今天我们主要解决以下实际问题:一份黑名单数据存储在excel中,由于数据量庞大,现需要通过pandas找到某一列的重复数据,处理后再存入到excel中。
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,主要数据结构为两个类:
DataFrame: 可以理解为表格,类似于Excel的表格 pandas.core.frame.DataFrame
Series: 表示单列。DataFrame包含多个列,即多个Series,每个Series都有名称。pandas.core.series.Series
Pandas所支持的数据类型(dtype):
1. float (float64)
2. int (int64,uint64)
3. bool
4. datetime64[ns] (2013-01-02)
5. datetime64[ns, tz]
6. timedelta[ns]
7. category
8. object (字符串)
默认的数据类型是int64,float64
以下是原始的excel文件

先查看文件中Series每一列的数据类型
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx')
change_data_type()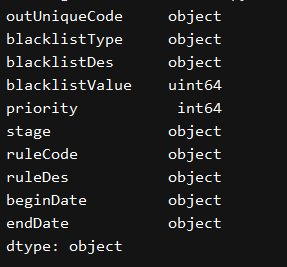
我们发现blacklistValue默认是int类型,但我们知道身份证18位,再次存入excel中时后面几位会变成0,所以我们需要对这列进行数据类型转换。主要有两种思路,一种是读取excel时转换,另外一种是读取后转换。
一、读取时全部转换为字符串,dtype='object'或者dtype='str'
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype='object') # dtype='str'
change_data_type()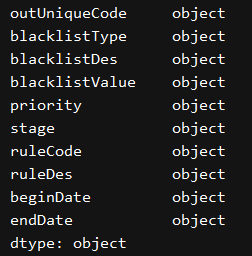
二、读取时指定列转换为字符串,object或者str
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype = {'blacklistValue' : object,'priority':str}) # dtype='str'
change_data_type()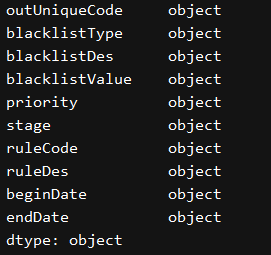
三、读取后转换为字符串: astype(str),不可以使用astype(object)-->存入到excel时还是int类型。
import pandas as pd
# 更改数据类型
def change_data_type():
excel_df[['blacklistValue','priority']] = excel_df[['blacklistValue','priority']].astype(str)
print(excel_df.dtypes)
excel_df.to_excel('excel_to_python.xls',sheet_name='sheet', index=False)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx') # dtype='str'
change_data_type()
