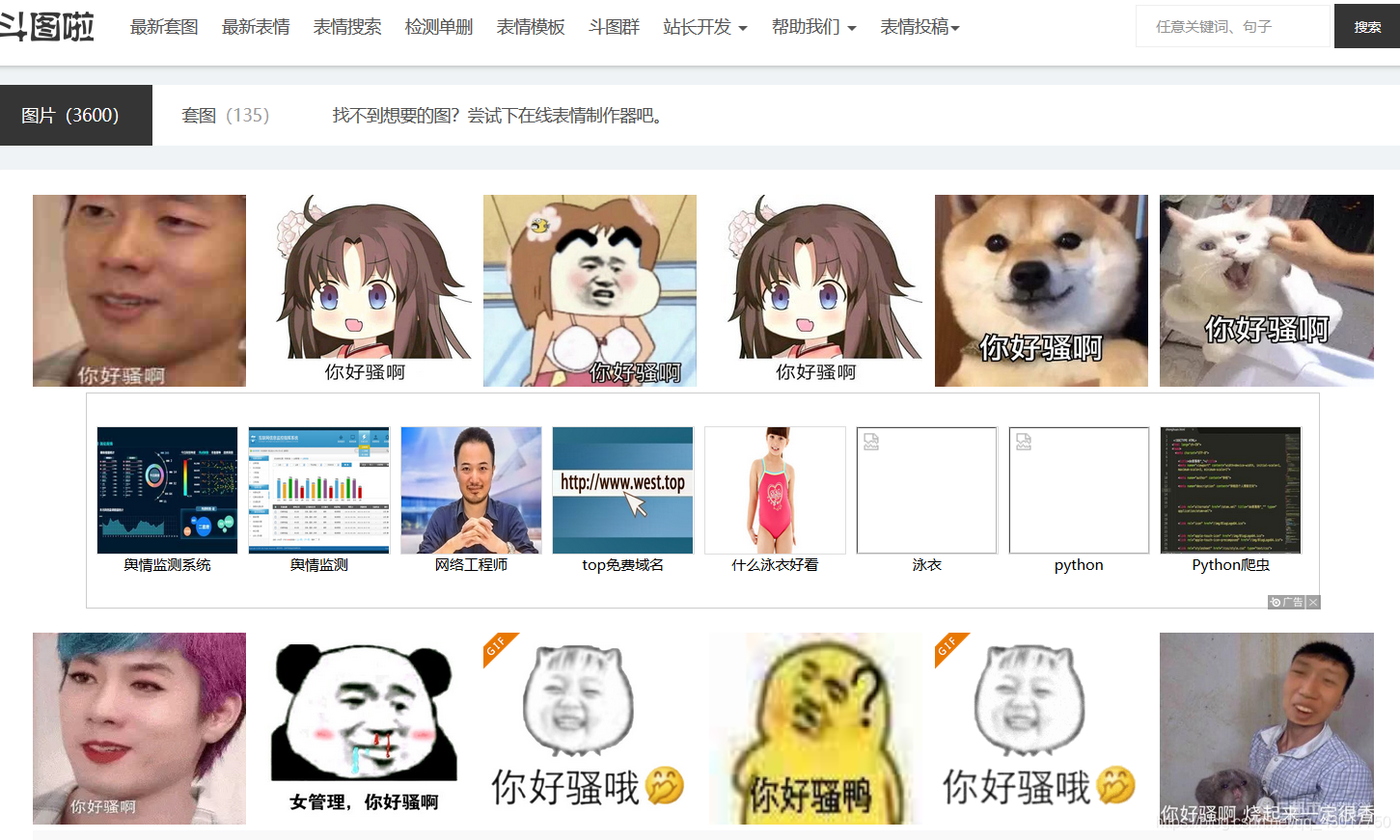 看着这样欲笑又止的侧脸,我知道我成功的打开了品如的衣柜(。・∀・)ノ
看着这样欲笑又止的侧脸,我知道我成功的打开了品如的衣柜(。・∀・)ノ
看到这证明我们猜想是对的,搜索页是通过url中【keyword】的值控制的
我们回到【女装大佬】的搜索页,链接地址:【http://www.doutula.com/search?keyword=女装大佬 】,看看如何获取图片的url。
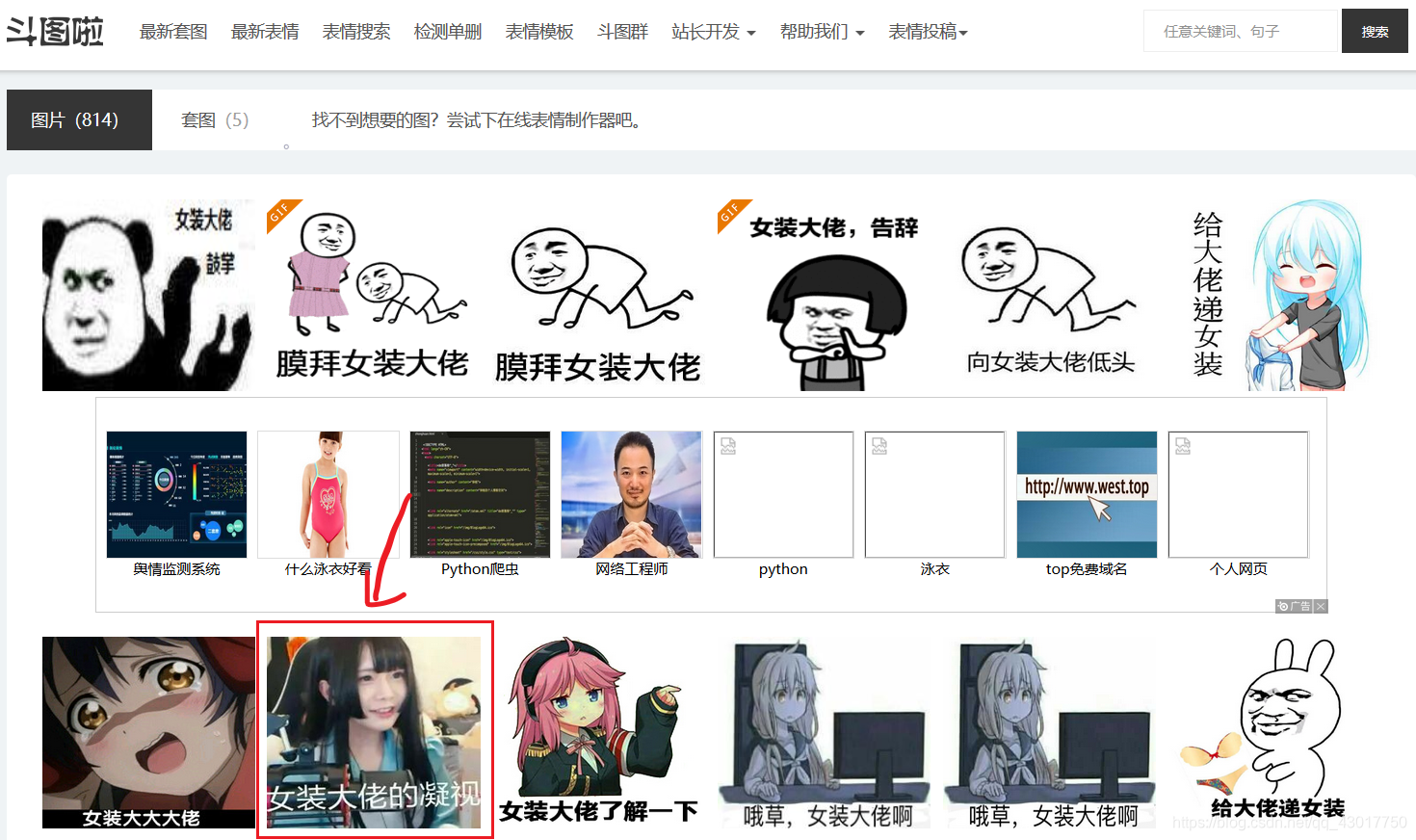 我们再图中红框处的国民扳手的图片上【右键】选择【查看元素】,提取处图片的url地址
我们再图中红框处的国民扳手的图片上【右键】选择【查看元素】,提取处图片的url地址
【http://img.doutula.com/production/uploads/image/2019/03/28/20190328703619_OEuNCP.jpg】
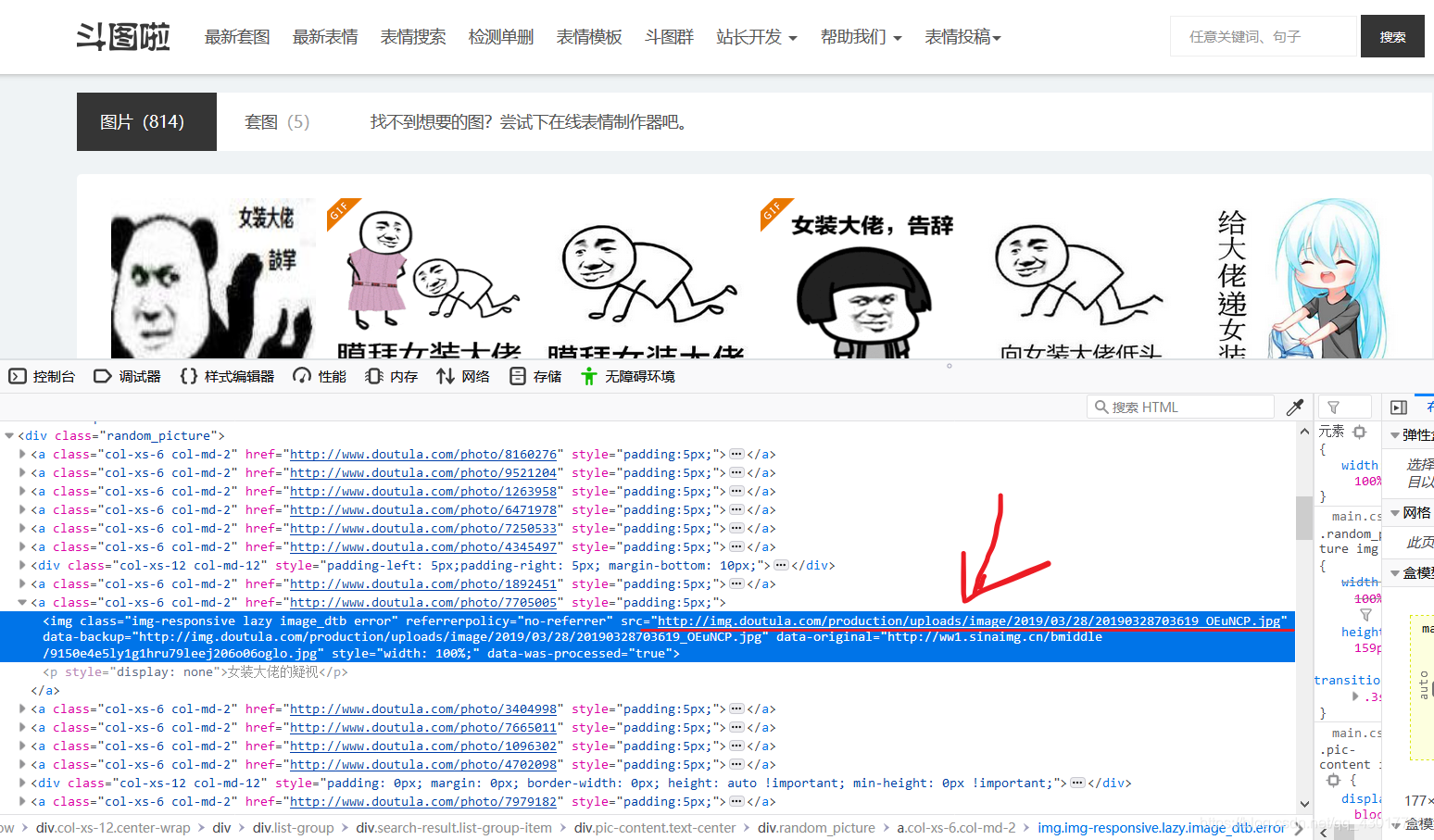 我们在打开这个网址,看看对应的是不是国服扳手的表情包
我们在打开这个网址,看看对应的是不是国服扳手的表情包
 没错,就是那张图片,现在回到【女装大佬】搜索页
