一.XPath简介
对网页的层级关系进行解析,XPath的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。
另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,
几乎所有的定位节点,都可以用XPath进行选择。
官网: https://www.w3.org/TR/xpath
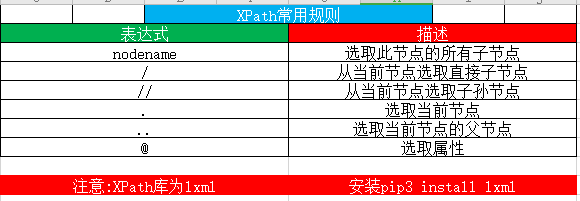
1.XPath常用规则:
二.基本的使用
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #将网页整体补为网页结构,打开文件路径 #html = etree.parse('demo.html',etree.HTMLParser()) print(html) #将网页转换为文本类型,为bytes result = etree.tostring(html) #转化为str类型 result = result.decode("utf-8") print(result)
1.匹配选择(所有节点)
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 result = html.xpath('//*') print(result)

2.子节点
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 result = html.xpath('//li/a') print(result)
这里"/"代表的是直接的子节点,"//"代表是所有的子孙节点

3.父节点
父节点:使用"..",也可以使用parent::代表父级
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 #属性为link4的a标签的父级的class属性 result = html.xpath('//a[@href="link4"]/../@class') #@表示属性 result1 = html.xpath('//a[@href="link4"]/parent::*/@class') print(result) print(result1)

4.文本获取
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 #属性为link4的a标签的父级的class属性 result = html.xpath('//a[@href="link4"]/text()') print(result)

5.属性多值匹配
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two"><a href="link2">2</a></li> <li class="three two"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 #contains(@属性,值) result = html.xpath('//li[contains(@class,"three")]/a/text()') print(result)
6.多属性匹配
多个属性确定一个节点,这时就需要匹配多个属性
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two three" name="item"><a href="link2">2</a></li> <li class="three two"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 #contains(@属性,值) result = html.xpath('//li[contains(@class,"three") and @name="item"]/a/text()') print(result)
7.按序选择
from lxml import etree text = ''' <div> <ul> <li class="one"><a href="link1">1</a></li> <li class="two three" name="item"><a href="link2">2</a></li> <li class="three two"><a href="link3">3</a></li> <li class="four"><a href="link4">4</a></li> <li class="five"><a href="link5">5</a> </ul> </div> ''' #将文本转换为网页类型,并修复补全 html = etree.HTML(text) #选择内容匹配 #匹配第一个li result1 = html.xpath('//li[1]/a/text()') #最后一个倒数2 result2 = html.xpath('//li[last()-2]/a/text()') #最后一个 result3 = html.xpath('//li[last()]/a/text()') #小于3 result4 = html.xpath('//li[position()<3]/a/text()') #内置函数100,http://www.w3school.com.cn/xpath/xpath_functions.asp print(result1) print(result2) print(result3) print(result4)

8.节点轴选择
#属性为link4的a标签的父级的class属性