介绍:
人脸检测中速度和精度的平衡很难做到。虽然像cascaded cnn\MTCNN人脸检测精度和速度上已经都很快了,但是这两个网络结构都有以下问题存在:
1、推理时间随着图像中人脸个数的增加而增加;
简要说明:级联的CNN用来做人脸检测,往往是第一个CNN用来产生候选的区域,然后再将候选区域送入后续的CNN中。那么图像中人脸个数的增加,候选区域的个数也就增加,这样势必会导致后续CNN推理时间的增加。人脸个数少的场景影响不大(比如自拍),但是如果涉及到人脸个数多的场景(比如机场车站等环境下),模型的推理时间可能会大幅增加。
2、虽然单个模型是优化的,但是级联后却并不能保证模型的最优;
3、对于VGA分辨率的图像(这里应该指的是640*480)的图像,前向推理FPS只有14,还不足够达到实时。
本篇论文主要贡献如下:
1、设计了Rapidly Digested Convolutional Layers;
2、引入了Mutiple Scale Convolutional Layers;
3、为了提高小脸的召回率,提出了新的anchor densification strategy;
4、在I5 CPU上测试速度为38ms。
主要内容:
网络结构如下所示:

Anchor densification strategy:
Inception的anchor尺度为32*32,64*64,128*128,Conv3_2、Conv4_2的尺度分别为256*256和512*512。

anchor的间隔和相应的层的stride相等。比如Conv3_2的stride是64、anchor大小为256*256,表示对应输入图片每64像素大小有一个256*256的anchor。anchor密度为:
Adensity = Ascale/Ainterval
Ascale 表示anchor的尺度,Ainterval 表示anchor间隔。默认间隔分别设置为32,32,32,64.根据公式,对应的密度分别为1,2,4,4,4.显然在不同尺度上anchor的密度不均衡。相比大的anchor(128-512),小的anchor(32和64)过于稀疏,将会导致在小脸检测中低的召回率。
为解决不均衡问题,此处提出新的anchor策略。为了加大一种anchor的密度,在一个感受野的中心均匀的堆叠n2 个anchor(本来是1个)用来预测。
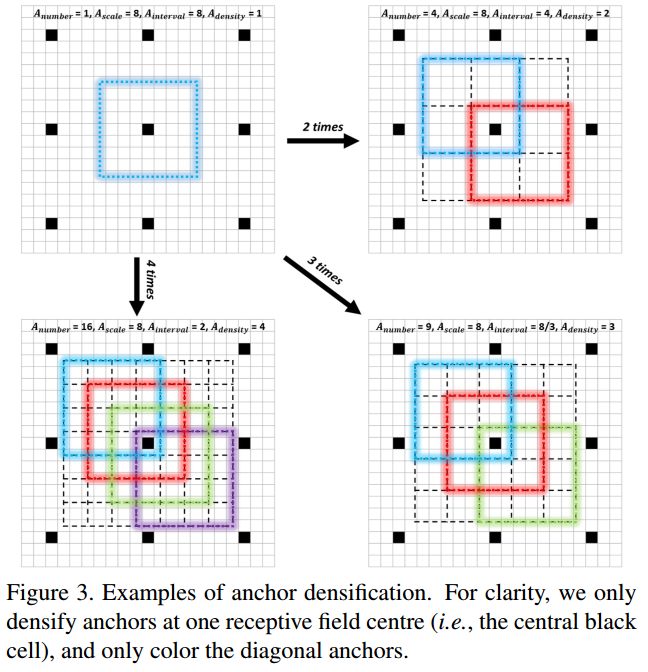
文章里对32*32的anchor做了4倍,对64*64的anchor做了2倍,这样就可以保证不同尺度的anchor有相同的密度。
本论文的启发点:
1、对于物体检测中的小目标也可以借鉴本文中的anchor densification straytegy来提高小目标的召回率;
2、在对于某些速度要求较高的场合下,可以借鉴本文中的CRELU部署在前两三个Convolution上,加快推理速度,不用修改代码即可完成部署。

如上图所示:将Batchnorm后取反,然后concat起来,接上SCALE和Relu即可。比如采用power layer就可以完成取反的工作。具体的prototxt如下所示:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
convolution_param {
num_output: 24
pad: 3
kernel_size: 7
stride: 4
bias_term: false
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "conv1_bn"
type: "BatchNorm"
bottom: "conv1"
top: "conv1"
batch_norm_param {
use_global_stats: false
}
}
layer {
name: "conv1_neg"
type: "Power"
bottom: "conv1"
top: "conv1_neg"
power_param {
power: 1
scale: -1.0
shift: 0
}
}
layer {
name: "conv1_concat"
type: "Concat"
bottom: "conv1"
bottom: "conv1_neg"
top: "conv1_concat"
}
layer {
name: "conv1_scale"
type: "Scale"
bottom: "conv1_concat"
top: "conv1_concat"
scale_param {
bias_term: true
}
}
layer {
name: "conv1_relu"
type: "ReLU"
bottom: "conv1_concat"
top: "conv1_concat"
}
3、纸上得来终觉浅,绝知此事要躬行。当认识到一个算法的缺点和适用范围才算真正理解它。
