摘要
本文提出“基于能量的生成对抗网络”模型(EBGAN),它将判别器视为能量函数,将低能量赋予数据所在流形附近的区域,将高能量赋予其他区域。类似于概率GAN的思想,能量GAN的生成器用于训练产生具有最小能量的对比样本,而判别器被训练为将高能量分配给这些产生的样本。将判别看作能量函数,除了具有逻辑输出的通常的二元分类器以外,还可以使用各种各样的网络结构和损失函数。其中,作者使用自动编码器实现了EBGAN框架的一个实例,将重构误差视为样本能量,而不是使用二元分类器。作者表明,这种形式的EBGAN在训练期间表现出比常规GAN更稳定的行为。本文还证实了可以通过训练单一尺度的网络架构来生成高分辨率的图像。
1、引言
1.1 基于能量的模型
基于能量的模型的本质(LeCun等,2006)是建立一个函数,将输入空间的每个点映射到一个标量,这就是所谓的“能量”。能量模型的学习是一个数据驱动的过程,它能够将低能量分配给正确的数据集,而将高能量分配给不正确的数据集。监督学习的能量模型可以归纳于这个框架:对于训练集中的每个 ,当 是正确的标签时,对 的能量取低值,反之对能量取高值。类似地,当在无监督的学习环境中单独建模 时,高密度流形上的数据被赋予较低的能量。术语“对比样本”(contrastive sample)用来指代导致能量上升的数据点,如监督学习中的不正确的 和来自无监督学习中低数据密度区域的点。
1.2 生成对抗网络
生成对抗网络(Goodfellow等,2014)导致了图像生成(Denton等,2015;Radford等,2015;Im等人,2016;Salimans等,2016),视频预测(Mathieu等,2015) 和其他一些领域的重要改进。GAN的基本思想是同时训练一个判别器和一个生成器。 判别器的训练目标是将由生成器产生的样本与来自真实数据集的样本区分开来。生成器使用来自易于采样的随机源作为输入,并被训练产生判别器不能从真实数据样本中区分出的假样本。在训练期间,生成器接收判别器相对于假样本输出的梯度。在GAN的原始形式中(Goodfellow等,2014),判别器产生概率,并在与生成器产生的分布匹配时发生收敛。从博弈论的角度来看,当生成器和判别器达到纳什均衡时,GAN便会收敛。
1.3 基于能量的生成对抗网络
本文建议把判别器看作是一个没有明确的概率解释的能量函数(或对比函数)。由判别器计算的能量函数可被看作是生成器的可训练成本函数。判别器被训练为将低能量值分配给高数据密度的区域,并在这些区域之外分配更高的能量值。相反地,发生器可以被看作是可训练的参数化函数,其在判别器分配低能量的空间区域中产生样本。虽然通常可以通过吉布斯分布将能量转换成概率(LeCun等,2006), 这种缺乏归一化的方式使得基于能量的生成对抗网络在训练过程的选择方面提供了更大的灵活性。
