目录:
说明:
- redis中所有数据结构都以唯一的key字符串作为名称,然后通过这个唯一的key来获取对应的value
- 不同的数据类型数据结构差异就在于value的结构不一样
字符串(string)
value的数据结构(数组)
- 字符串value数据结构类似于数组,采用与分配容易空间来减少内存频繁分配
- 当字符串长度小于1M时,扩容就是加倍现有空间
- 如果字符串长度操作1M时,扩容时最多扩容1M空间,字符串最大长度为 512M
字符串的使用场景(缓存)
- 字符串一个常见的用途是缓存用户信息,我们将用户信息使用JSON序列化成字符串
- 取用户信息时会经过一次反序列化的过程

list(列表)
value的数据结构(双向链表)
- 列表的数据结构是双向链表,这意味着插入和删除的时间复杂度是0(1),索引的时间复杂度位0(n)
- 当列表弹出最后一个元素后,该数据结构会被自动删除,内存被回手
列表的使用场景
- 队列
- 栈

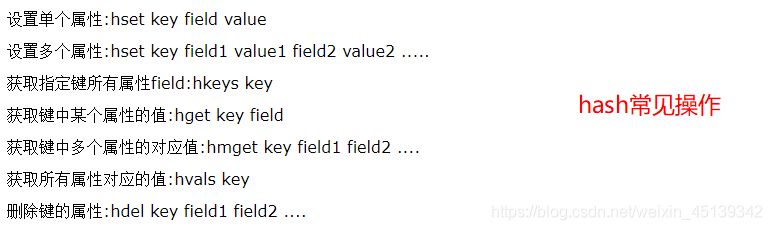
hash(哈希)
value的数据结构(HashMap)
- redis中的字典也是HashMap(数组+列表)的二维结构
- 不同的是redis的字典的值只能是字符串
hash的使用场景(缓存)
- hash结构也可以用来缓存用户信息,与字符串一次性全部序列化整个对象不同,hash可以对每个字段进行单独存储
- 这样可以部分获取用户信息,节约网络流量
- hash也有缺点,hash结构的存储消耗要高于单个字符串
set(集合)
value的数据结构(字典)
- redis中的集合相当于一个特殊的字典,字典的所有value都位null
- 当集合中的最后一个元素被移除后,数据结构会被自动删除,内存被回收
set使用场景
- set结构可以用来存储某个活动中中奖的用户ID,因为有去重功能,可以保证同一用户不会中间两次
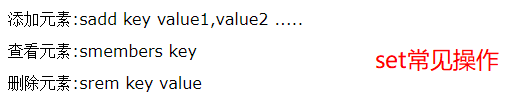
zset(有序集合)
value的数据结构(跳跃列表)
- zset一方面是一个set,保证了内部的唯一性
- 另一方面它可以给每一个value赋予一个score,代表这个value的权重
- zset内部实现用的是一种叫做“跳跃列表”的数据结构
- zset最后一个元素被移除后,数据结构就会被自动删除,内存也会被回收
zset应用场景
- 粉丝列表:value(粉丝ID),score(关注时间),这样可以轻松按关注事件排序
- 学生成绩:value(学生ID),score(考试成绩),这样可以轻松对成绩排序

