XPath—XML Path Language
1、安装 lxml库
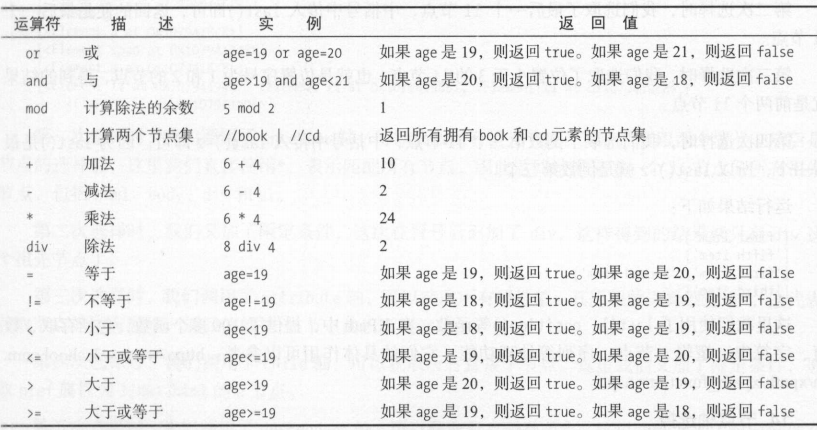
2、XPath常用规则

3、XPath解析页面
from lxml import etree
text = '''
<div>
<ul>
<li calss='item-1'><a href='link1.html'> first item </a></li>
<li calss='item-2'><a href='link2.html'> second item
</ul>
</div>
'''
## 调用HTML类进行初始化,构造一个XPath对象
## etree可以自动修正html文本
html = etree.HTML(text)
## tostring()输出修正后的HTML代码,结果是bytes类型
result = etree.tostring(html)
print(result.decode('utf-8'))
## 读取文本文件进行解析
html = etree.parse('./test.html', etree.HTMLParser())
## *匹配所有节点 , 列表形式, 所有节点都是Element对象
result = html.xpath('//*')
print(result)
4、//* 获取所有节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## *匹配所有节点 , 列表形式, 所有节点都是Element对象
result = html.xpath('//*')
print(result)
## 获取所有li节点
result1 = html.xpath('//li')
print(result1) # [<Element li at 0x34eca08>, <Element li at 0x34ec530>]
print(result1[0]) # 获取第一个li节点
5、/ 子节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 获取 li节点的所有a子节点
result2 = html.xpath('//li/a')
print(result2)
6、.. 父节点
@ 属性
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 获取父节点 .. ## 获取属性 href 为"link2.html"的a节点的父亲节点的class属性值 result3 = html.xpath('//a[@href="link2.html"]/../@class') print(result3) ## ['item-2']
7、text() 文本获取
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## text() 获取节点中的文本 result4 = html.xpath('//li[@class="item-1"]//text()') print(result4) result5 = html.xpath('//li[@class="item-1"]/a/text()') print(result5)
8、contains() 属性多指匹配
from lxml import etree
## li节点class属性有多个值
text = '''
<li class="li li-first"><a href="link-html">first item</a></li>
'''
html = etree.HTML(text)
## 属性多值匹配 contains(@class, "li")
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result)
9、多属性匹配
from lxml import etree
## li节点有多个属性
text = '''
<li class="li li-first" name="item"><a href="link-html">first item</a></li>
'''
html = etree.HTML(text)
## 多属性匹配 and
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)
10、按序选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 按序选择
## 序号以1开头 选取第一个li节点
result1 = html.xpath('//li[1]/a/text()')
print(result1) # [' first item ']
## 选取最后一个li节点
result2 = html.xpath('//li[last()]/a/text()')
print(result2) # [' sixth item']
## 选取位置小于3的li节点
result3 = html.xpath('//li[position()<3]/a/text()')
print(result3) # [' first item ', ' second item']
## 选取倒数第三个li节点
result4 = html.xpath('//li[last()-2]/a/text()')
print(result4) # [' forth item']
11、节点轴选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 节点轴选择
## ancestor::* 获取所有的祖先节点
result1 = html.xpath('//li[1]/ancestor::*')
print(result1)
## ancestor::div 获取祖先节点 div
result2 = html.xpath('//li[1]/ancestor::div')
print(result2)
## attribute::* 获取第一个li节点所有的属性值
result3 = html.xpath('//li[1]/attribute::*')
print(result3)
## child::* 获取第一个li节点所有的孩子节点
result4 = html.xpath('//li[1]/child::*')
print(result4)
## descendant::* 获取第一个li节点所有的子孙节点
result5 = html.xpath('//li[1]/descendant::*')
print(result5)
## following::* 获取第一个li节点之后的所有节点
result6 = html.xpath('//li[1]/following::*')
print(result6)
## following-sibling::* 获取第一个li节点之后的所有同级节点
result6 = html.xpath('//li[1]/following-sibling::*')
print(result6)