前言
比赛都过去四天了也得补题,再简单也得补,虽然有轻微拖延症,但是有重度强迫症
B - How Old Are You Mr.String?(签到)
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
int a[30],b[30];
int t;
string s1,s2;
int main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>t;
for(int k=1;k<=t;k++){
cin>>s1>>s2;
memset(a,0,sizeof a);
memset(b,0,sizeof b);
for(int i=0;i<s1.size();i++){
a[s1[i]-'a']++;
}
for(int i=0;i<s2.size();i++){
b[s2[i]-'a']++;
}
int num=25;
int flag=0;
while(a[num]==b[num]){
num--;
if(num<0) break;
}
//cout<<num<<a[num]<<b[num]<<endl;
if(a[num]>b[num]) cout<<"Data set #"<<k<<": First string is older\n";
else if(a[num]<b[num]) cout<<"Data set #"<<k<<": First string is younger\n";
if(num<0) cout<<"Data set #"<<k<<": The two strings are the same age\n";
cout<<"\n";
}
return 0;
}
C - Clean Up the Powers that Be(模拟+setw函数应用)
Dr. Orooji, a number theoretician on the side, has written an amazing program that prime fectorizes numbers. He is so ecstatic that his program works, that he has forgotten to properly format (clean up) the output of his program. Luckily, Dr. O has hired you as a student assistant, to do his grunt work, formatting the output of his ingenius program. Your goal is to take the output of Dr. O’s program, and nicely format it for everyone else.
The Problem:
Dr. O’s output consists of several cases (data sets) which are theinput to your program. Each input case (to your program) contains several pairs of numbers, each pair being a base and an exponent. Although each of the bases are prime numbers already, Dr. O hasn’t bothered to list them in numerical order. Furthermore, sometimes he’s listed the same base several times - thus a 2^3 might be listed as well as a 2^5. Clearly these should be coalesced into one term, 2^8. Finally, Dr. O’s output does not put exponents in a “superscript” position. Your job will be to fix all three of these issues with each input case given.
The Input:
Input starts with a positive integer, n, on the first line by itself indicating the total number of test cases in the input file (i.e., the number of data sets to be processed). The next n lines contain the test cases, one per line. Each test case will contain several positive integers separated by spaces on a single line. The first positive integer on each line, k(0< k< 20), will represent the number of terms in the prime factorization for that case. This will be followed by k pairs of positive integers, all separated by spaces. The first integer of each pair will be a positive prime number less than 10,000 (representing a base). The second integer of each pair will be a positive integer less than 100,000, representing the exponent to which the corresponding prime number is raised in the prime factorization given.
The Output:
For each input case, first output thefollowing header line:
Prime Factorization #m:
where m(l ≤m≤n) represents the input case number (starting with 1).The rest of the output for each case will be on the following two lines. In particular, each base will be on the second line and each exponent will be on the first line. The bases will be in ascending numerical order. The corresponding exponents will start in the following column (after its base ends) on the first row. Each following base will start in the next column after the previous exponent.
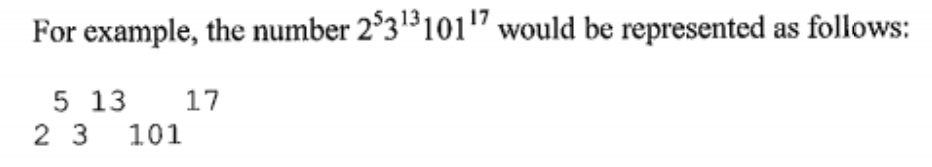 Leave a blank line after the output for each data set. Follow the format illustrated in Sample Output.
Leave a blank line after the output for each data set. Follow the format illustrated in Sample Output.
