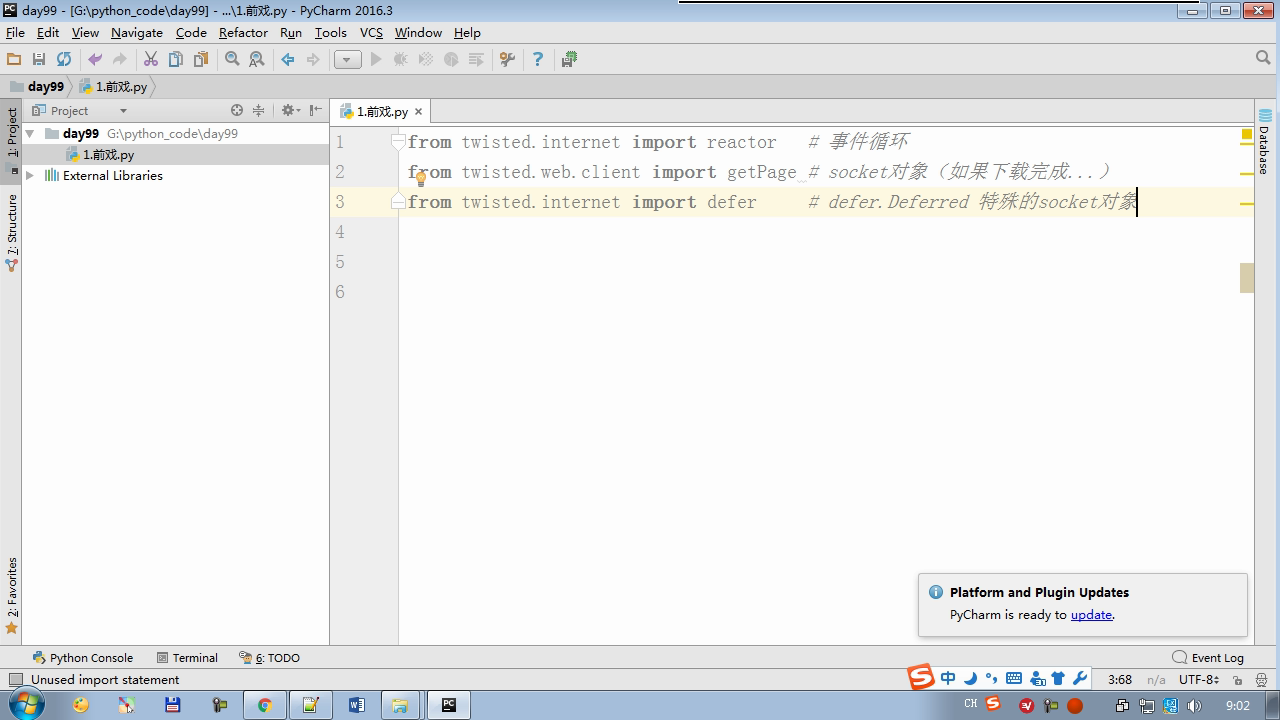
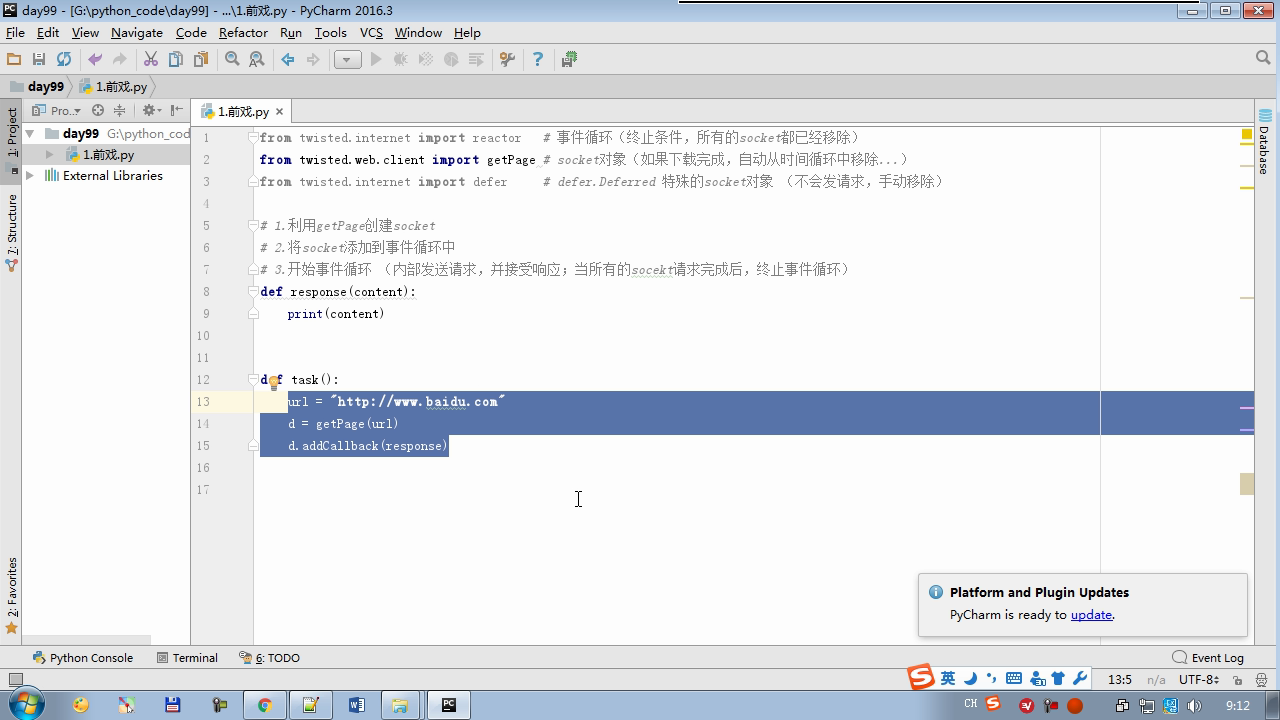
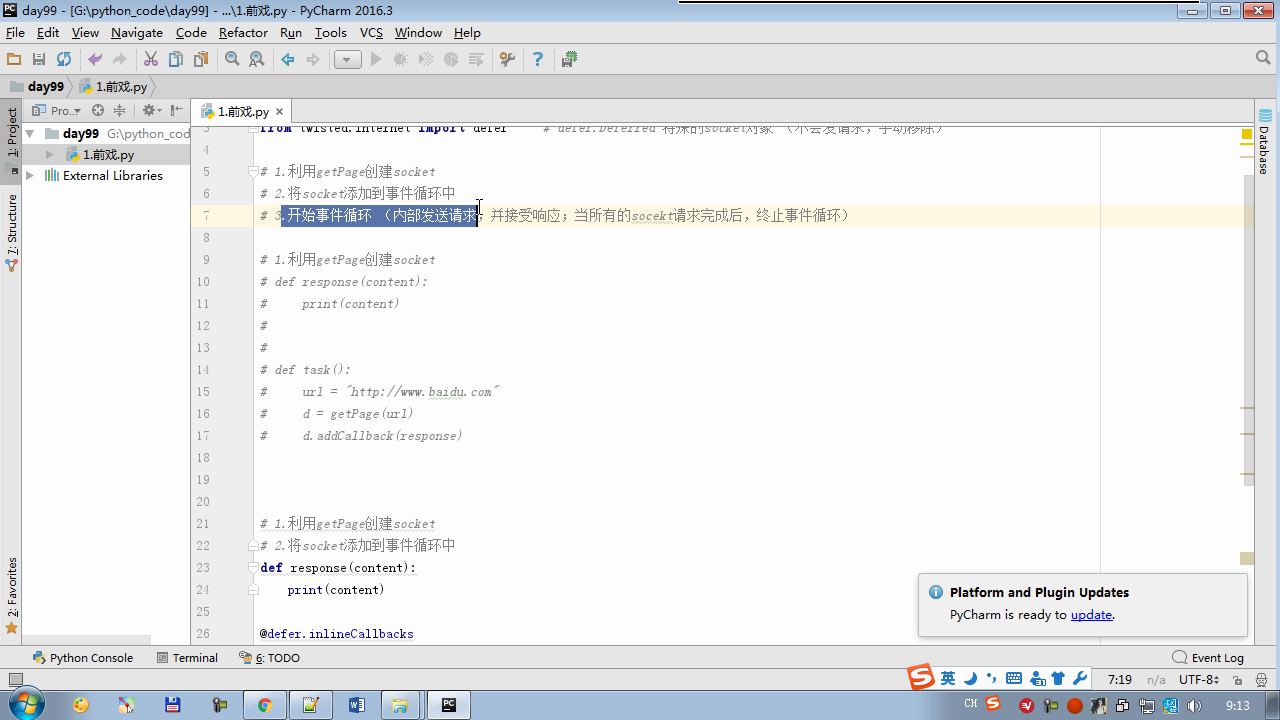
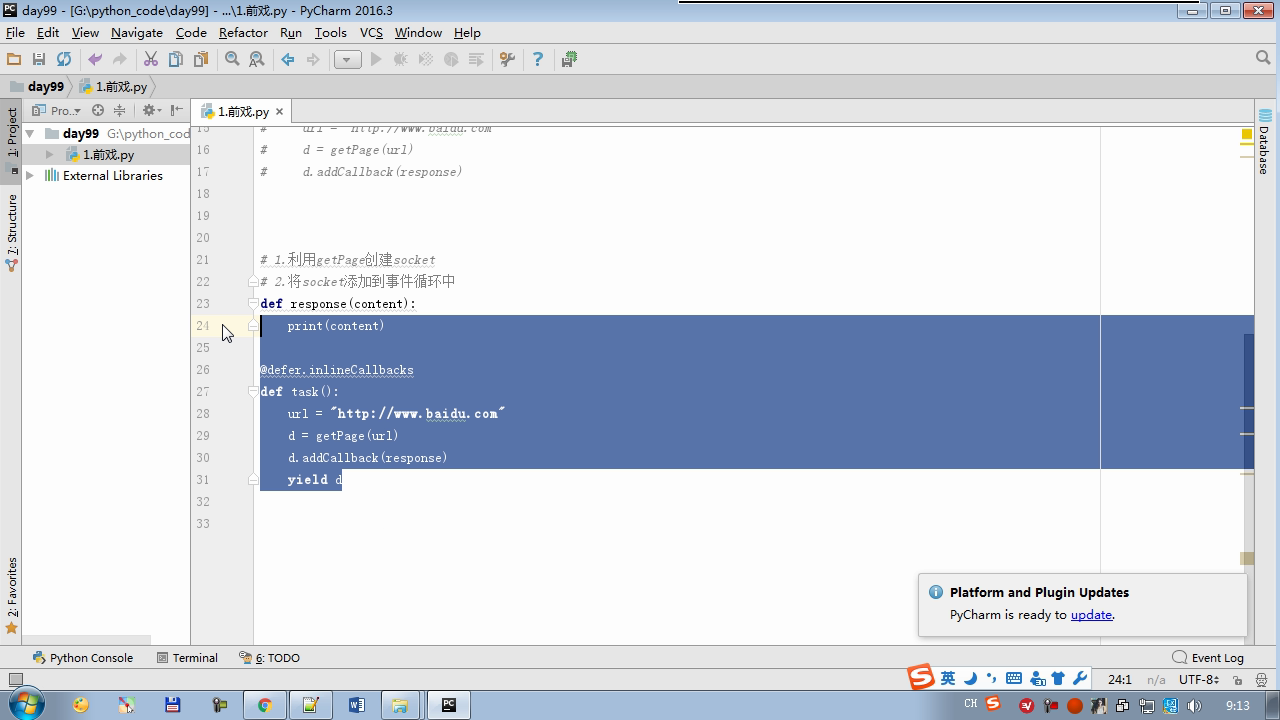
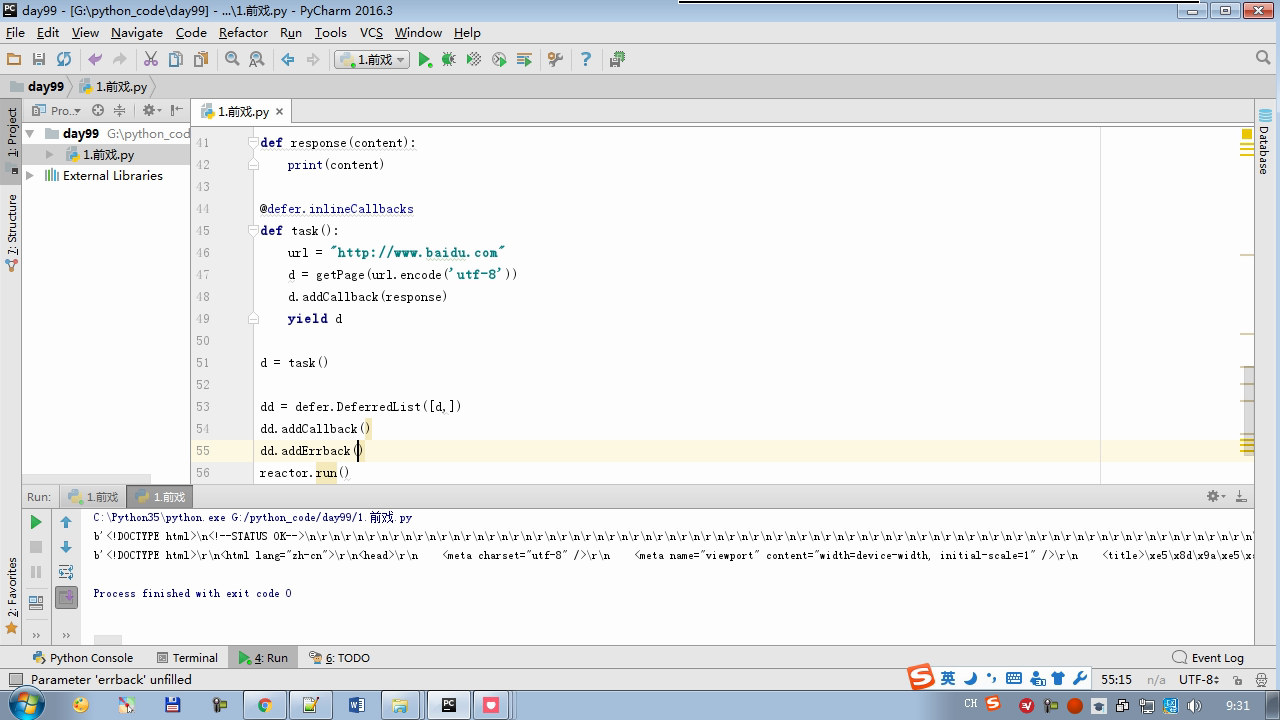
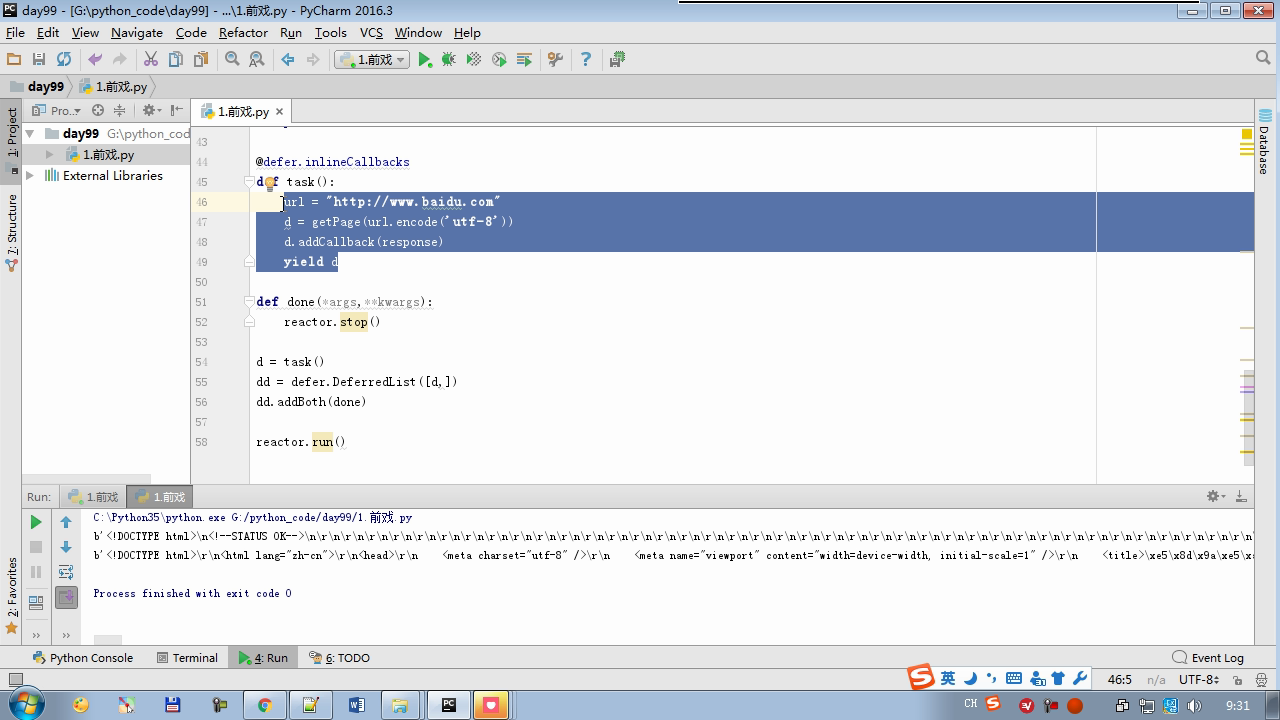
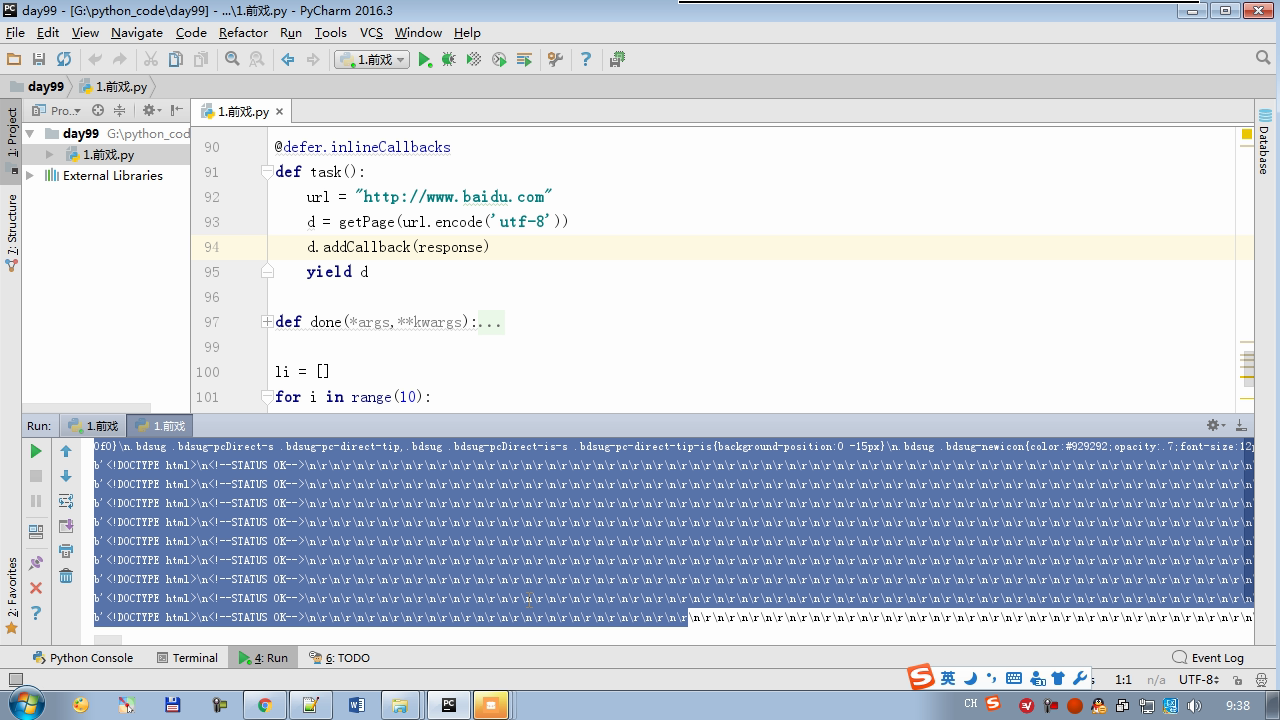
from twisted.internet import reactor # 事件循环(终止条件,所有的socket都已经移除) from twisted.web.client import getPage # socket对象(如果下载完成,自动从时间循环中移除...) from twisted.internet import defer # defer.Deferred 特殊的socket对象 (不会发请求,手动移除) # 1.利用getPage创建socket # 2.将socket添加到事件循环中 # 3.开始事件循环 (内部发送请求,并接受响应;当所有的socekt请求完成后,终止事件循环) ######################### # 1. 利用getPage创建socket # ######################### # 1.利用getPage创建socket # def response(content): # print(content) # # # def task(): # url = "http://www.baidu.com" # d = getPage(url) # d.addCallback(response) ######################### # 1.利用getPage创建socket # 2.将socket添加到事件循环中 ######################### # def response(content): # print(content) # # @defer.inlineCallbacks # def task(): # url = "http://www.baidu.com" # d = getPage(url) # d.addCallback(response) # yield d ######################### # 1.利用getPage创建socket # 2.将socket添加到事件循环中 # 3.开始事件循环(无法自动结束) ######################### # def response(content): # print(content) # @defer.inlineCallbacks # def task(): # url = "http://www.baidu.com" # d = getPage(url.encode('utf-8')) # d.addCallback(response) # yield d # # def done(*args,**kwargs): # reactor.stop() # # task() # reactor.run() ######################### # 1.利用getPage创建socket # 2.将socket添加到事件循环中 # 3.开始事件循环(自动结束) ######################### # def response(content): # print(content) # @defer.inlineCallbacks # def task(): # url = "http://www.baidu.com" # d = getPage(url.encode('utf-8')) # d.addCallback(response) # yield d # # def done(*args,**kwargs): # reactor.stop() # # d = task() # dd = defer.DeferredList([d,]) # dd.addBoth(done) # # reactor.run() ######################### # 1.利用getPage创建socket # 2.将socket添加到事件循环中 # 3.开始事件循环(自动结束) ######################### # def response(content): # print(content) # # @defer.inlineCallbacks # def task(): # url = "http://www.baidu.com" # d = getPage(url.encode('utf-8')) # d.addCallback(response) # yield d # url = "http://www.baidu.com" # d = getPage(url.encode('utf-8')) # d.addCallback(response) # yield d # # def done(*args,**kwargs): # reactor.stop() # # li = [] # for i in range(10): # d = task() # li.append(d) # dd = defer.DeferredList(li) # dd.addBoth(done) # reactor.run() ######################### # 1.利用getPage创建socket # 2.将socket添加到事件循环中 # 3.开始事件循环(自动结束) ######################### """ _close = None count = 0 def response(content): print(content) global count count += 1 if count == 3: _close.callback(None) @defer.inlineCallbacks def task(): """ 每个爬虫的开始:stats_request :return: """ url = "http://www.baidu.com" d1 = getPage(url.encode('utf-8')) d1.addCallback(response) url = "http://www.cnblogs.com" d2 = getPage(url.encode('utf-8')) d2.addCallback(response) url = "http://www.bing.com" d3 = getPage(url.encode('utf-8')) d3.addCallback(response) global _close _close = defer.Deferred() yield _close def done(*args,**kwargs): reactor.stop() # 每一个爬虫 spider1 = task() spderd2 = task() dd = defer.DeferredList([spider1,spderd2]) dd.addBoth(done) reactor.run() """