redis五种数据结构
说明:
- 对于Redis来说,它可以存储五种基本数据类型,
- redis中所有数据结构都以唯一的key字符串作为名称,然后通过这个唯一的key来获取对应的value
- 不同的数据类型数据结构差异就在于value的结构不一样
- 而现在的版本中的五种类型是:String(字符串)、Hash(字典)、List(列表)、Set(集合)、SortedSet(zSet:有序集合)
一、string(字符串)
-
1)value的数据结构(数组)
- 字符串是Redis中最常用的类型,是一个由字节组成的序列,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,Value最多可以容纳的数据长度为512MB。
- 字符串value数据结构类似于数组,采用与分配内存空间来减少内存频繁分配
- 如果字符串长度操作1MB时,扩容时最多扩容1MB空间,字符串最大长度为 512MB
-
2)字符串的使用场景(缓存)
- 字符串一个常见的用途是缓存用户信息,我们将用户信息使用JSON序列化成字符串
- 取用户信息时会经过一次反序列化的过程
注意:redis中的Key和Value是区分大小写的,命令是不区分大小写的, redis是单线程 不适合存储大容量的数据。自增的value是可以转成数字的。
基本操作:
set key value
往key中存入一个值(value)
get key
获取键为key的值
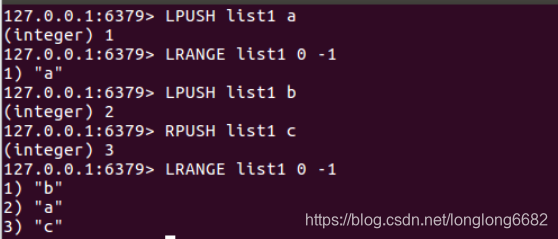
二、list(列表)
-
1)value的数据结构(双向链表)
- Redis的列表允许用户从序列的两端推入或者弹出元素,列表由多个字符串值组成的有序可重复的序列,获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。List中可以包含的最大元素数量是4294967295(接近43亿)。
- 列表的数据结构是双向链表,这意味着插入和删除的时间复杂度是0(1),索引的时间复杂度位0(n)
- 当列表弹出最后一个元素后,该数据结构会被自动删除,内存被回收
-
2)列表的使用场景(队列、栈)
- 应用场景:1.最新消息排行榜。2.消息队列,以完成多程序之间的消息交换。可以用push操作将任务存在list中(生产者),然后线程在用pop操作将任务取出进行执行(消费者)。
基本操作:
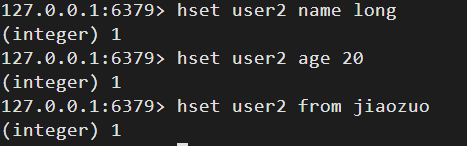
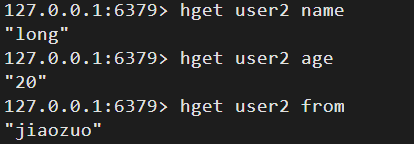
三、hash(字典)
-
1)value的数据结构(HashMap)
- redis中的字典也是HashMap(数组+列表)的二维结构
- 相当于是一个key中存在多个map。Redis中的散列可以看成具有String key和String value的map容器,可以将多个key-value存储到一个key中。每一个Hash(字典)可以存储4294967295(接近43亿)个键值对。
- 不同的是redis的字典的值只能是字符串
-
2)hash的使用场景(缓存)
- hash结构也可以用来缓存用户信息,与字符串一次性全部序列化整个对象不同,hash可以对每个字段进行单独存储
- 这样可以部分获取用户信息,节约网络流量
- hash的缺点是:hash结构的存储消耗要高于单个字符串(消耗内存)
基本操作:
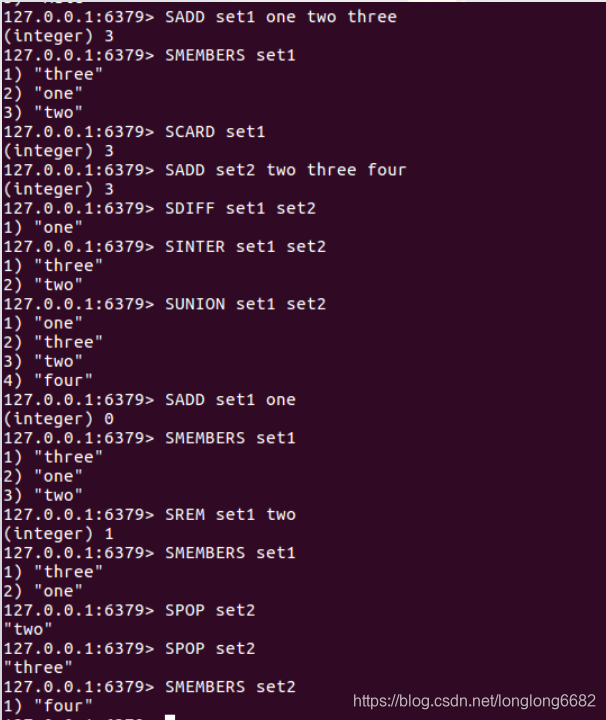
四、set(集合)
-
1)value的数据结构(字典)
- Redis的集合是无序且不可重复的,此处的无序是数据不能重复。和列表一样,在执行插入和删除以及判断是否存在某元素时,效率是很高的。集合最大的优势在于可以进行交集并集差集操作。Set可包含的最大元素数量是4294967295(接近43亿)。
- redis中的集合相当于一个特殊的字典。
- 当集合中的最后一个元素被移除后,数据结构会被自动删除,内存被回收
-
2)set使用场景(有唯一性)
- set结构可以用来存储某个活动中中奖的用户ID,因为有去重功能,可以保证同一用户不会中奖两次
- 利用交集求共同好友。
- 利用唯一性,可以统计访问网站的所有独立IP。
基本操作:
五、zset(有序集合)
有顺序,不能重复!!此处的不能重复是索引为唯一的,数据却可以重复。
-
1)value的数据结构(跳跃列表)
- 它可以给每一个value赋予一个score,代表这个value的唯一
- 和Set很像,都是字符串的集合,都不允许重复的成员出现在一个set中。他们之间差别在于有序集合中每一个成员都会有一个分数(score)与之关联,Redis正是通过分数来为集合中的成员进行从小到大的排序。尽管有序集合中的成员必须是唯一的,但是分数(score)却可以重复。
- zset内部实现用的是一种叫做“跳跃列表”的数据结构
- zset最后一个元素被移除后,数据结构就会被自动删除,内存也会被回收
-
2)zset应用场景
- 粉丝列表:value(粉丝ID),score(关注时间),这样可以轻松按关注事件排序
- 学生成绩:value(学生ID),score(考试成绩),这样可以轻松对成绩排序
- 可以用于一个大型在线游戏的积分排行榜,每当玩家的分数发生变化时,可以执行zadd更新玩家分数(score),此后在通过zrange获取几分top
ten的用户信息。
基本操作:
zadd zset1 9 a 8 c 10 d 1 e (添加元素 zadd key score member )
(ZRANGE key start stop [WITHSCORES])(查看所有元素:zrange key 0 -1
withscores)如果要查看分数,加上withscores.
zrange zset1 0 -1 (从小到大)
zrevrange zset1 0 -1 (从大到小)
zincrby zset2 score member (对元素member 增加 score)
1 127.0.0.1:6379> zadd zset1 8 a 4 b 5 c 1 d
2 (integer) 4
3 127.0.0.1:6379> zrange zset1 0 -1
4 1) "d"
5 2) "b"
6 3) "c"
7 4) "a"
8 127.0.0.1:6379> zadd zset1 9 a
9 (integer) 0
10 127.0.0.1:6379> zrange zset1 0 -1
11 1) "d"
12 2) "b"
13 3) "c"
14 4) "a"
15 127.0.0.1:6379> zrange zset1 0 -1 withscores
16 1) "d"
17 2) "1"
18 3) "b"
19 4) "4"
20 5) "c"
21 6) "5"
22 7) "a"
23 8) "9"
24 127.0.0.1:6379> zrevrange zset1 0 -1
25 1) "a"
26 2) "c"
27 3) "b"
28 4) "d"
29 127.0.0.1:6379> zincrby zset1 1 a
30 "10"
31 127.0.0.1:6379> zrevrange zset1 0 -1 withscores
32 1) "a"
33 2) "10"
34 3) "c"
35 4) "5"
36 5) "b"
37 6) "4"
38 7) "d"
39 8) "1"
六、总结一下五种类型的作用
- 1. String(缓存)
- 2. List(消息队列)
- 3. hash(缓存用户信息,可以对每个字段进行单独存储)
- 4. Set(set类似list,特殊之处是set可以自动排重:找两个人微博的共同好友)
- 5. ZSet(sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。)
