承接上篇:Some Papers about BERT in Text Classifition, Data Augmentation and Document Ranking(一)
详述BERT fine-tune 中文分类实战及预测
BERT fine-tune 终极实践教程

SIGIR 2019 CEDR: Contextualized Embeddings for Document Ranking

BERT等预训练模型除了在自然语言处理中直接应用外,它们还可以应用于任何和文本表示相关联的领域任务中。神经排序模型借助深度神经网络的表示能力来增强项表示(term representation),从而提升排序模型的性能。因此,随着表示能力更好的预训练模型的出现,将预训练模型整合到现有的排序模型中来提升模型效果成为了一种自然而然的想法。本文作者探索了ELMO和BERT与排序模型的结合,提出了一种联合的排序方法CEDR(Contextualized Embeddings for Document Ranking),并在TREC数据集上取得了SOTA。
假设查询为 ,文档为 ,那么排序模型可以表示为一个函数 来估计两者之间的相关性。神经排序模型通常会得到一个相似度矩阵 ,矩阵中的元素表示查询项和文档项中项的表示向量之间的余弦相似度。
CEDR将预训练模型所有层表示整合到现有的排序模型中,此时相似度矩阵就转换成了三维形式 ,其中 表示层数,那么 表示 层第 个token的上下文表示向量。因此,相似度矩阵可定义为:
然后将 的表示和模型本身的输入进行拼接进行后续的相关性估计。
实验结果如下,CEDR在Robust04和webTrack2012-14两个数据集上效果都很好。

How to Fine-Tune BERT for Text Classifition?

本文是复旦大学CCL获奖文章,它对于BERT在Text Classification任务上如何进行fine-tune提供了许多有价值的结论。本文所涉及的内容主要有以下四个方面:
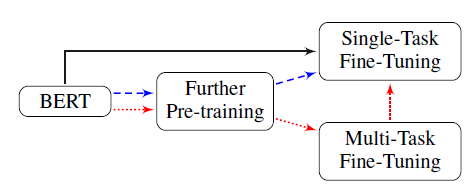
- 进一步在闭域(In-domain)或跨域(Cross-domain)数据中对BERT进行预训练
- 采用多任务学习(multi task learning)的方式对BERT进行fine-tune
- 在目标任务上对BERT进行fine-tune
- 研究BERT在长文本任务上hidden layer表示的选择,学习率的选择,如何结果BERT的灾难性遗忘和少样本问题等
- ……
经过很多的实验,本文所得出的结论有:
-
针对于长文本的截断来说,当输入长度限定为最大512时,采取first128 + tail 382的拼接方式效果更好。

[其中的数字表示测试集上的错误率] -
BERT进行fine-tune后,选择最后一层的表示进行分类效果最好。

-
初始学习率为2e-5且逐层递减学习率最有利于缓解BERT的灾难性遗忘问题。

-
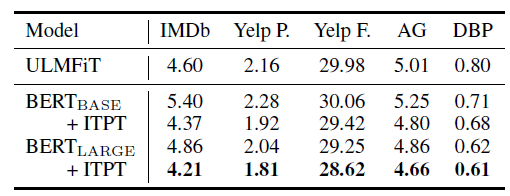
进一步的pre-train可以帮助提升BERT在分类任务上的性能,同时训练100K效果最优。

-
BERT在相似域的数据上进行进一步的pre-train效果最好。

-
基于BERT的模型分类效果均优于之前的模型。

-
为了得到更好的分类效果,BERT可以在使用多任务学习进行fine-tune后在对应的数据上再多训练一会。
-
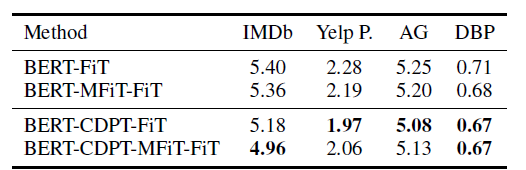
BERT 只需要少量的样本进行fine-tune便可以取得不错的效果。特别是在BERT经过进一步的pre-train后,只需要0.4%的训练数据便可以提升模型的效果

-
进一步的pre-train对于BERT的base版本和large版本同样适用。