1.题意:给出一系列指数式的底数和指数,让我们合并同底数的式子并按如图所示输出
2.不难发现对于第一行的指数,前面的空格个数是其对应底数的长度。而对于第二行的指数,每一个后面空格个数是其指数对应长度。那么我们只需求出每一个结果的长度,使用setw()填充空格即可。而指数的合并使用map,底数升序输出就用set保存即可。注意setw(int len)只对后面要输出的部分进行空格填充(包括后面的输出的长度),但是如果后面什么都没有我们需要再输出空格
如:
cout<<setw(7)<<23<<endl;
// (五个空格)23
cout<<setw(4)<<' ';
// (四个空格)
#include <bits/stdc++.h>
#include <set>
#include <map>
using namespace std;
int t,u,d,n;
map<int,int> mp;
int a[1005],b[1005],c[1005];
int getNum(int x){
int ans=0;
while(x){
x/=10;
ans++;
}
return ans;
}
int main()
{
ios::sync_with_stdio(0);
cin>>t;
for(int k=1;k<=t;k++){
cin>>n;
set<int> s;
mp.clear();
while(n--){
cin>>d>>u;
s.insert(d);
mp[d]+=u;
}
cout<<"Prime Factorization #"<<k<<": \n";
int res=0;
for(auto i=s.begin();i!=s.end();i++){
int j=*i;
a[res]=getNum(j);
b[res]=getNum(mp[j]);
c[res++]=j;
}
for(int i=0;i<res;i++) cout<<setw(a[i]+b[i])<<mp[c[i]];
cout<<"\n";
for(int i=0;i<res;i++) cout<<c[i]<<setw(b[i])<<' ';
cout<<"\n";
if(k!=t) cout<<"\n";
}
return 0;
}
D - The Clock Algorithm(模拟)
In operating systems design, there is a technique called virtual memory, which enables the computer to run a program whose required memory(or logical memory) is larger than the available physical memory of the computer. The memory (for computer and program) are divided into pages, each consisting of a block of fixed size. When a program requests to access a page that is not yet loaded into memory, a page fault occurs. Thus, a page fault will occur the first time each page is accessed. In addition, if the program needs to access more pages than the available memory can provide, one of the pages that were loaded previously will have to be swapped out (written onto disk) in order to provide free memory space for the requested page. The algorithm that decides which page to swap out is called the page replacement strategy. One of the widely-known replacement algorithm is called the least-recently-used (LRU) strategy.
The Problem:
In this problem, we’ll explore a variation of LRU known as the clock algorithm. This algorithm works as follows. Initially, all n page cells in memory are free; you can think of them as an array with indices.Each element of the array contains the amount of memory for one page, and a “flag”.The clock algorithm also keeps a “hand pointer”, which initially points to cell 1.When the program needs to access a page, first it checks to see if the page is currently loaded in memory; if so, it simply accesses that page (no page fault) and sets the page’s flag to new.If the page it needs is not currently loaded in memory, then it loads the page in the next available free cell (cell with the lowest index) if there is one available and sets the page’s flag to new. If there is no free cell, then it checks the cell pointed by hand pointer. If the page pointed by hand is marked as old, then it will be swapped out for the new request (i.e., the page is loaded and marked as new) and the pointer advances one position. If the page pointed by hand is marked as new(i.e., the page is not old), the algorithm then marks that cell/page as old and the pointer advances one position. Advancing the pointer simply means the pointer will point to the next memory cell (with 1 higher index), and wraps back to the first cell if advancing from the V8(FN@MLA2}ICS2DI0%NGOQ.png cell, similar to the hands of a clock. Eventually, some page pointed by the hand will be seen as old and is swapped out, giving a free cell for the requested page.Note that when a page is referenced or loaded, its flag is set to new.This strategy gives each cell a second chance, being set to old before getting swapped out. If a page is referenced while the cell/page is old,it will be marked as new again, indicating that it is recently used. Thus a page will only be swapped out if the hand pointer sees it twice (first time marks it as old,and second time swaps it out) without the page ever being used during that period.Your task is to implement the clock algorithm.