GAN的原始公式中的二分类概率判别器可以被看作是定义对比函数和损失函数的一种方式,如LeCun等人(2006) 对于监督和弱监督的设置,和Ranzato等人(2007) 用于无监督学习。本文通过实验证明了这个概念,在判别器是自动编码器架构的情况下,能量就是重构误差。附录B提供了EBGAN解释的更多细节(附录未翻译)。
本文的主要贡献总结如下:
(1)基于能量的生成对抗网络的训练公式。
(2)证明在简单的hinge loss下,当系统达到收敛时,EBGAN的生成器生成与给定数据同分布的样本。
(3)一种使用自动编码器作为判别器的EBGAN架构,其中能量是重建误差。
(4)一系列系统性的实验来探索对EBGAN和概率GAN产生良好结果的超参数和架构选择。EBGAN框架无需使用多尺度方法,可从256位像素分辨率的ImageNet数据集中生成看起来合理的高分辨率图像。
2、EBGAN模型
设 是产生数据集的分布的概率密度。生成器 被训练成从已知分布 (例如 )采样的随机向量 中去产生样本 ,例如图像。判别器 获取原始样本或生成的图像,并相应地估计能量值 。为了简单起见,此处假设 产生非负值,但是只要能量值是有界的,本文的分析就可以进行。
2.1 目标函数
判别器的输出经过一个目标函数,以便形成能量函数,将低能量分配给真实的数据样本,将更高的能量分配给所生成的(“假”)样本。 在这项工作中,作者使用了边距损失,但是其他许多选择也是可以解释的(LeCun 等,2006)。类似于对概率GAN所做的工作(Goodfellow等,2014),作者使用了两种不同的损失,一种是用于训练 ,另一种是训练 ,以便在生成器远离收敛时获得更好的质量梯度。
给定正边距
,数据样本
和生成样本
,鉴别器损失
和生成器损失
在形式上由以下定义:
其中,
。
使 相对于 参数最小化类似于使 的第二项最大化。当 时,它具有最小但非零的相同梯度。
2.2 此方法的改进之处
本节对 2.1 进行理论分析,说明如果系统达到纳什均衡,则生成器 产生与原始数据集的分布无法区分的样本。这部分是在非参数设置下完成的,假设 和 具有无限容量。给定一个生成器 ,令 是 的密度分布,其中 。换言之, 是由 生成的样本的密度分布。
令
,
。作者训练判别器
以最小化
,训练生成器
以最小化
。系统的纳什均衡是一对
,满足:
定理1 如果
是一个使得系统达到纳什均衡的状态,那么在几乎所有地方
,并且
。
证明 首先考察
函数
的分析(详情见附录A的引理1)表明了:
(a)在几乎任何地方,
。下面对其进行验证,假设存在一组非零的度量,使得
。若
,则
违反了 式子(3) 。
(b)如果
,则函数
达到其最小值
,否则为 0 。 所以当用这些值代替
时,
达到最小值。由此可得,
公式10 的第二项是非正的,因此
