一、hadoop简介
Hadoop起源于Google的三大论文:
- GFS:Google的分布式文件系统Google File System
- MapReduce:Google的MapReduce开源分布式并行计算框架
- BigTable:一个大型的分布式数据库
演变关系:
- GFS—->HDFS
- Google MapReduce—->Hadoop MapReduce
- BigTable—->HBase
Hadoop名字不是一个缩写,是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
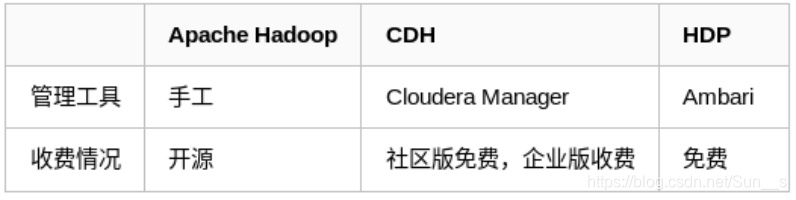
hadoop主流版本:
- Apache基金会hadoop
- Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
- Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
- HDFS为海量的数据提供了存储。
- MapReduce为海量的数据提供了计算。
Hadoop框架包括以下四个模块:
- Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
- Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
- Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
- Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
hadoop应用场景:
在线旅游
移动数据
电子商务
能源开采与节能
基础架构管理
图像处理
诈骗检测
IT安全
医疗保健
二、部署
get hadoop-3.2.1.tar.gz jdk-8u171-linux-x64.tar.gz
[root@server1 ~]# useradd -u 1001 hadoop
[root@server1 ~]# mv * /home/hadoop/
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ tar zxf hadoop-3.2.1.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-8u171-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.8.0_171/ java
[hadoop@server1 ~]$ ln -s hadoop-3.2.1 hadoop
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim hadoop-env.sh
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop]$ cat output/*
