---恢复内容开始---
-
常用的正则匹配规则
-
元字符
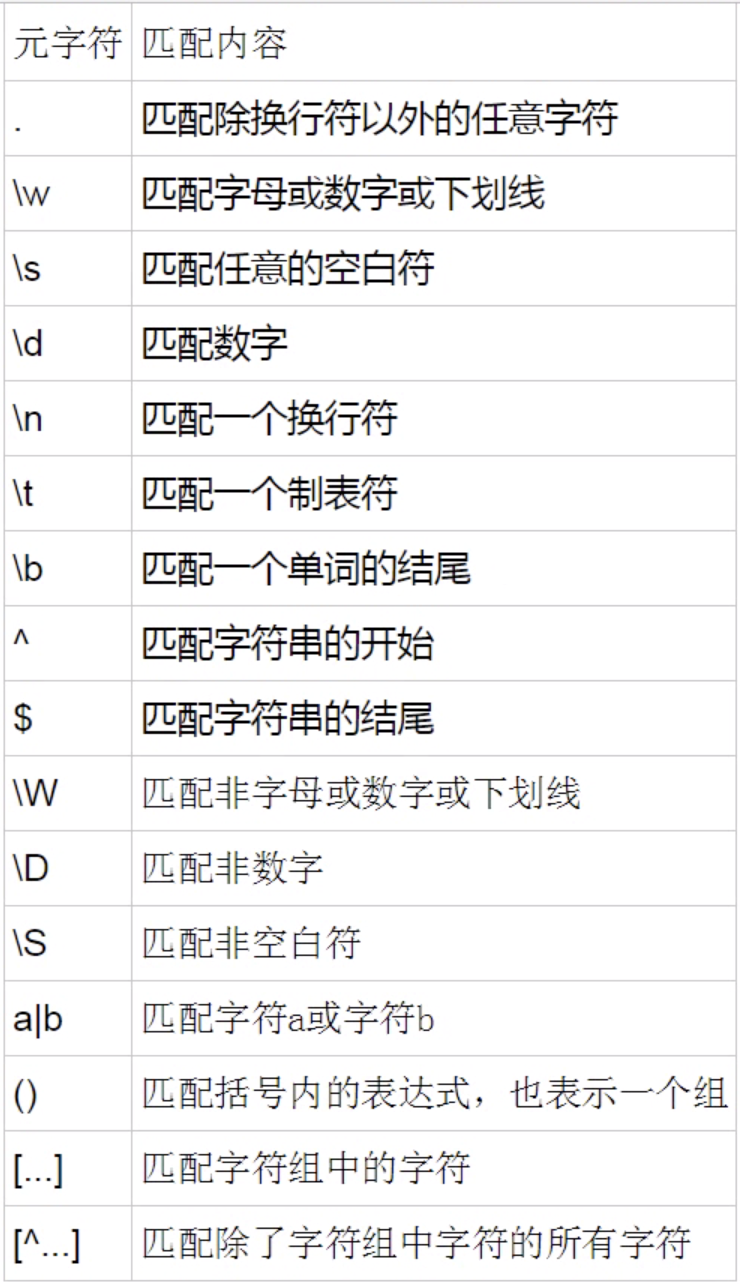
-
量词

-
字符组
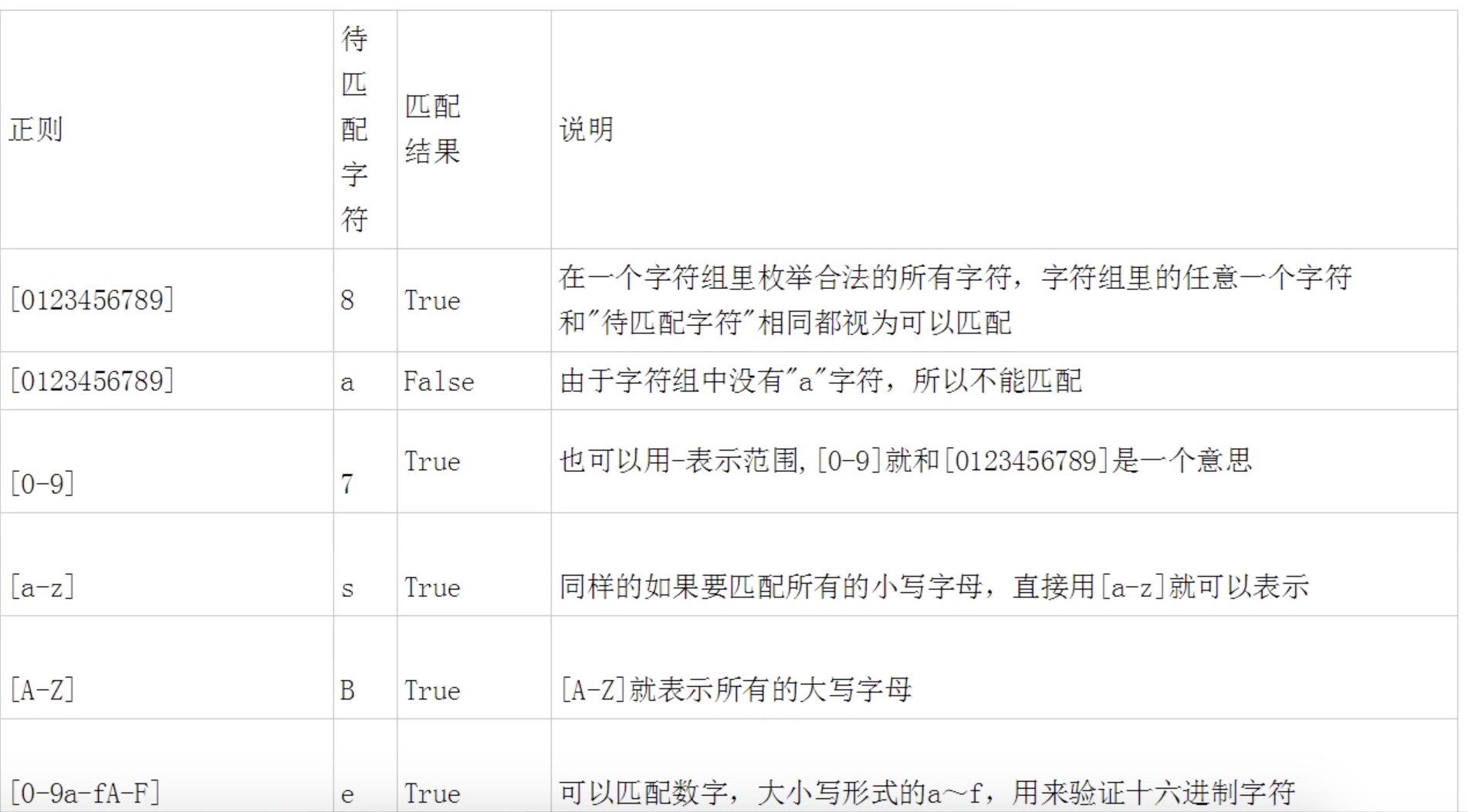
-
字符集
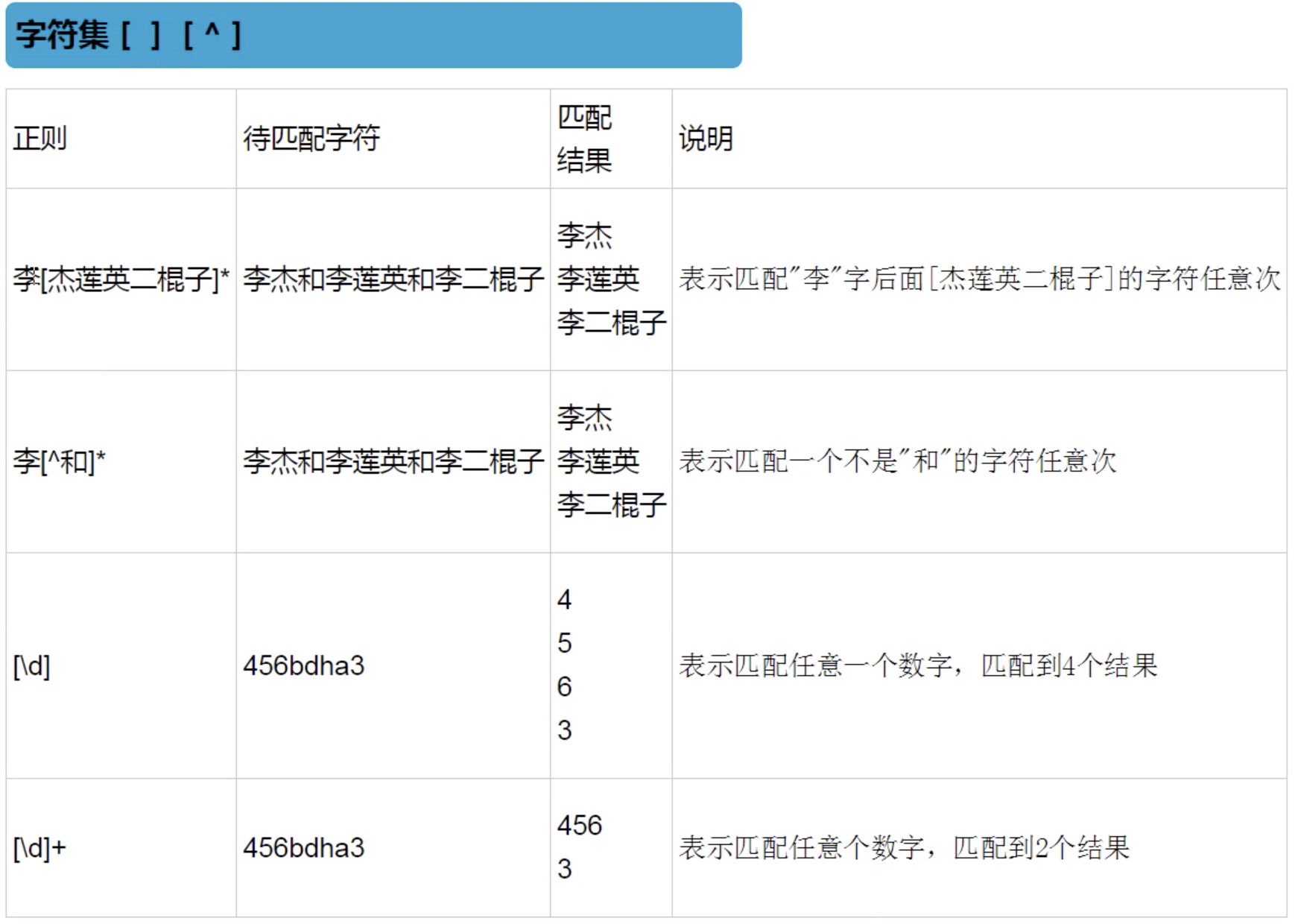
-
转义符

-
贪婪匹配

-
-
re模块使用正则表达式
-
实例引入(是否使用re模块和正则表达式的区别)
 View Code
View Code1 # 不使用正则表达式 2 phone_number = input("请输入一个11位数导入手机号码 :") 3 if len(phone_number) == 11 \ 4 and phone_number.isdigit() \ 5 and (phone_number.startswith('13') 6 or phone_number.startswith('15') 7 or phone_number.startswith('17') 8 or phone_number.startswith('18') 9 or phone_number.startswith('19')): 10 print("这个手机好码是合法的") 11 else: 12 print("这个手机号码是不合法的") 13 14 15 # 调用re模块使用正则表达式 16 import re 17 phone_number = input("请输入一个11位数导入手机号码 :") 18 if re.match('^(13|15|17|18|19)[0-9]{9}$', phone_number): # 正则规则 : ^(13|15|17|18|19)[0-9]{9}$ 19 print("这个手机好码是合法的") 20 else: 21 print("这个手机号码是不合法的")
实例中涉及到内置函数starswich()函数
View Code1 # startswith()函数 2 # string.startswith(str, beg=0,end=len(string)) 3 # 或string[beg:end].startswith(str) 4 # 1、string:被检测的字符串 2、str:指定的字符或者子字符串 3、 beg:设置字符串检测的起始位置 5 # 4、end:设置字符串检测的结束位置
-
match()
-
# match是从头开始匹配,如果正则规则开头可以匹配上,就返回一个变量。匹配的内容需要调用group才能显示。
# 如果没有找到,则返回None,调用group会报错
View Code1 import re 2 3 string = 'Hello! Regular expression, 520' 4 result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string=string) 5 6 print(len(string), result, result.group(), result.span(), sep='\n\n') 7 8 9 # 输出: 10 30 11 12 <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'> 13 14 Hello! Regular expression, 520 15 16 (0, 30) 17 18 19 # span()方法可以输出皮牌的范围
