1. GBDT
假设我们前一轮迭代得到的强学习器是Ft−1(x), 损失函数是L(y,Ft−1(x)), 我们本轮迭代的目标是找到一个CART模型的弱学习器ft(x),让本轮的损失损失L(y, Ft (x))=L(y, Ft−1(x)+ft (x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
Adaboost(Adaboost弱学习器是二元分类器)属于GBDT,GBDT(GBDT弱学习器是CART回归树)又属于XGboost(XGboost的弱分类器可以是其他类型)
梯度下降法(Gradient Descent,GD)算法是求解最优化问题最简单、最直接的方法。梯度下降法是一种迭代的优化算法,对于优化问题:
minf(w)
其基本步骤为:

以上是在指定的参数空间中对最优参数进行搜索,那么,能否直接在函数空间(function space)中查找到最优的函数呢?根据上述的梯度下降法的思路,对于模型的损失函数L(y,F(X)),为了能够求解出最优的函数F∗(X),首先,设置初始值为:
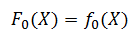
其中:
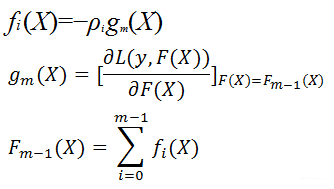
由于上述是一个求解梯度的过程,因此也称为基于梯度的Boost方法。GBDT无论做回归还是分类,所用的弱学习器全部是是cart回归树,因为只有回归树才有所谓的梯度提升。总体框架为:
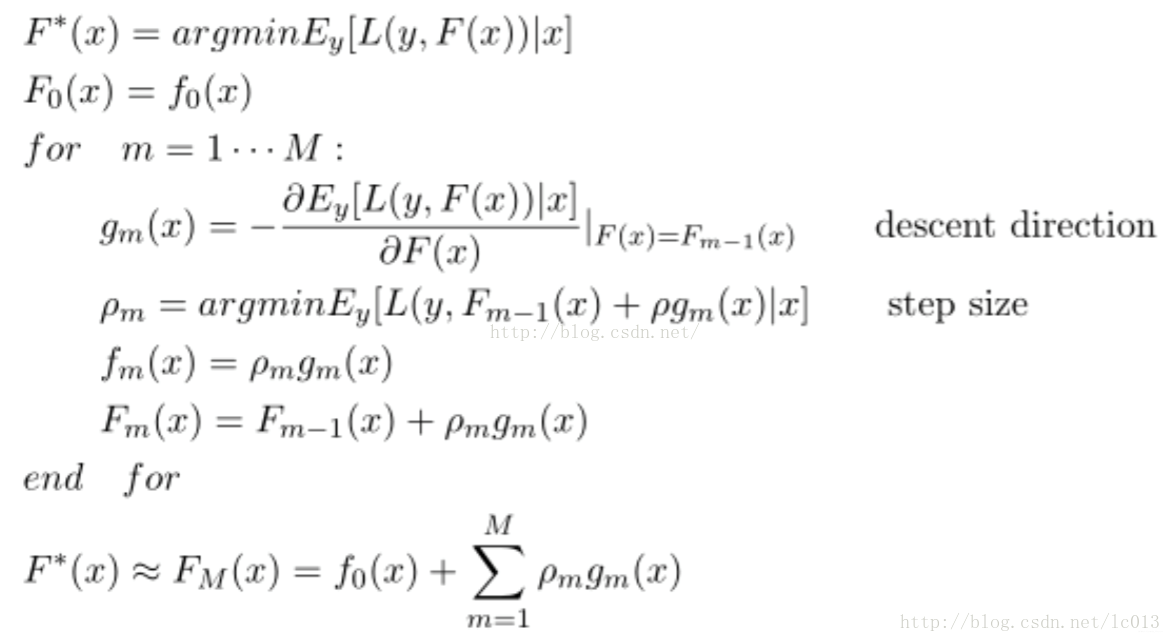
原始的boosting算法(Adaboost)开始时,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮迭代下去。如果解决的问题是二元分类问题,基函数是基本分类器(x属于某个集合y就取1,否则取-1),损失函数为指数损失函数L(y,F(x))=exp(-yF(x))时,GBDT就退化成了adaboost,因为adaboost的第m个基函数Gm(x)选择的时候也要满足强学习器Fm(x)的损失函数最小。
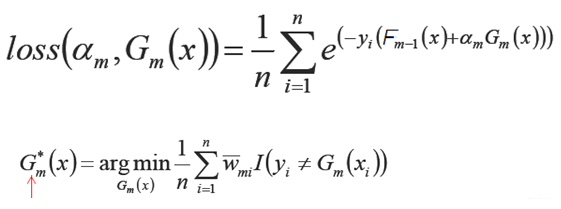
其中,w-mi=exp(-yiFm-1(x))是前m-1个基函数组成的强学习器的损失函数。
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。定义学习率ν, Fk(x)=Fk−1(x)+ νfk(x)。取值范围为0<ν≤1。对于同样的训练集学习效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。
1.1 GBDT用于回归问题



