A Style-Based Generator Architecture for Generative Adversarial Networks
一个基于样式的用于生成对抗网络的生成器架构
这是一个很重要的关于GAN的文章,StyleGAN模型可以说在这方面是最好的,尤其是在隐空间控制中。该模型使用称为自适应实例归一化(AdaIN)的神经风格转移机制来控制隐空间向量z,而不像之前的其他方式。映射网络和AdaIN训练分布在整个生成器模型中的的组合使得自己很难实现,但它仍然值得阅读,它包含了许多有趣的想法。
· 发表时间: 2018年底2019年初
· 会议: CVPR 2019
· 引用量: 16(截至20190421)
· 机构 :NVIDIA
· 作者 :Tero Karras, Samuli Laine, Timo Aila
· 论文 :https://arxiv.org/abs/1812.04948
· 代码 :https://github.com/NVlabs/stylegan
摘要
我们借鉴风格迁移文献,提出了一种新的生成对抗网络的生成结构。新的架构实现了自动学习和无监督地分离高级属性(例如,训练时的人脸姿势和身份)和生成图像中的随机变化(例如雀斑、头发),并实现对生成图像中特定尺度的属性的控制。新的生成器改进了传统分布质量度量方面的最新技术,显然拥有了更好的插值特性,也更好地分离了变化的潜在因素。为了量化插值质量和分离,我们提出了两种新的适用于任何生成器结构的自动化方法。最后,我们介绍了一个新的、高度多样化和高质量的人脸数据集。
1.介绍
通过生成方法产生的图像的分辨率和质量,特别是生成对抗网络(generative departarial networks,GAN)[21],最近得到了迅速的改进[28,41,4]。然而,这些生成器仍然像黑匣子一样工作,尽管最近作出了努力[2],但对图像合成过程的各个方面,例如随机特征的起源,仍然缺乏了解。隐空间的性质也很难理解,通常证明的隐空间插值[12,48,34]没有提供量化的方法来比较不同的生成器。
在风格迁移文献[26]的启发下,我们重新设计生成器架构,以产生控制图像合成过程的新方法。我们的生成器从一个可学习的常量输入开始,隐码在每个卷积层调整图像的“样式”,从而直接控制不同尺度下图像特征的强度。结合直接输入到网络中的噪声,这种体系结构的变化导致从生成图像的随机变化(例如,雀斑、头发)中自动、无监督地分离高级属性(例如,姿态、身份),并使直观的尺度混合和插值操作变得直观。我们不以任何方式修改判别器或损失函数,因此我们的工作与正在进行的有关GAN损失函数、正则化和超参数的讨论是相关的[23,41,4,37,40,33]。
我们的生成器将输入的隐码嵌入到一个中间隐空间中,这对网络中变量的表示方式有着深刻的影响。输入的隐空间必须遵循训练数据的概率密度,我们认为这会在某种程度上导致不可避免的纠缠。我们中间的隐空间不受这种限制,因此可以被解耦。由于之前估计隐空间分离程度的方法在我们的案例中不直接适用,我们提出了两个新的自动度量--感知路径长度和线性可分性--来量化生成器的这些方面。使用这些度量,我们表明与传统的生成器架构相比,新的生成器允许更线性、更解耦地表示不同的变化因素。
最后,我们提出了一种新的人脸数据集(Flickr-Faces-HQ,FFHQ),它有更高的质量,并且覆盖了比现有的高分辨率数据集(附录A)更大的变化。我们已经公开了这个数据集,以及我们的源代码和预训练网络。可在同一链接下找到随附的视频。
2.基于样式的生成器结构
传统的生成器上,隐码通过输入层(即前馈网络的第一层)提供给生成器(图1a)。我们抛弃了这种设计,将一个可学习的常数作为生成器的初始输入(图1b,右)。给定输入隐空间z中的隐码Z,非线性映射网络f:Z→W首先产生w∈W(图1b,左)。

图1.虽然传统的生成器[28]仅通过输入层馈送隐码,但我们首先将输入映射到中间隐空间W,然后在每个卷积层通过自适应实例归一化(AdaIN)来控制生成器。高斯噪声在每次卷积后,在计算前加上非线性。这里“A”表示学习的仿射变换,“B”将每个通道的学习比例因子应用于噪声输入。映射网络f由8层组成,合成网络g由18层组成,每个分辨率2层(42-10242)。最后一层的输出使用单独的1×1卷积转换为RGB,类似于Karras等人[28]。我们的生成器总共有26.2M的可培训参数,而传统生成器只有23.1M。

比较我们的风格迁移方法,我们计算空间不变的样式y从向量w,而不是一个例子图像。我们选择重用这个词“style” y ,因为类似的网络体系结构已经用于前馈方式转移[26], 无监督图像-图像转换[27]和域混合物[22]。与更一般的特征变换[35,53]相比,AdaIN由于其高效和紧凑的表示方式特别适合于我们的目的。
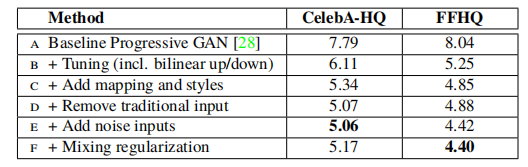
表1.不同生成器设计的Fréchet inception distance(FID)在本文中,我们使用50000图像从训练集随机抽取来计算FIDs,并将在训练集上填塞的最低距离报告给训练。
最后,通过引入显式噪声输入,我们为生成器提供了一种生成随机细节的直接方法。噪声是由高斯噪声组成的单通道图像,将一个噪声图像提供给合成网络的一个特征图。噪声图像使用每个特征的学习比例因子广播到所有特征映射,然后添加到相应卷积的输出中,如图1b所示。添加噪声输入的含义在第3.2节和第3.3节中讨论。
2.1生成器生成图像的质量
在研究生成器的特性之前,我们通过实验证明,重新设计不会影响图像质量,但实际上会大大改善图像质量。表1显示了在CelebA-HQ [28]我们新的FFHQ数据集(Appendix A)上各种生成器架构的Fréchet inception distances(FID)。其他数据集的结果见附录。我们的基线配置(A)是Karras等人的渐进GAN设置。[28],我们从中继承网络和所有超参数,除非另有说明。我们首先使用双线性上/下采样操作[58],更长的训练和调整超参数,切换到改进的基线(B)。关于训练设置和超参数的详细说明包含在附录中。然后我们通过添加映射网络和AdaIN操作(C)进一步改进了这个新基线,并且令人惊讶地发现,网络不再受益于将隐码馈送到第一卷积层。因此,我们通过移除传统的输入层并从学习的4×4×512常数张量(D)开始图像合成来简化体系结构。我们发现,尽管合成网络仅通过控制AdaIN操作的样式来接收输入,但它能够相当显著的产生有意义的结果。
最后,我们介绍了噪声输入(E),进一步改善了结果,以及新的混合正则化(F)去相关的相邻样式,并使更细粒度控制生成的图像(第3.1节)。

图2.由我们的基于样式的生成器(配置F)使用FFHQ数据集生成的未分级图像集。在这里,我们使用截断技巧的一个变体[38,4,31],对于分辨率42-322,Ψ=0.7,有关更多结果,请参见随附的视频。
我们用两种不同的损失函数来评估我们的方法:对于CelebA-HQ,我们依赖WGAN-GP[23],而FFHQ使用WGAN-GP配置A和用R1正则化[40、47、13]的非饱和损失[21]用于配置B-F。我们发现这些选择能够给出最佳结果。我们的改进不会改变损失函数。
我们观察到基于样式的生成器(E)比传统生成器(B)显著改进了FIDs,几乎提高了20%,证实了并行工作中进行的大规模ImageNet测量[5,4]。图2显示了使用我们的生成器从FFHQ数据集生成的一组未分级的新图像。经FIDs证实,其平均质量较高,甚至成功合成了眼镜、帽子等配饰。对于此图,我们使用所谓的截断技巧[38,4,31]避免了从W的极端区域进行采样-附录B详细说明了如何在W而不是Z中执行该技巧。请注意,我们的生成器只允许选择性地将截断应用于低分辨率,以便不影响高分辨率细节。
本文中的所有FIDs都是在不使用截断技巧的情况下计算的,我们仅将其用于图2和视频中的说明目的。所有图像均以10242分辨率生成。
2.2 现有技术
关于GAN架构的许多工作集中在通过例如使用多个判别器[17、43、10]、多分辨率判别器[55、51]或自我注意[57]来改进判别器。生成器侧的工作主要集中在输入隐空间[4]中的精确分布,或通过高斯混合模型[3],聚类[44],或激励凸性[48]来确定输入隐空间。
最近的条件生成器通过单独的嵌入网络将类标识符馈送到生成器中的大量层[42],而潜在的仍然通过输入层提供。一些作者已经考虑将部分隐码馈送到多个生成器层[8,4]。同时Chen等人[5]“自我调节”生成器使用AdaINs,类似于我们的工作,但不考虑中间的隐空间或噪声输入。
