本文首发于我的微信公众号:月小水长
原文地址:https://mp.weixin.qq.com/s/uehzjUl8QEaQHtCx4o4BXg
百度翻译爬虫
程序跑起来的效果是这样的,
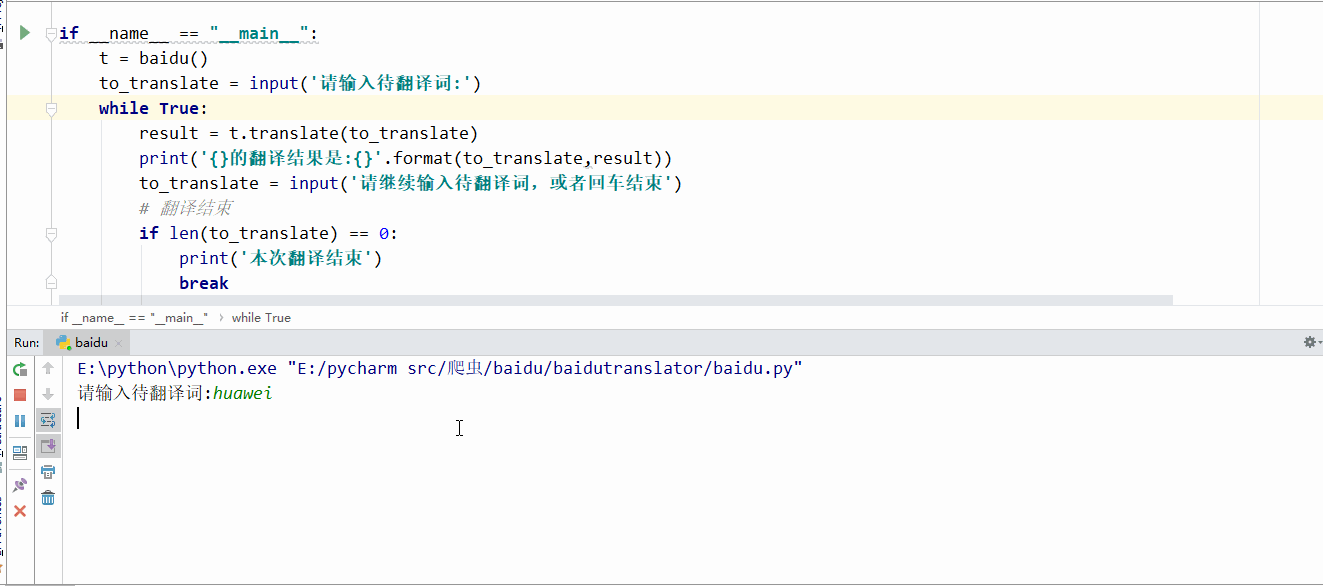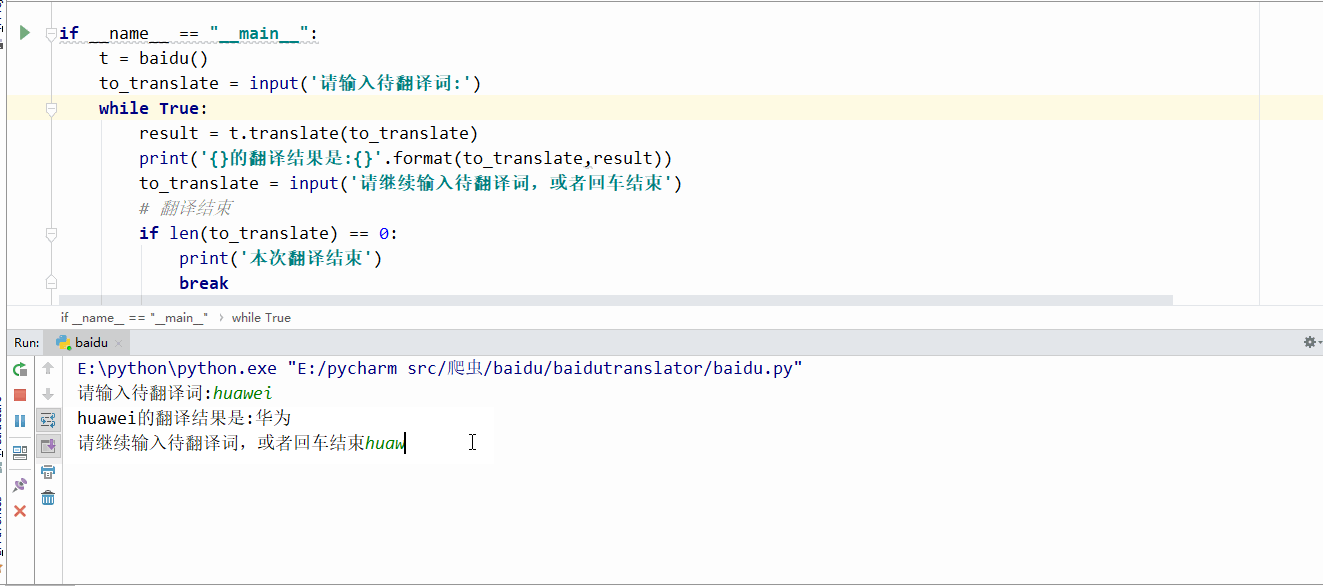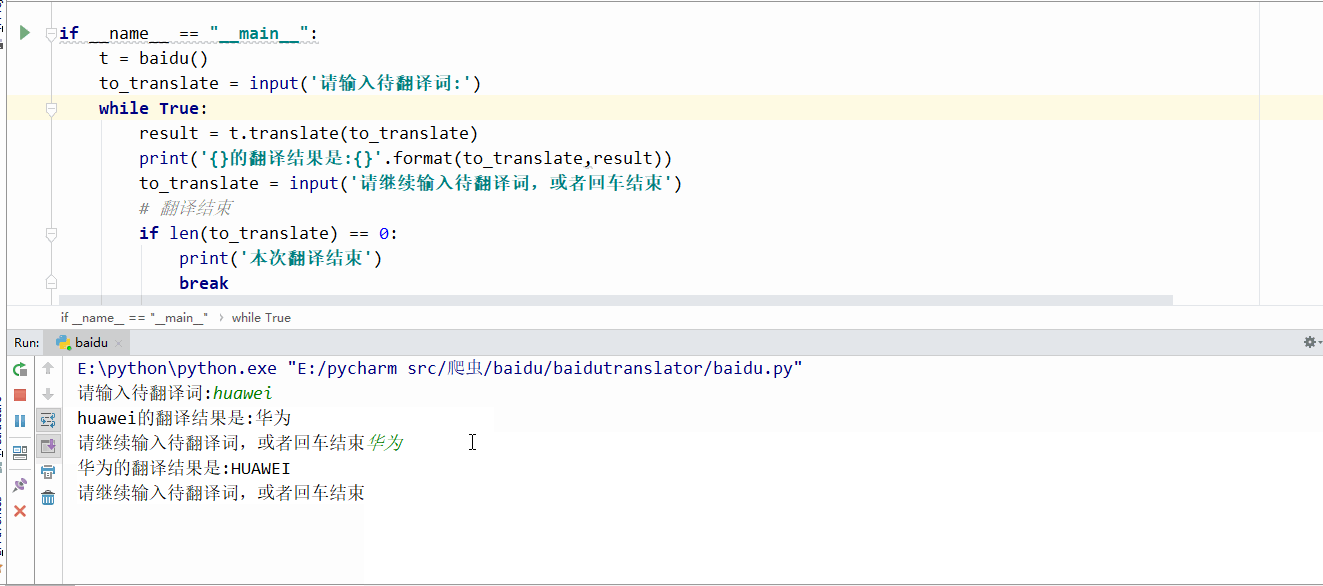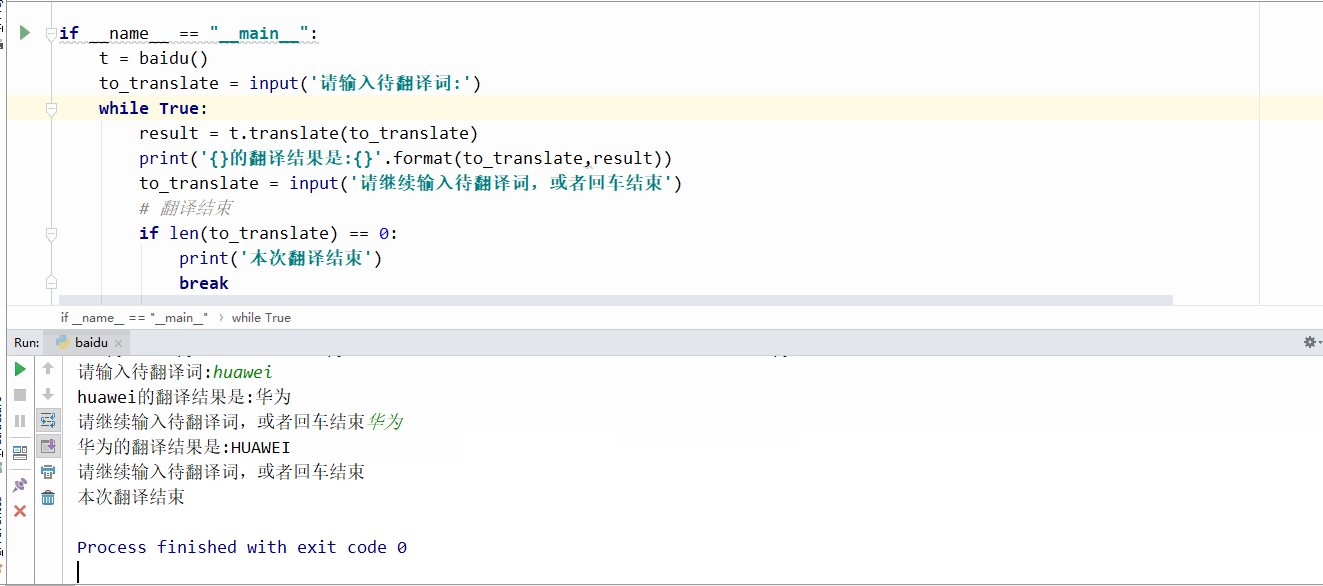
自动翻译,而且支持中英文互译
在调试代码的过程中,我发现百度翻译的加密参数和谷歌翻译差不多,我以前也写过一篇有关谷歌翻译的文章,感兴趣的同学可以看看:
更让我大跌眼镜的是,不仅如此,百度翻译的加密函数也是抄袭谷歌翻译的。。。
不展开说了,今天主要借破解百度翻译的两个参数:签名 sign 和 通证 token, 来谈谈爬虫编码的一般思路。
假如我们要想爬取百度翻译,第一步当然是打开百度翻译的网页,按F12打开开发人员工具。

切换到NetWork标签下,选择查看的返回文件类型为All,
先清除之前的痕迹,方法是点击红色圆点右边第一个图标。
然后点击蓝色的翻译按钮,这时候,就可以看到有许多响应了

有个搜索按钮(用小红色矩形框出来的),输入搜索特定的响应文件

同时我们注意到还有一个类似放大镜的图标,它也是一个搜索按钮:

点击这个搜索按钮,输入关键词,它搜索的是所有相应文件里的Response

搜索translate关键词,我们可以看到有一条搜索结果

点击这条结果

可以看到,浏览器帮我们定位到这个关键词所在的响应文件了,它是v2transapi
更多响应信息可以看右边的Response或者Preview标签页,
其实这个我们搜的这个关键词就是网页中显示的我们输入的翻译的翻译结果
不行你可以多信几次,这里要注意的一点是最好不要输中文关键词,因为响应文件中中文是\\u4f8b\\u53e5\\u5e93这样的Unicode字符存在的,显示的浏览器肯定做了转化解析,不知道为什么开发者工具没有做转化,可能google以后会改进吧,至少到2018//11/28Chrome还没有。
然后切换到Headers标签页

看请求的网址是什么,需要哪些参数,如果有些变化的参数不知道怎么构造,可以以这个参数作为关键词再搜响应文件。
最后就是编码了,上面的准备工作做得这么好,还怕什么编码呢?
Data只需要添加:
query,
simple_means_flag,
sign,
token
即可。
其中simple_means_flag为固定量,query代表待翻译的词,接下来需要解决的就是破解sign和token这两个参数。先说token吧,token可以直接在百度翻译主页的源码里找到:
但是貌似因为时间戳不同步所以直接请求百度翻译的主页获取到的token是用不了的,所以
self.session = requests.Session()
# Chrome : 设置-->高级-->内容设置-->cookie-->查看所有cookie和网站数据-->baidu.com的cookie
self.session.cookies.set('BAIDUID', '19288887A223954909730262637D1DEB:FG=1;'
self.session.cookies.set('PSTM', '%d;' % int(time.time()))
接下来再说说sign,sign是由一段js代码产生的,如下图所示(index_9b62d56.js中):
在python中用execjs执行这段js代码即可获得我们所需要的sign值,计算sign值的过程中需要用到一个名为gtk的变量的值,直接请求百度翻译的主页即可获取该值:
于是我们就可以愉快地写代码实现百度翻译的内容爬取功能了。具体操作看代码吧,破解过程也挺复杂的。
所有代码地址:https://github.com/Python3Spiders/BaiduSpider/tree/master/baidu_translation
百度贴吧爬虫
百度贴吧爬虫
程序跑起来的效果如下,
可以下载指定贴吧的图片,首先将下主要的技术思路。
由于我们要请求多个页面,而且浏览图片必须要登陆后,一种笨拙的方法是先登陆百度账号,获取 cookies ,访问其他页面获取图片链接时在 headers 中携带这些 cookies,但是这样无疑添加了代码量,其实 requests 库帮我们封装好了一个 seesion 对象,requests 库的 session 会话对象可以跨请求保持某些参数,一旦使用 session 成功地登录了某个网站,再次使用该 session 对象请求该网站的其他网页都会默认使用该 session 之前使用的 cookies 等参数。
而 session 的 api 也很简单,几乎和 requests 一模一样。比如它的 post 方法。
session.post(url=url, data=ldata, headers=headers)
再说说这个百度账号登陆接口的破解,其实破解流程和上面百度翻译类似,不再赘述,说说它的各个参数的含义吧。
data = {
'username': USER_NAME,
'password': PASSWORD,
'tpl': 'tb',
'u': 'https://tieba.baidu.com/index.html?traceid=#',
'staticpage': 'https://passport.baidu.com/static/passpc-account/html/v3Jump.html',
'isPhone': 'false',
'charset': 'utf-8',
'callback': 'parent.bd__pcbs__3rjsif'
}
username 和 password 自然不必说,账号和密码,其中密码在 Chrome 上调试发现 ‘password’ 是加密的,一直没有找到加密的算法,后来直接尝试不加密 post,居然成功了,估计这个加密只是防止在 Chrome 中直接看到密码,post 的时候接口后台会自动加密的。
tpl:tb 表明我们是从贴(t)吧(b)登录百度账号的,如果是从百度账号中心,则是 pp(passport)。
callback:是接口 post 成功的回调。
两件事
第一件事,是有关本公众号的运营,我正式开始运营这个公众号的时间是今年初,一直坚持做原创分享,经常有粉丝后台留言催更和帮我举报抄袭者,这点由衷地感动,目前也有上千个粉丝了,达到了开通流量主的门槛,说直白点,就是可以赚钱了,只要你动动手指,点击文章中的 ad, 但是我承诺,会以各种形式返还给亲爱的粉丝们,比如在交流群发红包,定期送书,我也不靠这点钱发家致富,我还是个在校学生,主要是想结识一群志同道合的朋友。回复 ” 社群 ”即可加入群聊。同时,欢迎将本公众号推荐给您身边的朋友,在此谢过了。
第二件事,我最近在创建了一个开源组织,Python3Spiders,主要是一些原创爬虫,和在爬取数据上的数据分析项目集合,全部开源,欢迎小伙伴们一起加入这个组织,可以 star,也可以成为这个组织的开发者和贡献者(在 issue s上提交留下你的足迹即可)。组织地址: https://github.com/Python3Spiders