1 dfsadmin
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
vim ~/.bash_profile
source ~/.bash_profile
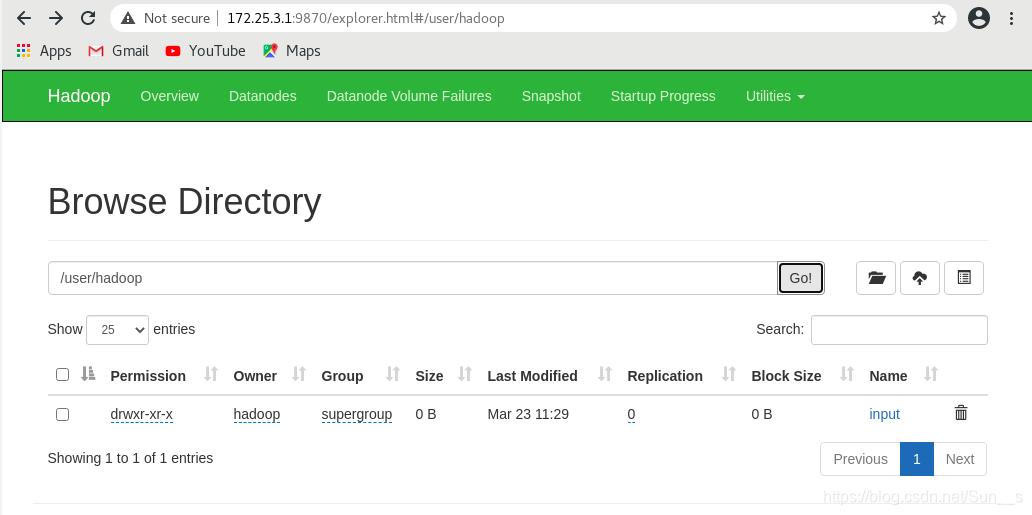
[hadoop@server1 ~]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ hdfs dfs -put input
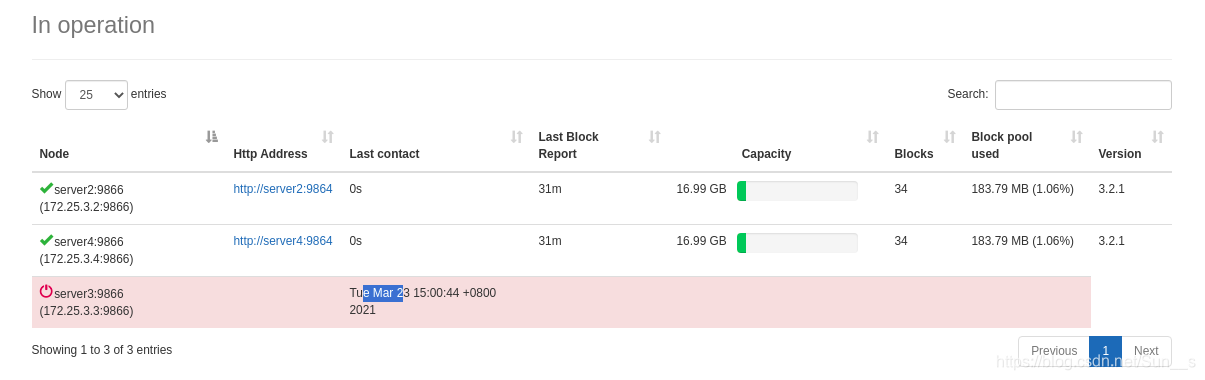
网页访问:172.25.3.1:9870查看上传结果
[root@server1 ~]# echo westos | passwd --stdin hadoop
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ ssh-copy-id localhost
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ cd sbin/
[hadoop@server1 sbin]$ ./start-dfs.sh
[hadoop@server1 hadoop]$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
[hadoop@server1 hadoop]$ hdfs dfs -ls input
[hadoop@server1 hadoop]$ hdfs dfs -cat output/*
[hadoop@server1 sbin]$ ./stop-dfs.sh
[root@server1 ~]# yum install nfs-utils.x86_64 -y
[root@server1 ~]# vim /etc/exports
[root@server1 ~]# systemctl start nfs
[root@server2 ~]# yum install -y nfs-utils #server3同样操作
[root@server2 ~]# useradd -u 1001 hadoop
[root@server2 ~]# showmount -e 172.25.3.1
Export list for 172.25.3.1:
/home/hadoop *
[root@server2 ~]# mount 172.25.3.1:/home/hadoop/ /home/hadoop/
[hadoop@server2 ~]$ jps
14426 Jps
14335 DataNode
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server1:9000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim workers
server2