没错,就是那张图片,现在回到【女装大佬】搜索页
按【ctrl】+【u】打开页面源代码

按【ctrl】+【f】打开快速搜索框
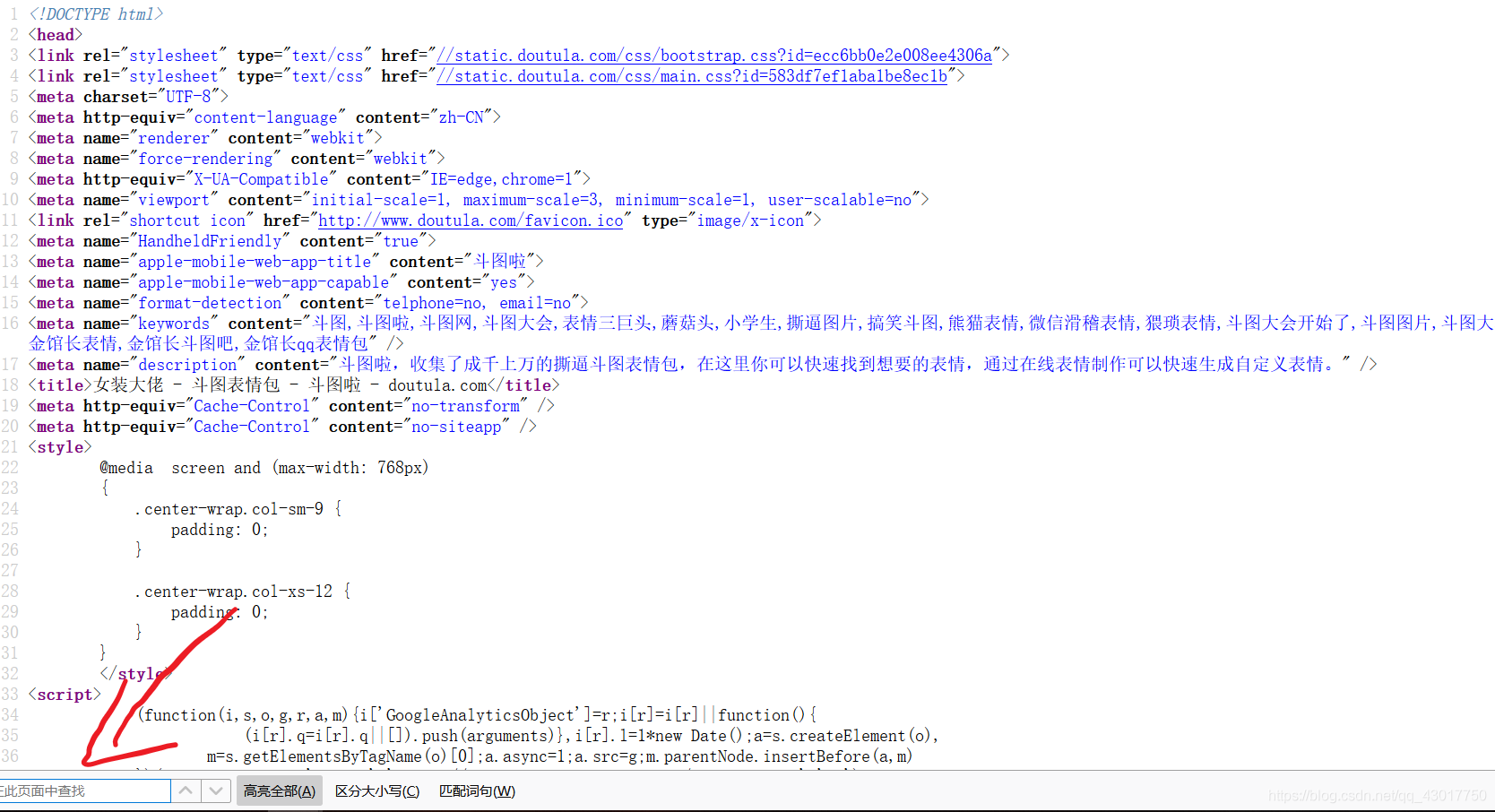 在搜索框中粘贴上我们前面获取的图url,查看在url处于源码里哪个标签中。
在搜索框中粘贴上我们前面获取的图url,查看在url处于源码里哪个标签中。
图片url:【http://img.doutula.com/production/uploads/image/2019/03/28/20190328703619_OEuNCP.jpg】
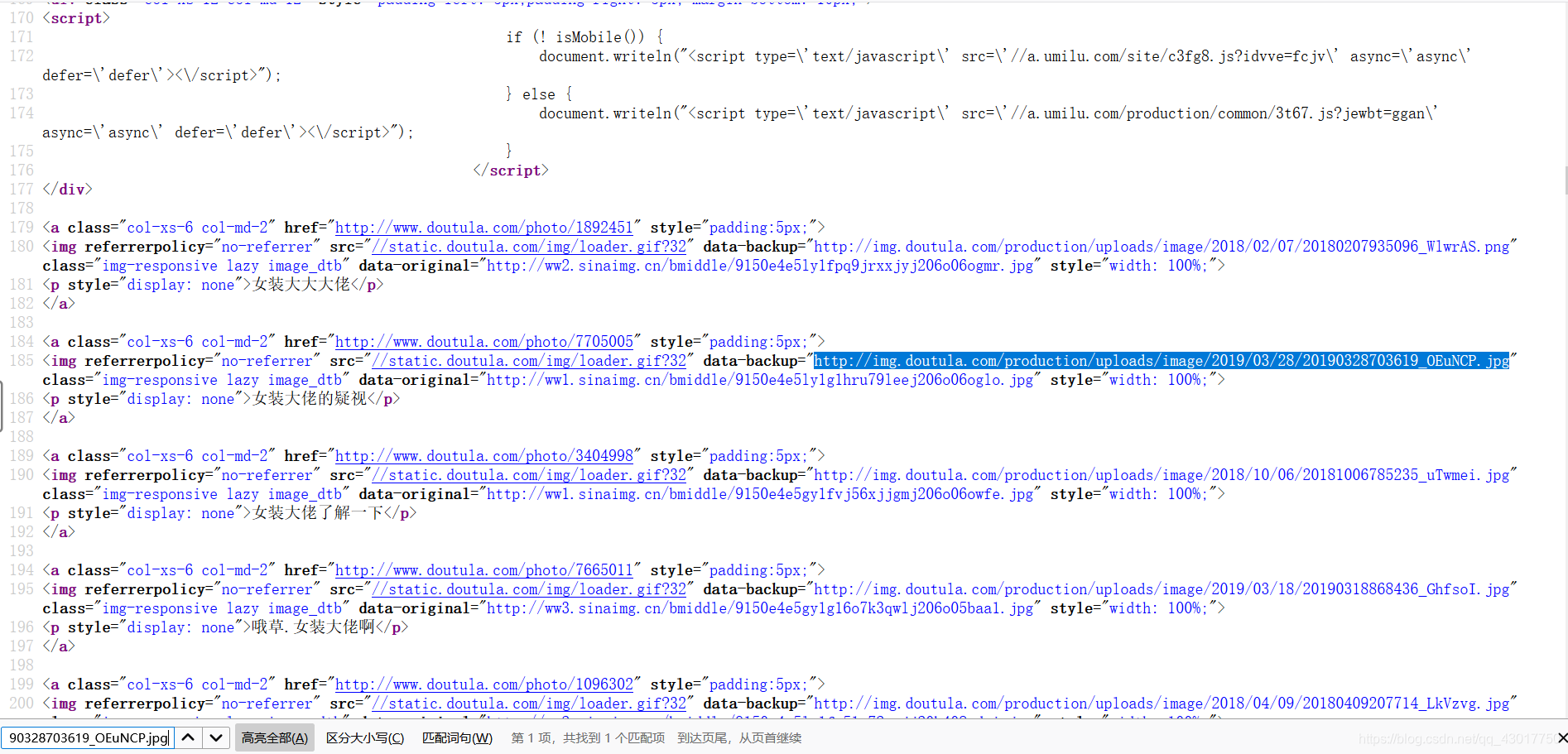 可以看到处于含有class属性值为【“img-responsive lazy image_dtb”】的img标签中的【data-backup】属性里
可以看到处于含有class属性值为【“img-responsive lazy image_dtb”】的img标签中的【data-backup】属性里
最后我们在总结下:
1.通过修改url【http://www.doutula.com/search?keyword=】中【keyword】的值可以打开不同内容的搜索页
2.图片url在网页源码中含有class属性值为【“img-responsive lazy image_dtb”】的img标签中的【data-backup】属性里
现在我们有了思路可以开始写代码了。
代码拆解
- 我们创建一个名为名为【斗图啦爬虫.py】的Python程序文件,并在当前目录中创建一个名为【img】的文件夹作为后期的图片保存使用
2. 接下来就是老生常谈的设置程序信息和导入模块了
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年8月23日
from lxml import etree
import requests
第一行# -*- coding:utf-8 -*-代表设置程序运行时使用的默认编码为utf-8
第二行和第三行分别时记录作者和创作时间
第四行from lxml import etree 从lxml库中导入etree模块,用于后期从网页代码中提取内容
第五行import requests导入requests模块,用于从网站获取资源
3.创建类与函数
class DouTuLa():
def __init__(self,key):
"""参数设置"""
self.key = key
def main(self):
"""控制程序运行"""
pass
doutula = DouTuLa('女装大佬')
doutula.main()
第一行class DouTuLa():我们设置了一个名为DouTuLa的函数
第二至四行我们设置使用这个函数时需要传出一个key关键字,并且将关键字的内容保存到变量self.key中,key关键字用于存储我们要搜索的关键字
第六行至第八行我们设置了一个名为main的函数用于控制程序运行
第九行至第十行我们给类DouTuLa创建了一个doutula实例,并传入了参数【女装大佬】作为表情包搜索参数

4.在__init__函数中添加一些程序中后面要使用的变量
def __init__(self,key):
"""参数设置"""
#设置搜索的表情包关键字
self.key = key
#生成表情包搜索页面url
self.url = "http://www.doutula.com/search?keyword={}".format(key)
#设置网页请求头
self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0'}
5.网页下载函数
def get_html(self,url):
"""下载网页"""
return requests.get(url,headers=self.headers).text
