什么是正则表达式:
一种匹配字符串的规则
正则表达式能做什么:
-
可以制定一个规则:
-
来确认某一个字符串是否符合规则
-
从大段的字符串中找到符合规则的内容
-
程序领域 :
-
登录注册页的表单验证
-
爬虫
-
自动化开发: 日志分析
正则表达式的语法:
-
元字符
-
字符组[ ] ,在一个字符的位置上能出现的内容
-
量词
-
特殊的用法和现象
-
?的使用:在量词的后面跟了一个?号,取消贪婪匹配, 即惰性机制
字符:
| 元字符 | 匹配内容 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a | b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| […] | 匹配字符组中的字符 |
| [^…] | 匹配除了字符组中字符的所有字符 |
量词:
| 量词 | 用法说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
图形记忆 ? * + 所表示的含义:
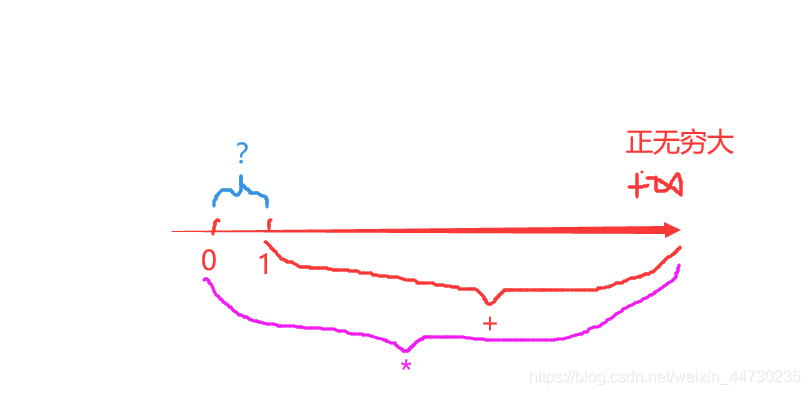
. ^ $
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有“海.”的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
几个常用的非贪婪匹配pattern
- *? 重复任意次,但尽可能少重复
- +? 重复1次或更多次,但尽可能少重复
- ?? 重复0次或1次,但尽可能少重复
- {n,m}? 重复n到m次,但尽可能少重复
- {n,}? 重复n次以上,但尽可能少重复
re模块下的常用方法:
-
匹配方法
-
findall 匹配所有的项,返回列表
-
search 如果有返回值,返回一个对象,没有返回值,返回none ,返回的对象通过group来获取匹配到的第一个结果
-
match
-
替换
-
sub 返回替换后的结果
-
subn 返回元组(替换掉结果,替换了多少次)
-
切割
-
split
-
进阶方法:
-
compile 将正则表达式编译成一个正则表达式对象,
-
finditer 返回一个存放匹配结果的迭代器
实例:
#findall方法
import re
ret = re.findall('\d','hello123python456')
print(ret)

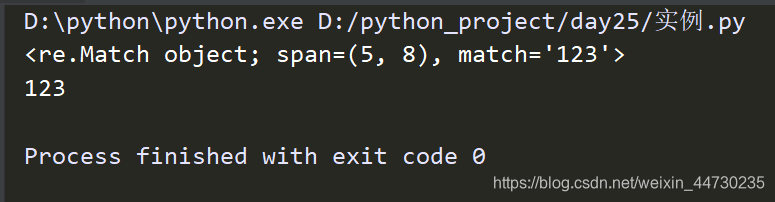
#search
ret = re.search('\d','hello123python456')
print(ret) #返回一个对象
print(ret.group()) 返回第一个匹配的结果
#split
ret = re.split('\d+','alex40taibai35codegod21')
print(ret) #返回以数字切割后的列表

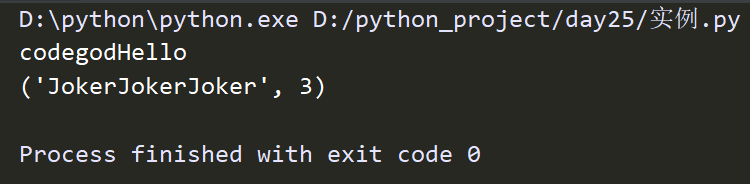
#sub,subn 替换的方法区别
ret = re.sub('\d','H','codegod1ello')
print(ret)
ret2 = re.subn('\d+','Joke','123')
print(ret2) #返回一个元组,(替换后的值,替换几次)
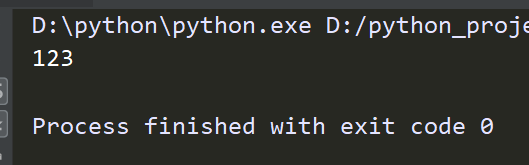
#compile
obj = re.compile('\d{3}')
ret = obj.search('abc123eeee')
print(ret.group())
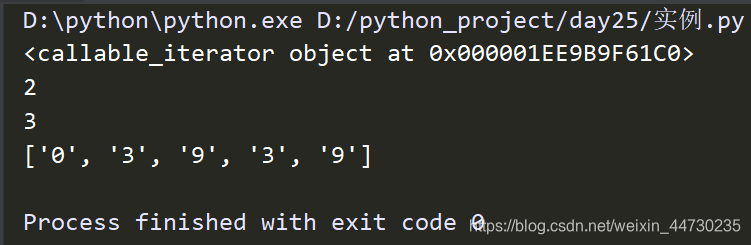
ret = re.finditer('\d','sf230f3f9r39')
print(ret) #返回<callable_iterator object at 0x00000206653E6130>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
- findall的优先级查询
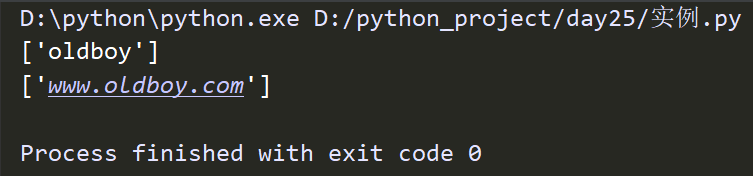
import re
ret = re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(tet) #返回['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret
 2. split的优先级查询
2. split的优先级查询
ret = re.split("\d+","eva3egon4yuan")
print(ret)
ret2 = re.split("(\d+)",'eva3egon4yuan')
print(ret2)
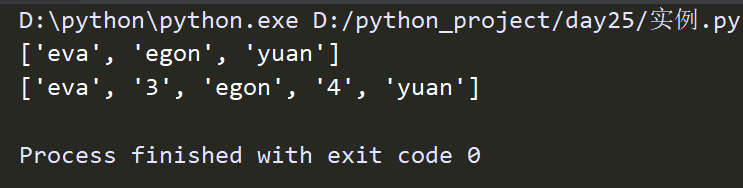
在正则匹配部分加上()之后所切出的结果是不同的,没有()的没有保留所匹配的项,但是有()后却能够保留了匹配的项。