。通过把理想地产生
的生成器放在 公式4 的右边,得到
然后根据公式6,有
由于
,可以得到
。
因此,
,即,
。根据 公式10 ,如果
时这种情况成立,当且仅当
时在几乎每一个点都成立(因为
和
都是概率密度,详情见 附录A 中的 引理2 )。
定理2 如果一个系统具有以下特征:
(a)
(几乎在所有地方成立);
(b)存在一个常数
使得
(在几乎所有地方成立)。
则系统的纳什均衡存在。
证明: 见附录A。
2.3 使用Auto Encoder
在本文的实验中,判别器被构造成一个Auto Encoder:
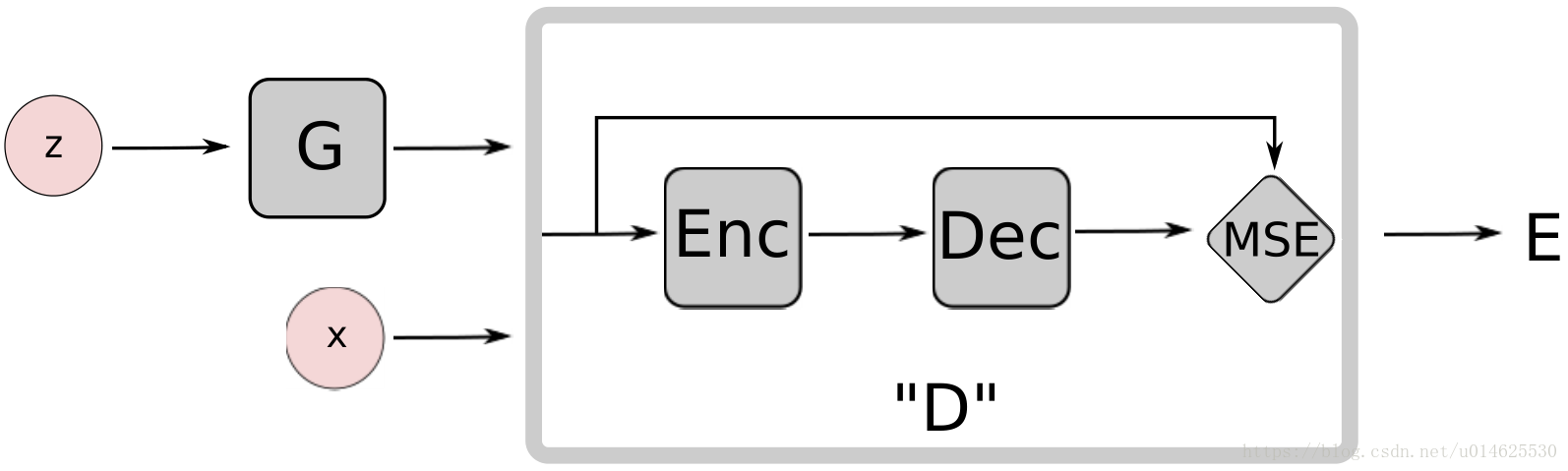
带有自动编码器鉴别器的EBGAN模型如 图1 所示。
的自动编码器的选择乍一看似乎是任意的,但作者的设定使得它比二元分类网络更有吸引力:
(1)基于重建的输出不是使用单个目标信息来训练模型,而是为判别器提供多样化的目标。由于二元分类网络,只有两个目标是可能的,所以在一个小批次内,对应于不同样本的梯度最有可能远离正交,这导致了低效率的训练,并且当前的硬件通常不提供减少小批量的尺寸的选择。另一方面,重建损失可能会在批次内产生非常不同的梯度方向,允许更大的批量大小而不损失效率。
(2)传统上使用自动编码器来表示基于能量的模型。当用正则化训练时(参见 2.3.1 ), 自动编码器可以在无监督或反例的情况下学习能量流形。这意味着,当EBGAN自动编码模型被训练以重构真实样本时,判别器也有助于发现数据流形。相反,如果没有来自生成器的负面例子,用二元分类损失训练的判别器变得毫无意义。
2.3.1 与标准的Auto Encoder的联系
训练自动编码器的一个常见问题是,模型可能学到的不是一个恒等函数,这意味着它可能将整个空间赋值为0能量。为了避免这个问题,必须强制模型给数据流形之外的点提供更高的能量。理论和实验结果通过规范潜在的表示来解决这个问题(Vincent等,2010;Rifai等,2011;MarcAurelio Ranzato & Chopra,2007;Kavukcuoglu等,2010)。这种规范器旨在限制自动编码器的重构能力,使得它只能将低能量归入较小部分的输入点。
作者认为,EBGAN框架中的能量函数(判别器)也被看作是通过产生对比性的样本的发生器来规范化的,判别器应该给予对比性的样本赋予高的重构能量。从这个角度来看,EBGAN框架允许更多的灵活性,因为:(i)规范器(生成器)完全可以训练而不是人工指定;(2)对抗训练模式使产生有对比性的样本与学习能量函数两个目标之间可直接相互作用。
2.4 排斥性正规化器
作者提出一个适合EBGAN自动编码器模型的“排斥正规化器”,有意使得模型不生成 集中于一个或几个聚类中的样本。Salimans等人2016年提出的“小批量判别”运用了同样的技术。
“排斥正规化器”的实现包含在代表级别的一个“拉走”项(PT)。 形式上,令
表示一批取自编码器输出层的样本。定义 PT 为:
PT 在最小批次上运行,并试图对成对的样本进行正交化表示。它的灵感来自于之前展示了自动编码器在编码中代表性威力的工作(Rasmus等,2015;赵等,2015)。选择余弦相似性而不是欧几里得距离的理论基础是使为了使 PT 有下界,并且对于尺度具有不变性。文中使用符号“EBGAN-PT”来指代用 PT 训练的EBGAN自动编码器模型。 PT 只用于生成器损失,但不用于判别器损失。
3 相关工作
本文的工作主要是将GAN转化为基于能源的模型。在这个方向上,研究对比样本的方法与EBGAN相关,如使用噪声样本(Vincent等人, 2010) ,和噪声梯度下降方法(如Contrastive Divergence(Carreira-Perpinan&Hinton, 2005)。从GAN的角度出发,有一些提高GAN训练稳定性的论文,如(Salimans等,2016;Denton等,2015;Radford等,2015;Im等,2016;Mathieu等,2015)。
Kim和Bengio(2016)提出概率GAN,并用吉布斯分布将其转化为基于能量的密度估计。与EBGAN相比,这个提出的框架并没有摆脱具有计算难度的分割函数,因此能量函数的选择是需要被整合的。
4 实验
4.1 在MNIST上的网格搜索
本节研究了EBGANs和GANs的训练稳定性,在一个完全连通网络的MNIST数字生成的简单任务上。作者对这两个框架的一系列架构选择和超参数进行彻底的网格搜索。

在形式上,本文按照 表1 进行grid search。此处对EBGAN模型施加了以下限制:(i)对
和
使用学习率0.001和Adam(Kingma&Ba,2014) ;(ii) - nLayerD表示Enc和Dec组合的总层数。为简单起见,将Dec定为一层,只调整Enc层;(iii)边距设置为10,未被调整。为了分析结果,这里使用inception score(Salimans等,2016)作为反映生成质量的一种数字手段。在保持得分原始含义的同时, 对公式做了一些细微的修改(
)来制作 图2 (更多细节见 附录C)。简而言之,较高的
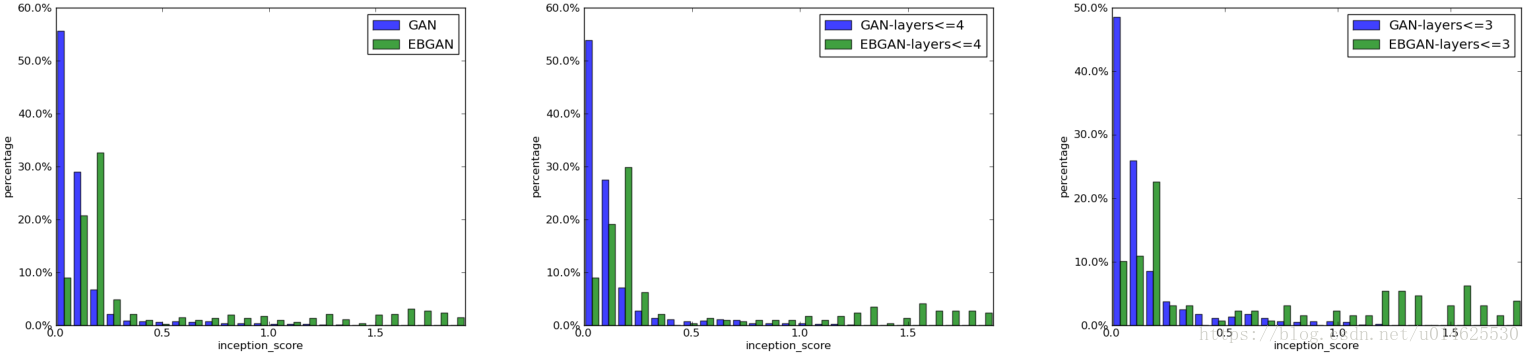
得分意味着更好的生成质量。
图2: 网格搜索的inception score的直方图。 x轴是Inception Score
,y轴表示落入特定分箱的模型百分比。
左图(a):EBGAN与GAN的一般比较;
中间(b):EBGANs和GAN均受nLayer[GD]<= 4的限制;
右图(c):EBGAN和GAN都受nLayer [GD] <= 3约束。