-
-
修饰符
re.I 使匹配对大小写不敏感
re.L 做本地化识别( locale-aware )匹配
re.M 多行匹配,影响^和$
re.S. 使 .匹配包括换行在内的所有字符
re.U. 根据Unicode字符集解析字符。 这个标志影响\w、\W、\b和\B
re.X. 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
例如:
View Code1 import re 2 string = 'Hello! Regular expression, 520' 3 result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string, re.S)
-
search()
# search是从前往后,寻找到一个就返回,返回的变量需要调用group才能拿到结果。如果没有找到,那么返回None,调用group回报错
View Code1 import re 2 3 string = 'Hello! Regular expression, 5201314,Learning makes me happy and addicted to learning.' 4 regular = 'Hello!\s\w*\s\w+.\s\d{3}' 5 6 ret = re.search(regular, string) 7 # 从前面往后面找到一个"Hello!\s\w*\s\w+.\s\d{3}"就返回 8 print(ret) 9 10 11 # 返回的是一个对象 : <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'>
-

---恢复内容结束---
-
常用的正则匹配规则
-
元字符
-
量词
-
字符组
-
字符集
-
转义符
-
贪婪匹配
-
-
re模块使用正则表达式
-
实例引入(是否使用re模块和正则表达式的区别)
View Code1 # 不使用正则表达式 2 phone_number = input("请输入一个11位数导入手机号码 :") 3 if len(phone_number) == 11 \ 4 and phone_number.isdigit() \ 5 and (phone_number.startswith('13') 6 or phone_number.startswith('15') 7 or phone_number.startswith('17') 8 or phone_number.startswith('18') 9 or phone_number.startswith('19')): 10 print("这个手机好码是合法的") 11 else: 12 print("这个手机号码是不合法的") 13 14 15 # 调用re模块使用正则表达式 16 import re 17 phone_number = input("请输入一个11位数导入手机号码 :") 18 if re.match('^(13|15|17|18|19)[0-9]{9}$', phone_number): # 正则规则 : ^(13|15|17|18|19)[0-9]{9}$ 19 print("这个手机好码是合法的") 20 else: 21 print("这个手机号码是不合法的")
实例中涉及到内置函数starswich()函数
View Code1 # startswith()函数 2 # string.startswith(str, beg=0,end=len(string)) 3 # 或string[beg:end].startswith(str) 4 # 1、string:被检测的字符串 2、str:指定的字符或者子字符串 3、 beg:设置字符串检测的起始位置 5 # 4、end:设置字符串检测的结束位置
-
match()
-
# match是从头开始匹配,如果正则规则开头可以匹配上,就返回一个变量。匹配的内容需要调用group才能显示。
# 如果没有找到,则返回None,调用group会报错
View Code1 import re 2 3 string = 'Hello! Regular expression, 520' 4 result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string=string) 5 6 print(len(string), result, result.group(), result.span(), sep='\n\n') 7 8 9 # 输出: 10 30 11 12 <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'> 13 14 Hello! Regular expression, 520 15 16 (0, 30) 17 18 19 # span()方法可以输出皮牌的范围
-
-
修饰符
re.I 使匹配对大小写不敏感
re.L 做本地化识别( locale-aware )匹配
re.M 多行匹配,影响^和$
re.S. 使 .匹配包括换行在内的所有字符
re.U. 根据Unicode字符集解析字符。 这个标志影响\w、\W、\b和\B
re.X. 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
例如:
View Code1 import re 2 string = 'Hello! Regular expression, 520' 3 result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string, re.S)
-
search()
# search是从前往后,寻找到一个就返回,返回的变量需要调用group才能拿到结果。如果没有找到,那么返回None,调用group回报错
View Code1 import re 2 3 string = 'Hello! Regular expression, 5201314,Learning makes me happy and addicted to learning.' 4 regular = 'Hello!\s\w*\s\w+.\s\d{3}' 5 6 ret = re.search(regular, string) 7 # 从前面往后面找到一个"Hello!\s\w*\s\w+.\s\d{3}"就返回 8 print(ret) 9 10 11 # 返回的是一个对象 : <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'>