1.2 GBDT用于二元分类问题

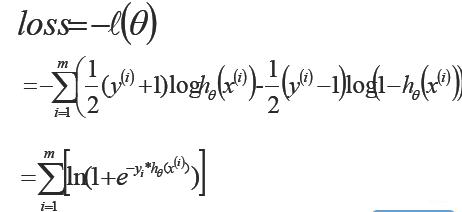

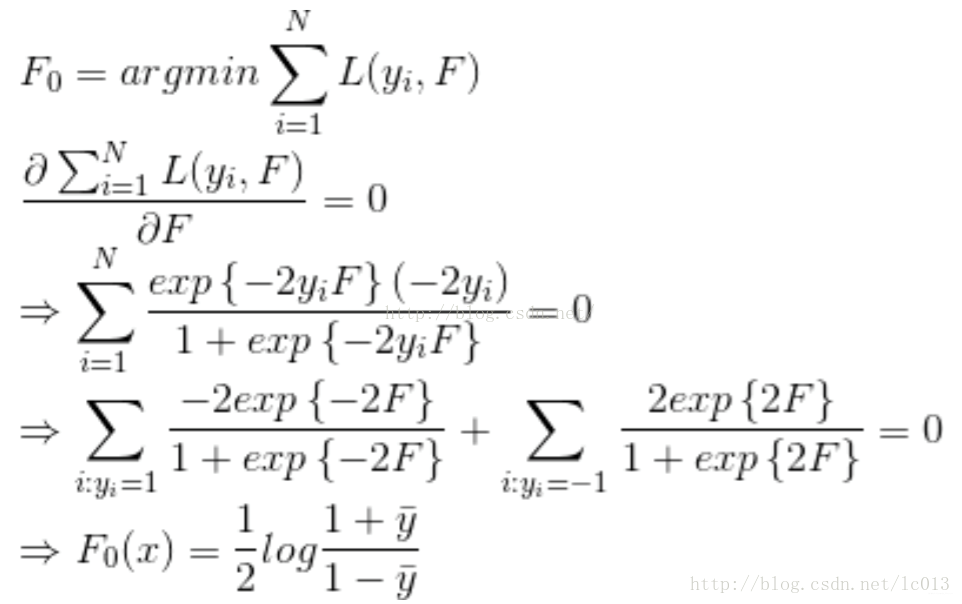

1.3 GBDT用于多元分类问题
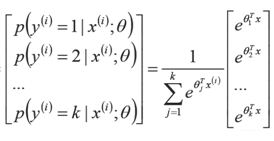
第k类的概率pk(x)的表达式为:
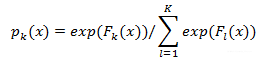
损失函数
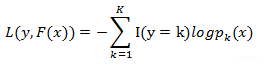

