被用来检索\替换那些符合某个模式(规则)的文本,对于文本过滤或规则匹配,最强大的就是正则表达式,是python爬虫里必不可少的神兵利器。
1 正则表达式re基本规则
[0-9] 任意一个数字,等价\d
[a-z] 任意一个小写字母
[A-Z]任意一个大写字母
[^0-9] 匹配非数字,等价\D
\w 等价[a-z0-9_],字母数字下划线
\W 等价对\w取非
. 任意字符
[] 匹配内部任意字符或子表达式
[^] 对字符集合取非
* 匹配前面的字符或者子表达式0次或多次
+ 匹配前一个字符至少1次
? 匹配前一个字符0次或1次
^ 匹配字符串开头
$ 匹配字符串结束
2 python的re模块
几个重要的方法:
match: 匹配一次从开头;
search: 匹配一次,从某位置;
findall: 匹配所有;
split: 分隔;
sub: 替换;
3 正则表达式的两种模式
3.1 贪婪模式:(.*)
import re str = "hello_python3_world" re_obj = re.compile(".*_") data = re_obj.findall(str) print(data) # 贪婪模式,一直匹配到最后一个下划线_
3.2 懒惰模式:(.*?)
import re str = "hello_python3_world" re_obj1 = re.compile(".?_") #['o_', '3_'] re_obj2 = re.compile(".*?_") #['hello_', 'python3_'] data1 = re_obj1.findall(str) data2 = re_obj2.findall(str) print(data1) print(data2) # 懒惰模式,匹配到第一个下划线_时即停止继续匹配
4 相关软件
RegexTester.exe
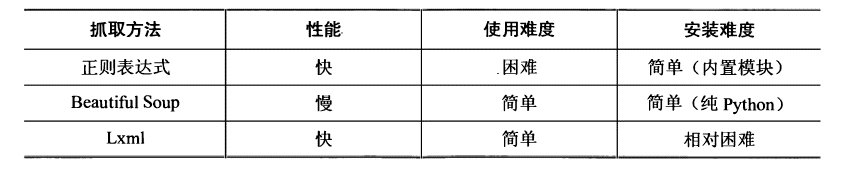
5 正则 BS lxml的比较
6 示例
5.1 示例一
用正则表达式实现下面的效果:
把 i=d%0A&from=AUTO&to=AUTO&smartresult=dict
转换成下面的形式:
i:d%0A
from:AUTO
to:AUTO
smartresult:dict
import re str = "i=d%0A&from=AUTO&to=AUTO&smartresult=dict" re_obj = re.compile("&") data = re_obj.split(str) #data数据存储['i=d%0A', 'from=AUTO', 'to=AUTO', 'smartresult=dict'] m = len(data) for i in range(m): print(data[i])