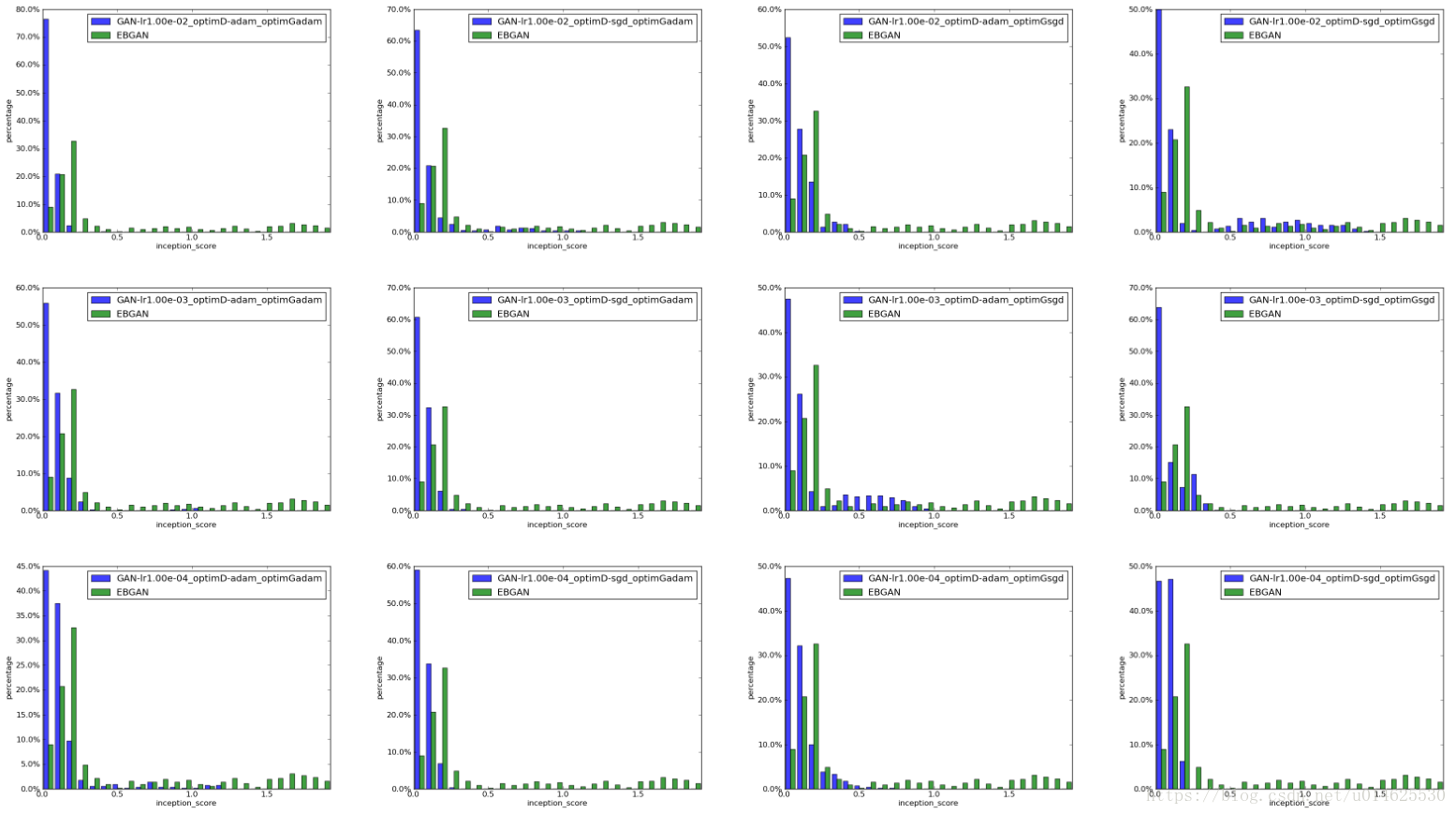
在 图2 中绘制了
得分的直方图。进一步从GAN网格中分离出优化相关设置(optimD,optimG和lr),并分别绘制每个子网格的直方图,以及EBGAN
分数作为参考,如图3所示。GANs和EBGANs的实验数量在每个子图中都是512。 直方图表明,EBGANs被更可靠地训练。
图3: 根据optimD,optimG和lr绘制不同优化组合的inception score的柱状图。
4.2 在MNIST上的半监督学习
作者探索使用EBGAN框架对置换不变的MNIST数据集进行半监督学习的能力,共同使用100,200和1000个标签。作者利用低层成本梯形网络(LN)(Rasmus等,2015)与EGBAN框架(EBGAN-LN)。梯形网络可以被归类为基于能量的模型,该模型由前馈和反馈层次结构构建,通过逐级隐含连接来联合这两种通路。
表2 PI-MNIST半监督任务下的LN底层成本模型及其EBGAN扩展的比较,结果是错误率(%),并在15个不同的随机种子上取平均值。

EBGAN半监督学习框架中至关重要的技术是逐渐衰减方程的边际值m1。其基本原理是当 接近数据流形时,让判别器惩罚生成器。人们可以想到极端情况下,有对比性的样本被精确地固定在数据流形上,使得它们“不再是对立的”。这种极端状态发生在m=0时,EBGAN-LN模型回退到正常的梯形网络。在GAN或EBGAN的判别器中不必需使用非衰减的训练方式,这由 定理2 陈述:在收敛的时候,判别器反映了一个平坦的能量面。作者假定学习EBGAN-LN模型的过程确实通过让对比样本来为LN(判别器)提供更多的信息。然而,避免上述不合要求的最佳方法是在达到纳什均衡时确保m衰减到0。在实验中,边缘衰减时间表是通过超参数搜索找到的(技术细节见附录D)。
表2 表明,将底层成本LN添加到EBGAN框架中有力地提高了LN本身的性能。假定在EBGAN框架的范围内,将由发生器产生的对比样本迭代地馈送到能量函数中作为有效的正则化器;对比样本可以被认为是向分类器提供更多信息的数据集的扩展。两者之间的结果是有差异的(Rasmus等,2015;Pezeshki等,2015),所以本文对比了这两个实验结果以及作者自己实现的运行相同设置的梯形网络的效果。具体的实验设置和分析见附录D。
图4 在MNIST数据集上用grid search生成的效果图。
左(a):最好的GAN模型;
中(b):最好的EBGAN模型;
右(c):最好的EBGAN-PT模型。

4.3 在LSUN和CELEBA数据集上的实验
作者应用EBGAN框架与深卷积体系结构来生成64×64的RGB图像,这是一个更现实的任务,使用LSUN卧室数据集(Yu等,2015)和大规模人脸数据集CelebA在(Liu等,2015)。作者比较了EBGAN和DCGAN(Radford等,2015),在相同的配置下训练一个DCGAN模型,并用EBGAN模型进行端到端生成,如 图5 和 图6 所示。具体设置在附录C中列出。
图5: 基于LSUN卧室数据集的生成图片。左(a):DCGAN的生成结果。右(b):EBGAN-PT的生成结果。
图6 从CelebA数据集生成的结果。左(a):DCGAN生成的结果。右(b):EBGAN-PT生成的结果。


4.4 Image Net数据集上的实验
最后,作者在ImageNet上训练EBGAN以生成高分辨率图像(Russakovsky等, 2015)。与迄今为止已经实验过的数据集相比,ImageNet提供了一个更广泛和更大的数据集,所以通过生成模型对数据分布进行建模变得非常具有挑战性。作者进行了一个实验,生成128×128的图像,在完整的ImageNet-1k数据集上进行训练,其中包含来自1000个不同类别的大130万幅图像。作者还训练了一个网络,在ImageNet的一个狗的子集上生成大小为256×256的图像,使用由Vinyals等人2016年提供的wordNet ID。结果如 图7 和 图8 所示。尽管难以在高分辨率的水平上生成图像,但作者观察到EBGAN能够了解到物体出现在前景的事实,以及各种类似草纹理的背景成分,地平线下的海,镜像山水,建筑物等。另外,作者的256×256的狗的生成图片,虽然距离现实图片很远,但反映了一些有关狗的外观,如他们的身体,毛皮和眼睛的知识。


5 展望
作者将两类无监督学习方法(GAN和自动编码器)联系起来,并从可替代能量的角度重新审视GAN框架。EBGAN显示更好的收敛模式和可扩展性来生成高分辨率的图像。 一系列以能量为基础的损失函数LeCun等人(2006)可以很容易地被纳入EBGAN框架。对于未来的工作,conditional setting(Denton等,2015;Mathieu等,2015)是一个值得探索的有前途的设定。作者希望今后的研究能够从能量的角度更广泛地关注GANs。
致谢
感谢Emily Denton,Soumith Chitala,Arthur Szlam,Marc’Aurelio Ranzato,Pablo Sprech-mann,Ross Goroshin和Ruoyu Sun进行了卓有成效的讨论,也要感谢Denton和Tian Jiang对稿件的帮助。
参考文献
Carreira-Perpinan, MiguelAandHinton, Geoffrey. Oncontrastivedivergencelearning. In AISTATS, volume10, pp. 33–40. Citeseer, 2005.