2. XGboost
模型的目标函数
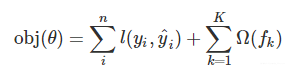
其中,
n: 样本个数
K:树的总棵数
fk:一棵具体的CART树,也就是弱学习器
强学习器的预测值:
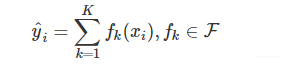
F表示所有可能的CART树
首先优化第一棵树,完了之后再优化第二棵树,直至优化完K棵树。假设我们已经有了t-1颗树,现在要得到第t颗:
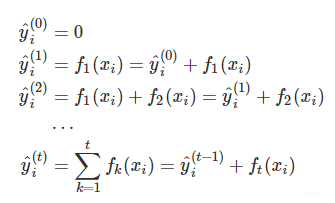
最优的ft(x)需要就是在现有的t-1棵树的基础上,使得目标函数最小:
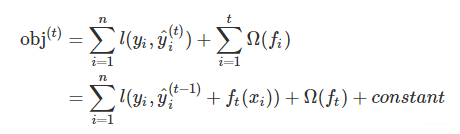
对于损失函数,我们需要将其作泰勒二阶展开,如下所示:
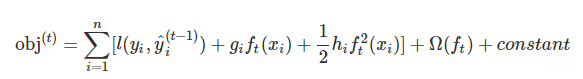
其中gi和hi的维度均和样本一致,可以利用自定义的损失函数求出,可以并行计算
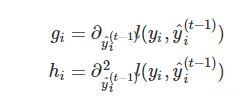
剩下三个变量,分别是第t棵CART树的一次式,二次式,和第t棵树的正则化项。再次提醒,这里所谓的树的一次式,二次式,其实都是某个叶子节点的值的一次式,二次式。常数项显然没有什么用,我们把它们去掉,就变成了下面这样:
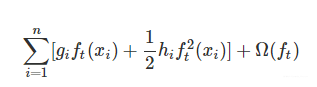
其中,
第t颗树的决策值为:
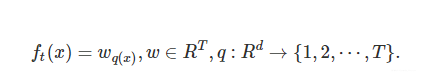
q(x)是一个映射,用来将样本映射到某个叶子节点,q(x)其实就代表了CART树的结构。Wq(x)自然就是这棵树对样本x的预测值了
正则项用来获得简单的树结构:
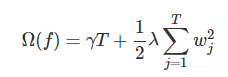
也就是说,目标可以写为
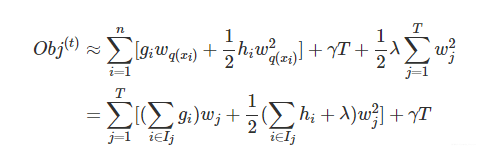
其中,Ij代表第t棵CART树上分到了第j个叶子节点上的训练样本的集合。
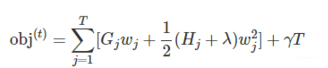
对于第t棵CART树的某一个确定的结构(可用q(x)表示),所有的Gj和Hj都是确定的。而且上式中各个叶子节点的值wj之间是互相独立的,求导可解得:
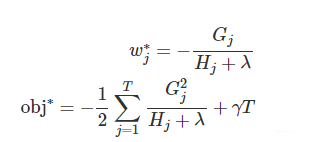
obj*只和Gj和Hj和T有关,而它们又只和树的结构(q(x))有关,与叶子节点的值可是半毛关系没有。wj*就是负的梯度乘以一个权重系数,hj越大表示该点附近梯度变化非常剧烈,导致权重系数(相当于GBDT里面的学习率)越小。
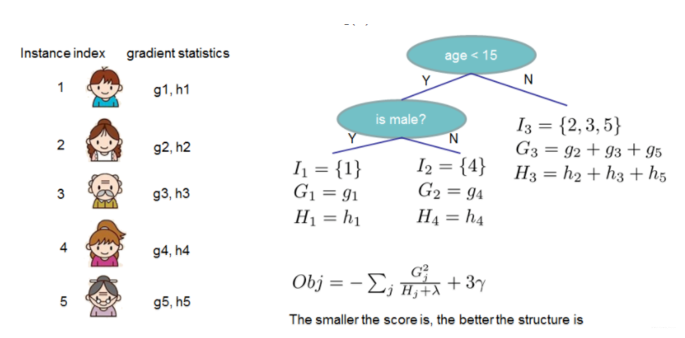
怎么得到一颗树的结构呢?按照这个图从左至右扫描,我们就可以找出所有的切分点
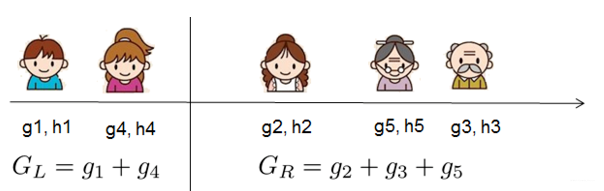
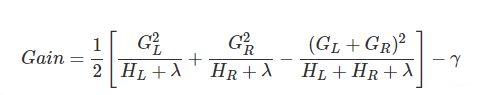
这个Gain实际上就是单节点的obj*减去切分后的两个节点的树obj * , Gain如果是正的,并且值越大,表示切分后obj*越小于单节点的obj*,就越值得切分。γ在这里实际上是一个临界值,它的值越大,表示我们对切分后obj下降幅度要求越严。xgboost的切分操作和普通的决策树切分过程是不一样的。普通的决策树在切分的时候并不考虑树的复杂度,而依赖后续的剪枝操作来控制。xgboost在切分的时候就已经考虑了树的复杂度,就是那个γ参数。所以,它不需要进行单独的剪枝操作。扫描结束后,我们就可以确定是否切分,如果切分,对切分出来的两个节点,递归地调用这个切分过程,我们就能获得一个相对较好的树结构。
总结一下:


附录 弱分类器—CART分类树
分类回归树CART算法是一种基于二叉树的机器学习算法,其既能处理回归问题,又能处理分类为题,在梯度提升决策树GBDT算法中,使用到的是CART回归树算法。对于一个包含了m个训练样本的回归问题,其训练样本为:
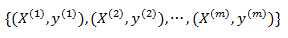
其中,X(i)为n维向量,表示的是第i个样本的特征,y(i)为样本的标签,在回归问题中,标签y(i)为一系列连续的值。此时,利用训练样本训练一棵CART回归树:
开始时,CART树中只包含了根结点,所有样本都被划分在根结点上

此时,计算该节点上的样本的方差(此处要乘以m),方差表示的是数据的波动程度。那么,根节点的方差的m倍为:
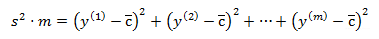
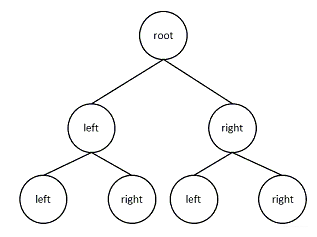
其中,c¯为标签的均值。此时,从n维特征中选择第j维特征,从m个样本中选择一个样本的值:xj作为划分的标准,当样本i的第j维特征小于等于xj时,将样本划分到左子树中,否则,划分到右子树中,通过以上的操作,划分到左子树中的样本个数为m1,划分到右子树的样本的个数为m2=m−m1,其划分的结果如下图所示
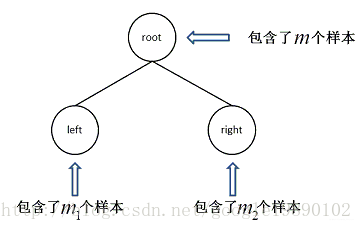
那么,什么样本的划分才是当前的最好划分呢?此时计算左右子树的方差之和
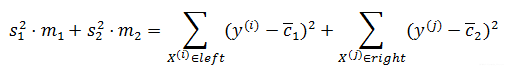
其中,c¯1为左子树中节点标签的均值,同理,c¯2为右子树中节点标签的均值.选择使上式最小的划分作为最终的划分,依次这样划分下去,直到得到最终的划分,划分的结果为: