Hadoop的由来
hadoop是用于处理分布式存储和分布式计算的一个大数据处理框架。2002年,google开源了GFS论文。一个叫Doung Cutting的人根据GFS论文写了一个HDFS模块,解决了分布式存储的问题;2004年,google又开源了MapReduce论文,Doung Cutting又根据这篇论文写了一个MapReduce模块。后来将HDFS和MapReduce拆分出来,就形成了一个大数据处理平台——Hadoop
Hadoop概述
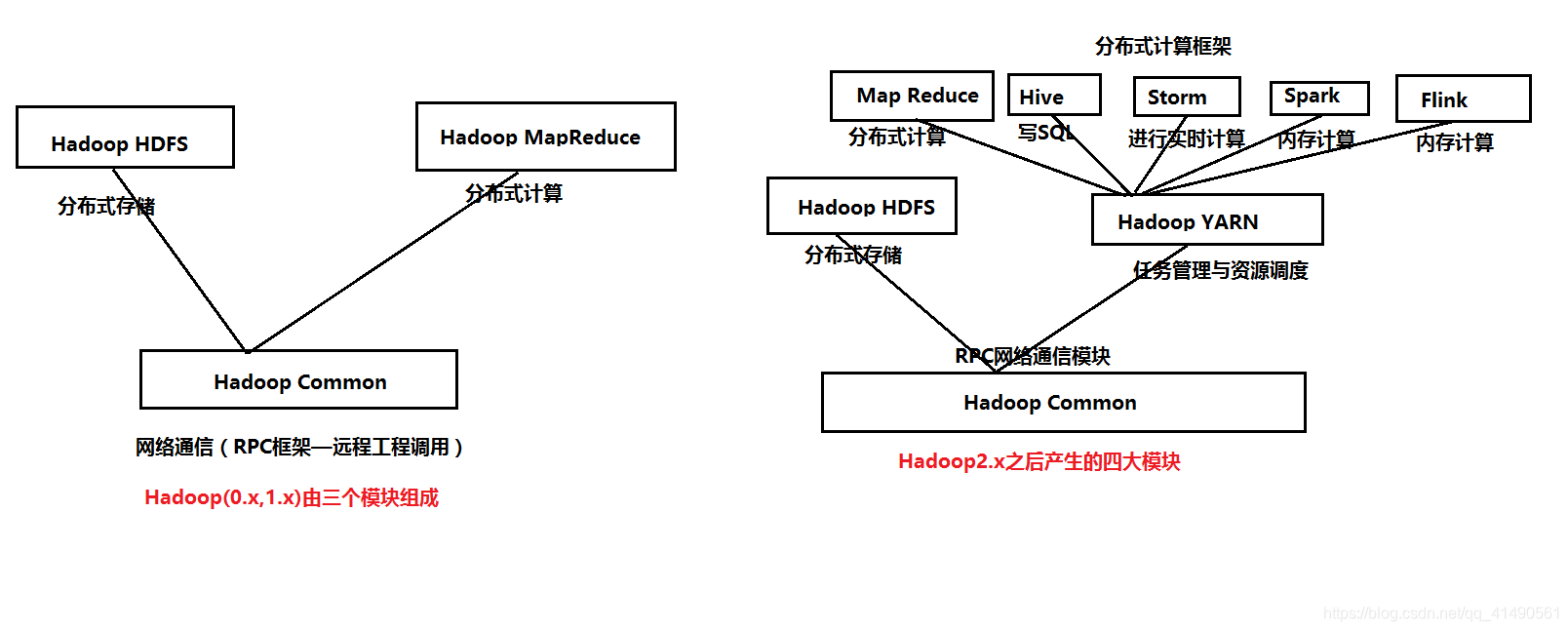
Hadoop项目主要包括以下四个模块:
1.Hadoop Common
为其他Hadoop模块提供基础设施
2. Hadoop HDFS
一个高可靠、高吞吐量的分布式文件系统
3. Hadoop MapReduce
一个分布式的离线并行计算框架
4. Hadoop YARN
任务调度与资源管理
HDFS组件

YARN四大组件
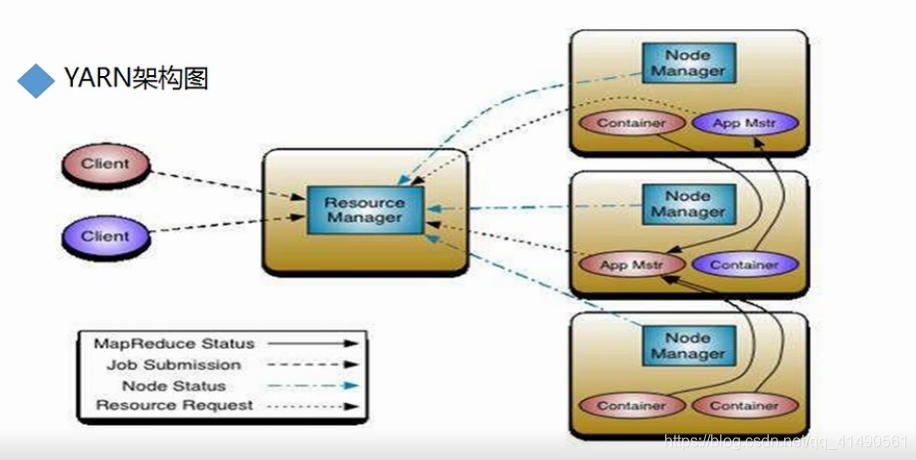
1.ResourceMangage(RM)
2.NodeManager(NM)
3.ApplicationMaster(AM)
4.Container
YARN执行流程
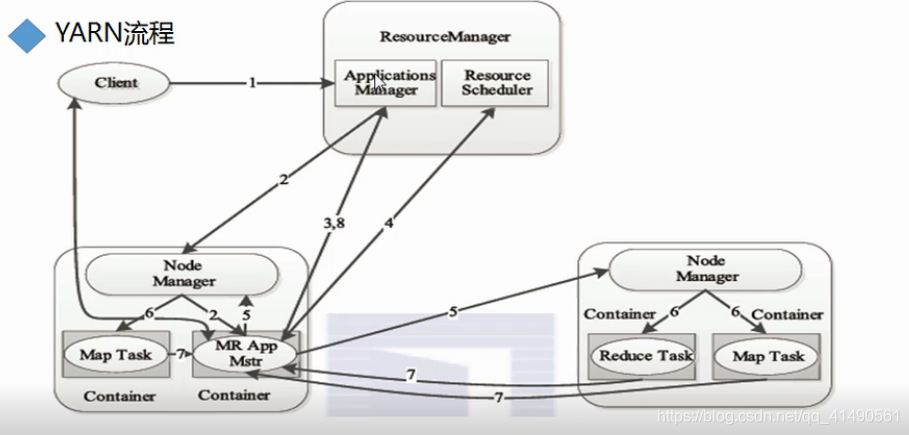
- Client连接RM提交作业,RM给Client一个Jobid(注:ApplicationManager和ResourceScheduler)
- RM 中的ApplicationsManager连接一个NM,让NM创建一个AM处理客户端作业请求
- AM连接RM中的ApplicationsManager申请NodeManager
- AM去ResourceScheduler给Client的作业申请资源(cpu、内存、磁盘、网络)
- AM连接NM,发送Client job作业程序和申请的资源(cpu、内存、磁盘、网络)
- NM启动Container进程运行job的不同任务
- Container进程运行状态实时反馈给AM
- AM反馈任务状态信息给RM中的ApplicationsManager
- Client端可以连接RM或AM查询job的执行情况
注:NM启动后去RM上进行注册,会不断发送心跳,说明处于存活状态
YARN组件作用


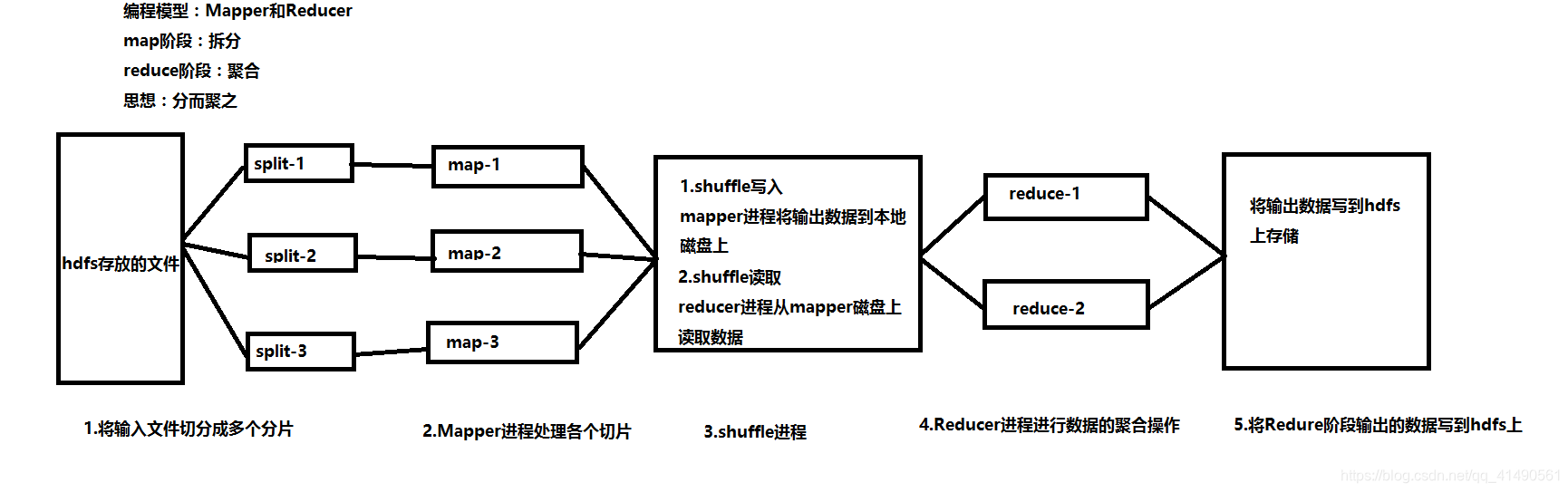
MapReduce执行流程

Hadoop生态系统
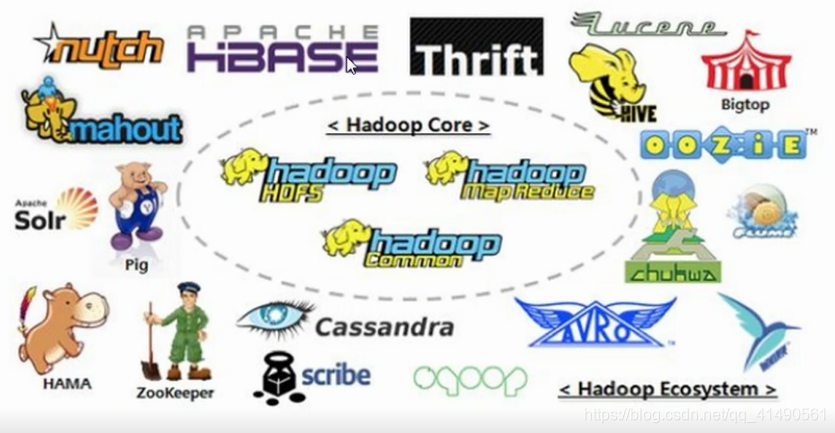
- Hadoop:分布式存储、分布式计算、资源调度与任务管理
hdfs、mapreduce、yarn、common - Lucene:索引检索工具包
- Solr:索引服务器
- Nutch:开源的搜索引擎
- HBase/Cassandra:基于谷歌的BigTable开源的列式存储的非关系型数据库
- Hive:基于SQL的分布式计算引擎,同时是一个数据仓库
- Pig:基于Pig Latin脚本的计算引擎
- Thrift/Avro:RPC框架,用于网络通信
- BigTop:项目测试、打包、部署
- Oozie/Azakban:大数据的工作流框架
- Chukwn/Scribe/Flume:数据收集框架
- Whirr:部署为云服务的类库
- Sqoop:数据迁移工具
- Zookeeper:分布式协调服务框架
- HAMA:图计算框架
- Mahout:机器学习框架
Hadoop环境
三个环境:
- 单机环境
- 伪分布式环境
- 分布式环境
三个分支:
- apache版本(Apache基金会)
- cdh版本(cloudera公司)
- hdp版本(HortOnWorks公司)