The Input:
There will be multiple test cases. The first line of each test case contains two integers, n(1≤n≤ 50),the number of page cells in available memory, and r (1 ≤ r≤ 50), the number of page requests made by the program. The next line contains r integers ri, (1 ≤ri≤50), separated by spaces. These are pages that are accessed by the program (the pages are listed in the order of being accessed by the program).The last test case will be followed by a line which contains “0 0”, i.e., end-of-data is indicated by n = 0 and r = 0.
The Output:
At the beginning of each test case, output “Program p”,where p is the test case number (starting from 1). For each request, output: “Page ri loaded into cell c. ” if the request ri is not in memory, and is loaded into cell c. If the request ri is already in memory, output: “Access page ri in cell c” where c is the cell that page ri is located in memory. At the end of each test case, output: "There are a total of k page faults. "where k is the total number of page faults (loads) experienced during the execution of the program.Leave a blank line after the output for each test case. Follow the format illustrated in Sample Output.
Notes:
The size of each page is not important, as the input is already given in units of pages.
The logical memory requirement for a program is not specified, but you may assume that all programs have a size of 50 pages (as bounded by page request, ri).
究极模拟,这么长的题,看的我人都傻了
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int Max=310;
const int mod=1000000009;
int flag[Max],val[Max];
int main()
{
int m,n,cnt,num=0,x,ans;
while(scanf("%d%d",&m,&n)!=EOF)
{
if(m==0&&n==0)
break;
if(num)
printf("\n");
memset(flag,0,sizeof(flag));
memset(val,0,sizeof(val));
printf("Program %d\n",++num);
cnt=1;ans=0;
for(int i=0;i<n;i++)
{
int flag1=0;
scanf("%d",&x);
for(int i=1;i<=m;i++)
if(val[i]==x)
{
printf("Access page %d in cell %d.\n",x,i);
flag1=1;
flag[i]=1;
break;
}
if(flag1==1)
continue;
while(flag[cnt]==1)
{
flag[cnt]=0;
cnt++;
if(cnt==m+1)
cnt=1;
}
flag[cnt]=1;
val[cnt]=x;
printf("Page %d loaded into cell %d.\n",x,cnt);
cnt++;
ans++;
if(cnt==m+1)
cnt=1;
}
printf("There are a total of %d page faults.\n",ans);
}
return 0;
}
F - Metallic Equipment Rigid(圆和线段是否相交)
Rigid Reptile is trying to covertly infiltrate the compound of his nemesis Pistol Wildcat. The compound is under heavy surveillance by large numbers of video cameras and genetically enhanced soldiers. Luckily for Reptile, the soldiers’ enhancements grant them eyesight, hearing, and intelligence that is far inferior to that of an ordinary person. Between his cardboard box and tricks he picked up from Decoy Calamari, he’ll have little trouble evading the soldiers. The security cameras, though, are a different story.
The Problem:
The cameras in Pistol Wildcat’s compound have a circular detection radius which varies from camera to camera. Any unauthorized person (such as Rigid Reptile) who gets closer (≤) to a camera than the specified radius will immediately trigger an alarm. Ordinarily, the genetically enhanced soldiers think nothing of a person-sized cardboard box walking around, but when an alarm goes off, they are apt to shoot anything and everything. Naturally, Reptile would like to avoid this. You must write a program that, given Rigid Reptile’s path as a series of two-dimensional line segments and the positions and detection radii of the cameras, outputs which cameras (if any) Reptile gets too close to.
The Input:
Input begins with a single positive integer n, on a line by itself, indicating the number of compounds facing Rigid Reptile (i.e., the number of data sets to be processed). Following that line are n compound descriptions. The description of a compound begins with a line containing two integers c and p representing the number of cameras and the number of points along Reptile’s path, respectively, where 1 ≤c ≤ 50and 2 ≤p ≤ 50. The next c lines contain three integers indicating the x coordinate, y coordinate, and detection radius,respectively, of a camera (consider the first camera to be numbered 1, the second camera to be numbered 2, etc.). The following p lines each contain two integers representing the x and y coordinates of successive points along Reptile’s path (assume all points are distinct).