Denton, Emily L, Chintala, Soumith, Fergus, Rob, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In Advances in neural information processing systems, pp. 1486–1494, 2015.
Goodfellow, Ian, Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, and Bengio, Yoshua. Generative adversarial nets. In Advances in Neural Information Processing Systems, pp. 2672–2680, 2014.
Im, Daniel Jiwoong, Kim, Chris Dongjoo, Jiang, Hui, and Memisevic, Roland. Generating images with recurrent adversarial networks. arXiv preprint arXiv:1602.05110, 2016.
Ioffe, Sergey and Szegedy, Christian. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
Kavukcuoglu, Koray, Sermanet, Pierre, Boureau, Y-Lan, Gregor, Karol, Mathieu, Michaël, and Cun, Yann L. Learning convolutional feature hierarchies for visual recognition. In Advances in neural information processing systems, pp. 1090–1098, 2010.
Kim, Taesup and Bengio, Yoshua. Deep directed generative models with energy-based probability estimation. arXiv preprint arXiv:1606.03439, 2016.
Kingma, Diederik and Ba, Jimmy. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
LeCun, Yann, Chopra, Sumit, and Hadsell, Raia. A tutorial on energy-based learning. 2006.
Liu, Ziwei, Luo, Ping, Wang, Xiaogang, and Tang, Xiaoou. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, pp. 3730–3738, 2015.
MarcAurelio Ranzato, Christopher Poultney and Chopra, Sumit. Efficient learning of sparse representations with an energy-based model. 2007.
Mathieu, Michael, Couprie, Camille, and LeCun, Yann. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.
Pezeshki, Mohammad, Fan, Linxi, Brakel, Philemon, Courville, Aaron, and Bengio, Yoshua. Deconstructing the ladder network architecture. arXiv preprint arXiv:1511.06430, 2015.
Radford, Alec, Metz, Luke, and Chintala, Soumith. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
Ranzato, Marc’Aurelio, Boureau, Y-Lan, Chopra, Sumit, and LeCun, Yann. A unified energy-based framework for unsupervised learning. In Proc. Conference on AI and Statistics (AI-Stats), 2007.
Rasmus, Antti, Berglund, Mathias, Honkala, Mikko, Valpola, Harri, and Raiko, Tapani. Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems, pp. 3546–3554, 2015.
Rifai, Salah, Vincent, Pascal, Muller, Xavier, Glorot, Xavier, and Bengio, Yoshua. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th international conference on machine learning (ICML-11), pp. 833–840, 2011.
Russakovsky, Olga, Deng, Jia, Su, Hao, Krause, Jonathan, Satheesh, Sanjeev, Ma, Sean, Huang, Zhiheng, Karpathy, Andrej, Khosla, Aditya, Bernstein, Michael, Berg, Alexander C., and Fei-Fei, Li. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, doi: 10.1007/s11263-015-0816-y.
Salimans, Tim, Goodfellow, Ian, Zaremba, Wojciech, Cheung, Vicki, Radford, Alec, and Chen, Xi. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016.
Vincent, Pascal, Larochelle, Hugo, Lajoie, Isabelle, Bengio, Yoshua, and Manzagol, Pierre-Antoine. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11(Dec):3371–3408, 2010.
Vinyals, Oriol, Blundell, Charles, Lillicrap, Timothy, Kavukcuoglu, Koray, and Wierstra, Daan. Matching networks for one shot learning. arXiv preprint arXiv:1606.04080, 2016.
Yu, Fisher, Seff, Ari, Zhang, Yinda, Song, Shuran, Funkhouser, Thomas, and Xiao, Jianxiong. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
Zhao, Junbo, Mathieu, Michael, Goroshin, Ross, and Lecun, Yann. Stacked what-where auto-encoders. arXiv preprint arXiv:1506.02351, 2015.