python爬虫我是斗图之王
本文会以斗图啦网站为例,爬取所有表情包。
阅读之前需要对线程池、连接池、正则表达式稍作了解。
分析网站
页面url分析
打开斗图啦网站,简单翻阅之后发现最新表情每页包含的表情是最多的。
其url是: /photo/list/?page=2 其中page参数为页码,目前有1578页
页面图片元素分析
使用chrome的开发者工具分析一个图片的元素
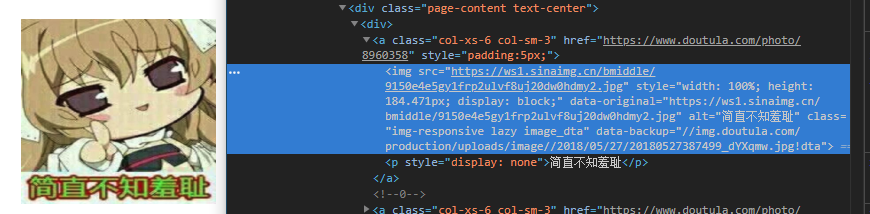
<img src="https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1frp2ulvf8uj20dw0hdmy2.jpg" style="width: 100%; height: 184.471px; display: block;" data-original="https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1frp2ulvf8uj20dw0hdmy2.jpg" alt="简直不知羞耻" class="img-responsive lazy image_dta" data-backup="//img.doutula.com/production/uploads/image//2018/05/27/20180527387499_dYXqmw.jpg!dta">可以看到img元素中包含我们想要信息:图片地址和图片描述
注意此时实际上我看到是浏览器渲染之后的页面,所以元素可能会是动态生成的。
如果我们要提高效率则应该使用web1.0,因为web2.0需要会更慢也更复杂。
要查看未渲染之前的页面,右键查看源代码搜索图片链接

<img src="//www.doutula.com/build/img/loader.gif"
style="width: 100%; height: 100%;"
data-original="https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1frp2ulvf8uj20dw0hdmy2.jpg"
alt="简直不知羞耻" class="img-responsive lazy image_dta"
data-backup="//img.doutula.com/production/uploads/image//2018/05/27/20180527387499_dYXqmw.jpg!dta">img标签的src属性并非真正的图片地址,推测网站使用了图片懒加载技术,感兴趣可以自己搜索。
虽然src不是图片地址,但发现其实data-original就是真正的图片地址。
图床分析
根据之前的分析,其实该网站使用新浪的图床ws1.sinaimg.cn,多查看几个图片地址发现不一定是ws1子域名
可能是任何ws开头,后面跟数字。为什么会这样?
根据HTTP/1.1协议规定,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制。超过限制数目的请求会被阻塞
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
来源: RFC-2616-8.1.4 Practical Considerations
而不同的浏览器有不同的限制

所以新浪图床为了优化浏览器访问图片的速度,图片地址使用了不同的子域名来绕过这种限制
测试发现,固定子域名ws1中的数字,图片也依旧可以访问,https也使用http访问
流程梳理
通过改变page参数爬取所有列表页面
/photo/list/?page=1通过正则获取img标签的
图片地址和图片描述进一步下载图片,并保存为文件
优化说明
为更快爬取页面和图片使用线程池并发请求
连接池要保证域名不能改变,所以图片链接中
ws*均替换为ws1为了得到更快的下载图片
https退回到http
代码
需要先安装requests库pip install requests
# -*- coding: utf-8 -*-
import re
import os
import requests
import multiprocessing
from multiprocessing.pool import ThreadPool
# 设置图片保存文件夹
BASE_DIR = os.path.join(os.path.dirname(__file__), 'pic')
# 创建三个队列,分别用于图片任务、页面任务、日志记录
picqueue = multiprocessing.Queue()
pagequeue = multiprocessing.Queue()
logqueue = multiprocessing.Queue()
# 创建两个线程池,分别用于图片任务,页面任务
picpool = ThreadPool(30)
pagepool = ThreadPool(3)
error = []
def getimglist(body):
imglist = re.findall(
r'data-original="https://ws\d([^"]+)"\s+alt="([^"]+)"', body)
for url, name in imglist:
if name:
#根据图片描述拼接最终的图片文件名
name = name[:180] + url[-4:]
#https->http ws*->ws1
url = "http://ws1" + url
logqueue.put(url)
picqueue.put((name, url))
def savefile():
#当前线程位置唯一的一个连接
http = requests.Session()
while True:
name, url = picqueue.get()
#判断是否已经下载
if not os.path.isfile(os.path.join(BASE_DIR, name)):
req = http.get(url)
try:
open(os.path.join(BASE_DIR, name), 'wb').write(req.content)
except:
error.append([name, url])
def getpage():
#当前线程位置唯一的一个连接
http = requests.Session()
while True:
pageid = pagequeue.get()
req = http.get(
"https://www.doutula.com/photo/list/?page={}".format(pageid))
getimglist(req.text)
def main():
if not os.path.isdir(BASE_DIR):
os.mkdir(BASE_DIR)
# 将页码放入队列中
for x in range(1, 1579):
pagequeue.put(x)
# 启动页面任务池
for x in range(3):
pagepool.apply_async(getpage)
# 启动图片任务池
for x in range(30):
picpool.apply_async(savefile)
# 打印普片任务剩余个数,页面剩余个数,以及抓取到的url连接
while True:
print(picqueue.qsize(), pagequeue.qsize(), logqueue.get())
if __name__ == '__main__':
main()结果
可以看到100M带宽基本吃满
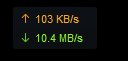
环境差异、网络波动可能会使一些图片下载失败。多执行几次即可。
最终大约可以下载到六万多张表情表。
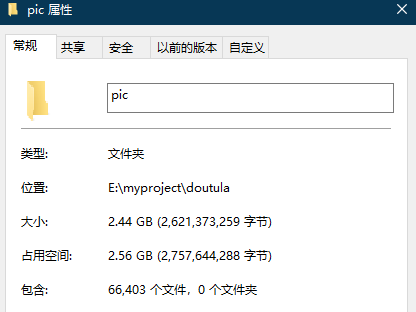
斗图
他有的图咱都有
而且可以反怼回去

想要我最后这个用大易语言写的斗图工具,赶紧来bugscan社区下载源码吧。