笔记-scrapy与twisted
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。
在任何情况下,都不要写阻塞的代码。阻塞的代码包括:
- 访问文件、数据库或者Web
- 产生新的进程并需要处理新进程的输出,如运行shell命令
- 执行系统层次操作的代码,如等待系统队列
Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。至于Twisted异步代码与多线程代码的比较可以参考一下下图:
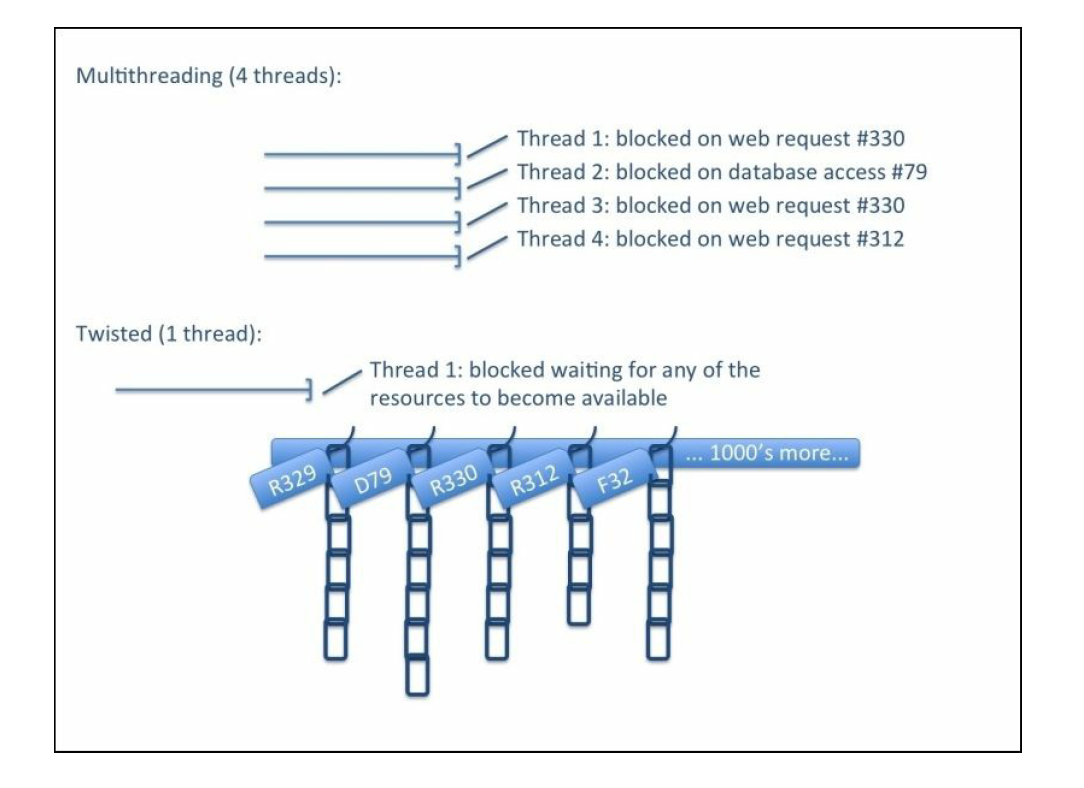
多线程的代码会有多个线程,在任何给定的时刻,不大可能所有的线程都在等待某个阻塞事件的发生。当等待的带伤发生时,线程开始工作,执行一些运算,然后可能再等待其他阻塞事件。这样服务器运行多个应用,就有很多线程,经过仔细地调整调度CPU就能很好地被利用。
而Twisted只采用一个线程,它使用了操作系统的I/O复用函数,如select()、poll()和epoll()作为”hanger”。当遇到阻塞的操作,如result = i_block()时,Twisted会提供另一种立即可以返回的实现方式。不过返回的不是具体的值而是一个钩子,如defered = i_dont_block(),这个钩子可以挂载一个函数,里面包含着当值处于可获取状态的时候我们想要执行的代码,例如deferred.addCallback(process_result)。Twisted程序就是用这些defered操作串起来的链,它的主线程叫做Twisted Event Reactor,这个线程负责监视哪些hanger上面的资源已经就位(比如服务器对爬虫的Request有响应了)。此时,它解除链最上面的defered的阻塞状态,这个defered可以会完成一些计算然后反过来又解除了另一个defered的阻塞状态。也有一些defered需要I/O操作,它就会把这个链放回hanger,并释放CPU以执行其他任务。因为只有一个线程,Twisted不会有上下文切换的负担,并且可以节省多个线程所额外需要的资源(比如内存)。换句话说,使用这种非阻塞的结构,虽然只有一个线程,所得到的性能却和数千个线程相似。
不过说句实话,操作系统的开发者们已经对线程操作优化进行了数十年,现在性能问题已经显得不如以前那么重要了。另一个问题是,多线程的编程要写出线程安全的代码非常困难。如果你已经了解了defereds/callbacks,你会发现Twisted的代码远远要比多线程的代码简单。inlineCallbacks生成器的使用甚至会使用代码更加容易。