server3
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ cd sbin/
[hadoop@server1 sbin]$ ./start-dfs.sh
[hadoop@server1 sbin]$ jps
19218 NameNode
19442 SecondaryNameNode
19562 Jps

[hadoop@server1 hadoop]$ hdfs dfs -mkdir -p /user/hadoop/
[hadoop@server1 hadoop]$ hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ hdfs dfs -put * input
热添加:
[root@server4 ~]# yum install nfs-utils -y
[root@server4 ~]# useradd -u 1001 hadoop
[root@server4 ~]# mount 172.25.3.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# su - hadoop
[hadoop@server1 hadoop]$ vim workers
server2
server3
server4
[hadoop@server4 hadoop]$ hdfs --daemon start datanode
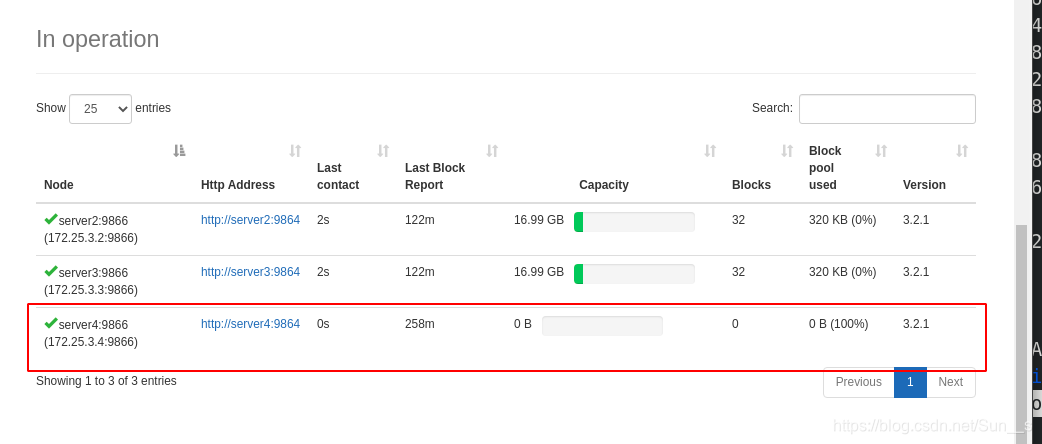
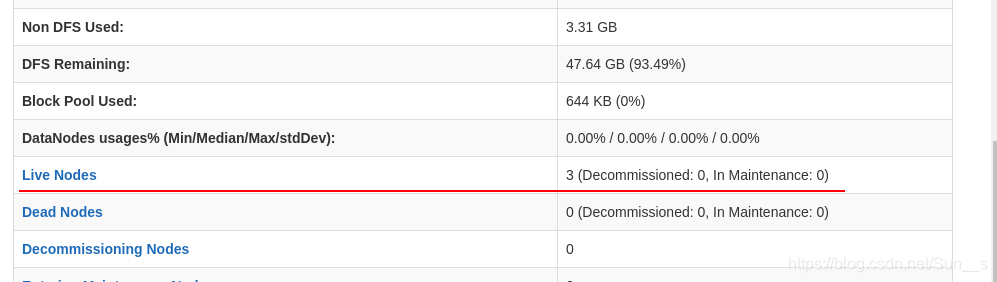
上传测试:
[hadoop@server4 ~]$ hdfs dfs -put jdk-8u171-linux-x64.tar.gz
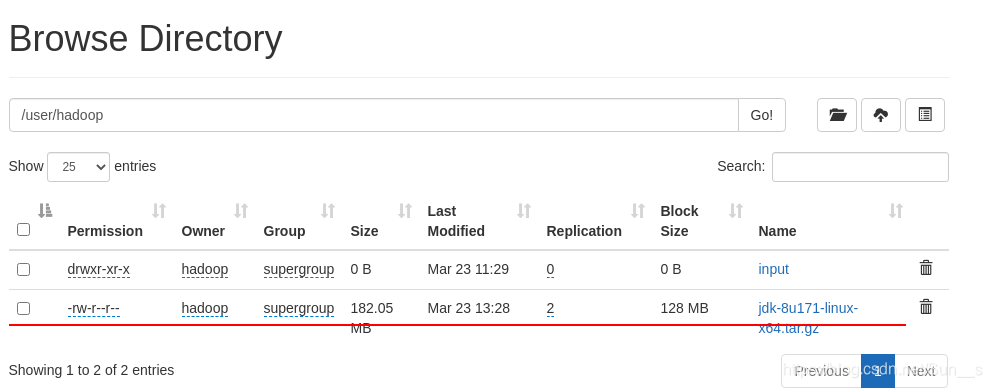
节点删除
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop/etc/hadoop/dfs.hosts.exclude</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/home/hadoop/hadoop/etc/hadoop/dfs.hosts</value>
</property>
</configuration>
[hadoop@server1 sbin]$ ./stop-dfs.sh
[hadoop@server1 sbin]$ ./start-dfs.sh
[hadoop@server1 hadoop]$ vim workers
server2
server3
server4
[hadoop@server1 hadoop]$ vim dfs.hosts.exclude
server3
[hadoop@server1 hadoop]$ vim dfs.hosts
server2
server3
server4