我们定义了一个get_html函数,函数使用时需要传入url作为下载的网页网址。
将下载到的网页作为返回值弹出。
6.图片下载函数
我们定义一个图片下载函数,用于下载并保存图片
def get_img(self,url):
"""下载用户指定的图片"""
img = requests.get(url,headers=self.headers).content
file = 'img\\{}'.format(self.key)+url.split('/')[-1]
with open (file,'wb') as save_img:
save_img.write(img)
第一行我们定义了一个名为get_img的函数用于下载保存图片,调用时需要传入图片的url
第三行我们使用requests下载图片并保存到img变量中
第四行我们设置了文件名
第五行至第六行我们将图片保存
7.主函数
def main(self):
"""控制程序运行"""
#下载网页
html=self.get_html(self.url)
#将网页转换为etree格式
html_etree = etree.HTML(html)
#提取图片url
img_urls = html_etree.xpath('//img[@class="img-responsive lazy image_dtb"]/@data-backup')
#循环提取处图片url
for img_url in img_urls:
self.get_img(img_url)
第四行我们先下载网页
第六行我们将网页转化为etree格式
第八行我们从网页中匹配处图片url
第十行至第十一行我们循环提取出图片url并下载保存
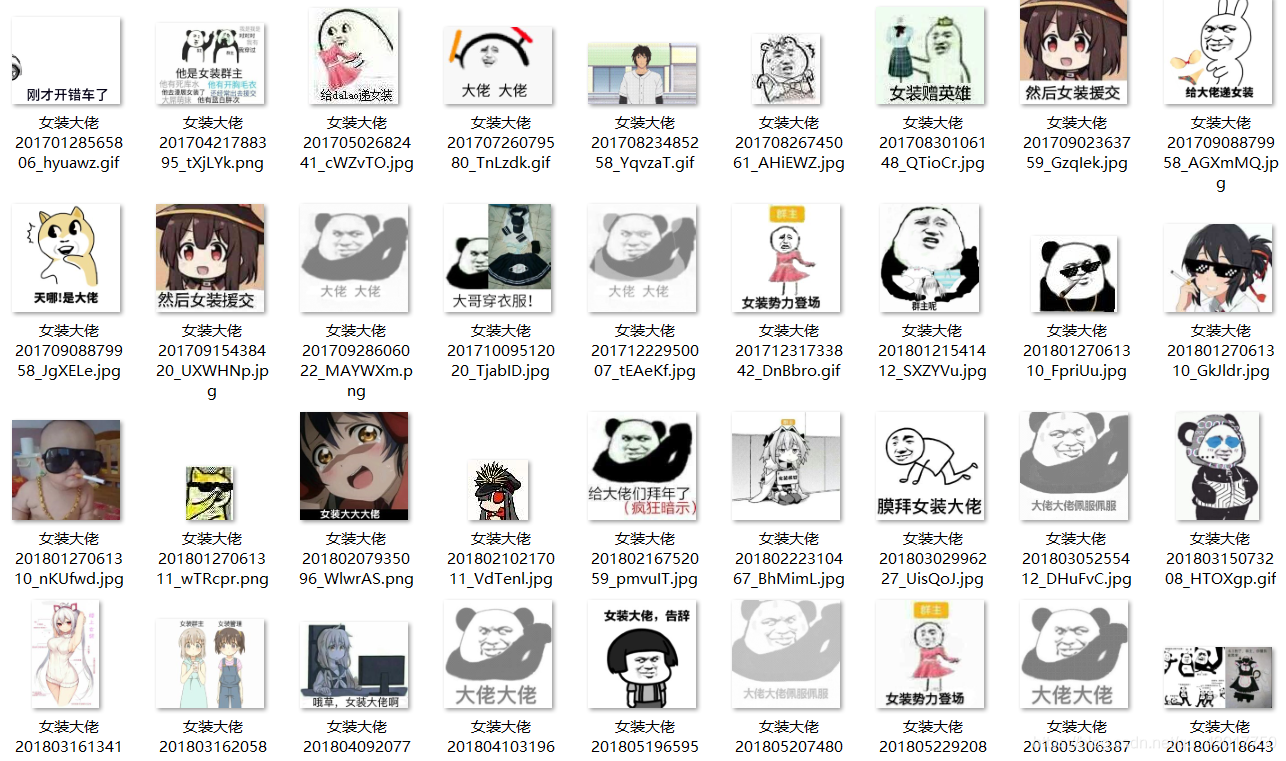
8.效果展示
完整代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年8月23日
from lxml import etree
import requests
class DouTuLa():
def __init__(self,key):
"""参数设置"""
#设置搜索的表情包关键字
self.key = key
#生成表情包搜索页面url
self.url = "http://www.doutula.com/search?keyword={}".format(key)
#设置网页请求头
self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0'}
def get_html(self,url):
"""下载网页"""
return requests.get(url,headers=self.headers).text
def get_img(self,url):
"""下载用户指定的图片"""
img = requests.get(url,headers=self.headers).content
file = 'img\\{}'.format(self.key)+url.split('/')[-1]
with open (file,'wb') as save_img:
save_img.write(img)
def main(self):
"""控制程序运行"""
#下载网页
html=self.get_html(self.url)
#将网页转换为etree格式
html_etree = etree.HTML(html)
#提取图片url
img_urls = html_etree.xpath('//img[@class="img-responsive lazy image_dtb"]/@data-backup')
#循环提取处图片url
for img_url in img_urls:
self.get_img(img_url)
doutula = DouTuLa('女装大佬')
doutula.main()