-
findall()
# 想要获取匹配正则表达式的所有内容,借助findall()方法,该方法会搜索整个字符串
View Code1 ret = re.findall('[a-z]+', 'eva egon yuan') 2 # 返回所有满足匹配条件的结果,放在列表里 3 print(ret) 4 # 输出:['eva', 'egon', 'yuan']
-
sub()
# sub()方法修改文本
View Code1 ret = re.sub('\d', '马冬梅', '马什么梅? 0 马什么冬? 0 冬什么梅? 0', 3) 2 # 将数字替换成'马冬梅',其中3代表替换了3次 3 print(ret) 4 # 输出: 5 马什么梅? 马冬梅 马什么冬? 马冬梅 冬什么梅? 马冬梅
-
subn()
# subn()方法和sub()方法很相似
View Code1 import re 2 3 ret = re.subn('\d', '马冬梅', '马什么梅? 0 马什么冬? 0 冬什么梅? 0') 4 # 将数字替换成'马冬梅',返回元组(替换的结果,替换了多少次) 5 print(ret) 6 # 输出: 7 ('马什么梅? 马冬梅 马什么冬? 马冬梅 冬什么梅? 马冬梅', 3)
-
compile()
# 将正则字符串编译成一个正则表达式对象
View Code1 import re 2 3 obj = re.compile('\d{3}') 4 # 将正则表达式编译成一个正则表达式对象,这里正则规则是要匹配三个数字 5 ret = obj.search('abc123cba') 6 # 正则表达式对象调用search,参数为待匹配的字符串 7 print(ret.group()) 8 # 输出结果 : 123
-
finditer()
# 返回一个存放匹配结果的迭代器
View Code1 import re 2 3 ret = re.finditer('\d', 'ab2cd4567efg') # finditer返回一个存放匹配结果的迭代器 4 print(ret) 5 print(next(ret).group()) # 查看第一个结果 6 print(next(ret).group()) # 查看第二个结果 7 print(i.group() for i in ret) # 查看剩余的所有结果 8 9 # 上一条print已经输出了所有的结果,所以这个for循环不输出任何字符 10 for i in ret: 11 print(i.group()) 12 13 14 15 # 输出: 16 <callable_iterator object at 0x10a077cf8> 17 2 18 4 19 <generator object <genexpr> at 0x1142f5f48> 20 5 21 6 22 7
-
举例理解正则、re
优先级别(?:)1 ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') 2 print(ret) # # ['oldboy'] 这是因为findall会优先匹配结果组内容返回,如果想要匹配结果,取消权限即可 3 4 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') 5 print(ret) # # ['www.oldboy.com'] 取消优先级别的权限
(保留项)1 ret = re.split('\d+', 'eva3egon4yuan') 2 print(ret) # 结果 : ['eva', 'egon', 'yuan'] 3 4 ret = re.split('(\d+)', 'eva3egon4yuan') 5 print(ret) # 结果 : ['eva', '3', 'egon', '4', 'yuan'] 6 7 # 在匹配部分加上()之后,切出的结果是不同的, 8 # 没有()的没有保留匹配的项,但是有()却能够保留匹配的项 9 # 这个在某些需要保留匹配部分的使用过程是非常重要的
?P给分组起名1 ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<hi>hello</hi>") 2 # 还可以利用?P<name>的形式给分组起个名字 3 # 获取匹配的结果可以直接用group('名字')拿到对应的值 4 print(ret.group('tag_name')) # 结果 : hi 5 print(ret.group()) # 结果 : <hi>hello</hi>
组序号1 ret = re.search("<(\w+)>\w+</\1>", "<hi>hello</hi>") 2 # 如果不给组起名字也可以用\序号来找到对应的组,表示要找的内容要和前面组的内容一致 3 # 获取匹配的结果可以用group(序号)拿到对应的值 4 print(ret.group(1)) 5 print(ret.group())
正则在线测试网址:http://tool.chinaz.com/regex/
-
-
抓取猫眼电影
View Code1 from urllib import request 2 import re 3 4 for i in range(27736): 5 url = 'https://maoyan.com/films?showType=3&offset={0:}'.format(i * 30) 6 response = request.urlopen(url=url) 7 html = response.read().decode('utf-8') 8 result = re.search('<dd>.*?title="(.*?)">.*?{movieId:(.*?)}">.*?(\d\.).*?(\d)</i></div>', html, re.S) 9 dictionaries = { 10 'Movie Item Title': result.group(1), 11 'Movie ID': int(result.group(2)), 12 'Movie Score': float(result.group(3) + result.group(4)) 13 } 14 print(dictionaries)
有时候会报错,待完善