The Output:
Rigid Reptile moves in a straight line between successive points on his path. If at any time his Euclidean distance to a camera is less than orequal to its detection radius (or within 0.01), he has triggered that camera’s alarm. For each compound (data set), print a line indicating which cameras Reptile has triggered. This line should be of the form:
Compound #i: message
where i is the compound number (starting at 1). If Reptile triggered no cameras, message should be “Rigid Reptile was undetected”.If Reptile triggered one or more cameras, message should be of the form “Reptile triggered these cameras : list” where list is a list of the cameras triggered by reptile, sorted in ascending numerical order (leave exactly one space between numbers on this list).Leave a blank line after the output for each data set. Follow the format illustrated in
1.题目大意:有若干个圆,某生物的运动轨迹是若干线段(输入的是n个点),输出和这些线段相交的圆的个数
2.对于线段是否和圆相交注意两种情况即可:一是线段任意端点都不能在圆内,即到圆心的距离小于等于r,当都不在圆内时直接求点到线段的距离判断是否小于等于r,点到线段的判断方法详见我的博客
3.因为套了我自己板子的缘故,下面的代码有点长,读者自行寻找使用到的函数
#include <iostream>
#include <math.h>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
#define Point Vector
const double PI=acos(-1.0);
const double eps=1e-2;
inline int dcmp(double d){ //浮点数和0比较
if(fabs(d)<eps) return 0;
return d>0?1:-1;
}
inline int cmp(double x,double y){ //x>y返回1,x=y返回0,x<y返回-1
return dcmp(x-y);
}
struct Point{
double x,y;
Point(double a=0,double b=0):x(a),y(b){}
Vector operator + (Vector B){
return Vector(x+B.x,y+B.y);
}
Vector operator - (Point B){
return Vector(x-B.x,y-B.y);
}
Vector operator * (double d){ //数乘
return Vector(x*d,y*d);
}
double operator * (Vector B){ //数量积
return x*B.x+y*B.y;
}
Vector operator / (double d){
return Vector(x/d,y/d);
}
double operator ^ (Vector B){ //叉乘
return x*B.y-y*B.x;
}
bool operator < (const Point &b) const {
if(x==b.x) return y<b.y;
return x<b.x;
}
bool operator == (const Point& b) const {
if(dcmp(x-b.x)==0 && dcmp(y-b.y)==0)
return true;
return false;
}
};
double dis(Vector A){ //模长
return sqrt(A*A);
}
double sqrDis(Vector A){ //模长平方
return A*A;
}
double angle(Vector A,Vector B){ //向量夹角
return acos(A*B/dis(A)/dis(B));
}
Vector rotate(Vector A,double rad){ //逆时针旋转
return Vector(A.x*cos(rad)-A.y*sin(rad), A.x*sin(rad)+A.y*cos(rad));
}
Vector normal(Vector A){ //逆时针90°的法向量
double L=dis(A);
return Vector(-A.y/L, A.x/L);
}
bool ToLeftTest(Point c, Point b, Point a){ //判断折线bc是不是向ab的逆时针方向(左边)转向
return ((a-b)^(c-b)) > 0;
}
struct Line{
Point p,q; //默认p是起点
Vector v; //由p,q确定的方向向量p->q
Line(){}
Line(Point a,Point b){ //构造函数
p=a,q=b,v=b-a;
}
Point point(double t){ //点P=p+v*t
return p+v*t;
}
Point spos(){ //线段起点
return p;
}
Point tpos(){ //线段终点
return q;
}
double length(){ //线段长度
return sqrt(dis(v));
}
void print(){
printf("Line:(%lf,%lf)->(%lf,%lf)\n",p.x,p.y,q.x,q.y);
}
};
double disToLine(Point p,Line l){ //点到直线距离
Vector v=p-l.p;
return fabs(l.v^v) / dis(l.v);
}
double disToSeg(Point p,Line l){ //点到线段距离
if(l.p==l.q) return dis(p-l.p);
Vector v1=p-l.p,v2=p-l.q;
if(dcmp(v1*l.v)<0) return dis(v1);
if(dcmp(v2*l.v)>0) return dis(v2);
return disToLine(p,l);
}
Point getPro(Point p,Line l){ //点在直线投影
return l.p+l.v*(l.v*(p-l.p)/dis(l.v));
}
bool isOnLine(Point p,Line l){ //点是否在直线上
return dcmp((l.p-p)^(l.q-p))==0?true:false;
}
bool isOnSeg(Point p,Line l){ //点是否在线段上
return dcmp((l.p-p)^(l.q-p))==0 && dcmp((l.p-p)*(l.q-p))<0;
}
bool isLineInter(Line a,Line b){ //两直线是否相交
return dcmp(a.v^b.v)==0?false:true;
}
Point getLineInter(Line a,Line b){ //返回两直线交点
Vector u = a.p-b.p;
double t = (b.v^u) / (a.v^b.v);
return a.point(t); //或者a.p+a.v*t;
}
bool isSegInter(Line a,Line b){ //线段是否相交
double c1=a.v^b.p-a.p,c2=a.v^b.q-a.p;
double c3=b.v^a.p-b.p,c4=b.v^a.q-b.p;
//判断两线段端点是否在另外一条线段上
if(!dcmp(c1) || !dcmp(c2) || !dcmp(c3) || !dcmp(c4)){
bool f1=isOnSeg(b.p,a);
bool f2=isOnSeg(b.q,a);
bool f3=isOnSeg(a.p,b);
bool f4=isOnSeg(a.q,b);
bool f=(f1|f2|f3|f4);
return f;
}
return (dcmp(c1)*dcmp(c2)<0 && dcmp(c3)*dcmp(c4)<0);
}
bool isLineSegInter(Line a,Line seg){ //判断直线和线段是否相交
double c1=a.v^seg.p-a.p,c2=a.v^seg.q-a.p;
return dcmp(c1)*dcmp(c2)<0;
}
struct Circle{
Point o;
double r;
Circle(){}
Circle(Point o,double r):o(o),r(r) {}
Point point(double a){ //通过圆心角(弧度)求圆上一点坐标
return Point(o.x+cos(a)*r,o.y+sin(a)*r);
}
};
bool getLineCircleInter(Line l,Circle c){
if(sqrDis(l.p-c.o)<c.r*c.r || dcmp(sqrDis(l.p-c.o)-c.r*c.r)==0){
return 1;
}
if(sqrDis(l.q-c.o)<c.r*c.r || dcmp(sqrDis(l.q-c.o)-c.r*c.r)==0){
return 1;
}
if(disToSeg(c.o,l)<c.r || dcmp(disToSeg(c.o,l)-c.r)==0){
return 1;
}
return 0;
}
int t,n,m;
double x,y,r;
set<int> s;
Circle cir[105];
Line lin[105];
Point poi[105];
int main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>t;
int kase=1;
while(t--){
cin>>n>>m;
s.clear();
for(int i=1;i<=n;i++){
cin>>x>>y>>r;
cir[i]=Circle(Point(x,y),r);
}
for(int i=1;i<=m;i++){
cin>>x>>y;
poi[i]=Point(x,y);
}
for(int i=1;i<m;i++) lin[i]=Line(poi[i],poi[i+1]);
for(int i=1;i<m;i++){
for(int j=1;j<=n;j++){
if(getLineCircleInter(lin[i],cir[j])) s.insert(j);
}
}
cout<<"Compound #"<<kase++<<": ";
if(s.empty()){
cout<<"Rigid Reptile was undetected\n";
cout<<"\n";
continue;
}
cout<<"Reptile triggered these cameras: ";
int j=1;
for(auto i=s.begin();i!=s.end();i++,j++){
if(j==s.size()){
cout<<*i<<"\n";
}else cout<<*i<<" ";
}
cout<<"\n";
}
return 0;
}
G - Lifeform Detector (字符串)
Government scientists at Area 51 are developing a new program to detect alien lifeforms. In particular, they are interested in finding evidence of additional visits by aliens in the 1950’s. From their first visit, the scientists have the make-up of the aliens’ DNA (which is radically different from human DNA). The complete grammar for the DNA is as follows (lower-case letters represent terminal symbols and Σ is the empty string):

TheProblem:
Given possible alien DNA patterns, determine if they match the alien DNA description given by the grammar.
The Input:
The first line of the input will consist of a positive integer n,representing the number of DNA patterns (i.e., the number of data sets to be processed). Each of the next n lines will contain a string of lower-case letters (at least one letter and at most 50 letters) that represent the pattern to check against the alien DNA grammar. Note that the input will be at least one letter even though the grammar allows for empty (null) string, i.e., empty string will not be in the input. Assume that input will not contain any character other than lower-case letters.
The Output:
For each DNA pattern, output the header ''Pattern i: " where i is the number of the pattern in the input(starting with 1). Then, print “More aliens!” if the pattern matches the alien DNA description or "Still Looking."if the pattern does not match. Leave a blank line after the output for each data set. Follow the format illustrated in Sample Output.
1.题目大意:给出如图所示的格式,判断给定的字符串是否符合如图的格式。图片的意思是< s >串和后面两种形式是等价的,同理< t >
2.想了好久,自己不经常做字符串的题真的挺菜的。首先我们观察两个串的形式,发现他们都是一层套一层的(禁止套娃!),然后二者的区别也就是空串。因此我们发现,但凡出现了a< t >b< s >的,当且仅当最里面的< t > 是c时,这一循环才能停止,否则将是无限循环的字符串。那么也就是最里面的一层或者并列的多层一定都是acb这种形式的
3.具体做法:首先排除非a,b,c字母的串,因为a< t >b< s >结构的原因,我们先设置一个sum初始为0,当每碰见a时加一,每碰见b时自减,如果中途sum<0了,失败,如果最后sum不等于0也失败。这样判断的原理是每一个a后面必须有一个b和它组成a< t >b< s >结构。最后再判断是否出现"ab"这样连续的子串即可
#include <iostream>
#include <string>
using namespace std;
bool solve(string s){
int sum=0;
for(int i=0;i<s.size();i++){
if(s[i]!='a' && s[i]!='b' && s[i]!='c') return false;
if(s[i]=='a') sum++;
if(s[i]=='b') sum--;
if(sum<0) return false;
}
if(sum!=0) return false;
if(s.find("ab")!=-1){
return false;
}
return true;
}
int main()
{
string s;
int t;
cin>>t;
for(int kase=1;kase<=t;kase++){
cin>>s;
if(solve(s)){
cout<<"Pattern "<<kase<<": More aliens!"<<endl<<endl;
}else cout<<"Pattern "<<kase<<": Still Looking."<<endl<<endl;
}
return 0;
}
H - Ordered Numbers(签到)
整这么恶心的格式,无聊,签到题33%的AC率
#include <iostream>
#include <algorithm>
using namespace std;
int a[10];
int t;
int main()
{
ios::sync_with_stdio(0);
cin>>t;
for(int kase=1;kase<=t;kase++){
cout<<"Data set #"<<kase<<":\n";
for(int i=0;i<3;i++){
cin>>a[i];
}
cout<<" "<<"Original order: ";
for(int i=0;i<2;i++) cout<<a[i]<<" ";
cout<<a[2]<<"\n";
sort(a,a+3);
cout<<" "<<"Smallest to largest: ";
for(int i=0;i<2;i++) cout<<a[i]<<" ";
cout<<a[2]<<"\n";
if(kase!=t) cout<<"\n";
}
return 0;
}
