xgboost是boosting Tree的一个很牛的实现,它在最近Kaggle比赛中大放异彩。它 有以下几个优良的特性:
- 显示的把树模型复杂度作为正则项加到优化目标中。
- 公式推导中用到了二阶导数,用了二阶泰勒展开。
- 实现了分裂点寻找近似算法。
- 利用了特征的稀疏性。
- 数据事先排序并且以block形式存储,有利于并行计算。
- 基于分布式通信框架rabit,可以运行在MPI和yarn上。(最新已经不基于rabit了)
- 实现做了面向体系结构的优化,针对cache和内存做了性能优化。
在项目实测中使用发现,Xgboost的训练速度要远远快于传统的GBDT实现,10倍量级。
1.传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。 —可以通过booster [default=gbtree]设置参数:gbtree: tree-based models/gblinear: linear models
2.传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。 —对损失函数做了改进(泰勒展开,一阶信息g和二阶信息h)
3.xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性
—正则化包括了两个部分,都是为了防止过拟合,剪枝是都有的,叶子结点输出L2平滑是新增的。
4.shrinkage and column subsampling —还是为了防止过拟合
(1)shrinkage缩减类似于学习速率,在每一步tree boosting之后增加了一个参数n(权重),通过这种方式来减小每棵树的影响力,给后面的树提供空间去优化模型。
(2)column subsampling列(特征)抽样,说是从随机森林那边学习来的,防止过拟合的效果比传统的行抽样还好(行抽样功能也有),并且有利于后面提到的并行化处理算法。
5.split finding algorithms(划分点查找算法):
(1)exact greedy algorithm—贪心算法获取最优切分点
(2)approximate algorithm— 近似算法,提出了候选分割点概念,先通过直方图算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征信息映射到不同的buckets中,并统计汇总信息。
(3)Weighted Quantile Sketch—分布式加权直方图算法
这里的算法(2)、(3)是为了解决数据无法一次载入内存或者在分布式情况下算法(1)效率低的问题,以下引用的还是wepon大神的总结:
可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
6.对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。 —稀疏感知算法
7.Built-in Cross-Validation(内置交叉验证)
XGBoost allows user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run.
This is unlike GBM where we have to run a grid-search and only a limited values can be tested.
8.continue on Existing Model(接着已有模型学习)
User can start training an XGBoost model from its last iteration of previous run. This can be of significant advantage in certain specific applications.
GBM implementation of sklearn also has this feature so they are even on this point.
9.High Flexibility(高灵活性)
**XGBoost allow users to define custom optimization objectives and evaluation criteria.
This adds a whole new dimension to the model and there is no limit to what we can do.**
10.并行化处理 —系统设计模块,块结构设计等
xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
此外xgboost还设计了高速缓存压缩感知算法,这是系统设计模块的效率提升。
当梯度统计不适合于处理器高速缓存和高速缓存丢失时,会大大减慢切分点查找算法的速度。
(1)针对 exact greedy algorithm采用缓存感知预取算法
(2)针对 approximate algorithms选择合适的块大小
我个人的理解,从算法实现的角度,把握一个机器学习算法的关键点有两个,一个是loss function的理解(包括对特征X/标签Y配对的建模,以及基于X/Y配对建模的loss function的设计,前者应用于inference,后者应用于training,而前者又是后者的组成部分),另一个是对求解过程的把握。这两个点串接在一起构成了算法实现的主框架。具体到XGBoost,也不出其外。
XGBoost的loss function可以拆解为两个部分,第一部分是X/Y配对的建模,第二部分是基于X/Y建模的loss function的设计。
2.1. X/Y建模
作为GBDT算法的具体实现,XGBoost代表了Tree Model的一个特例(boosting tree v.s. bagging tree),基本的思想用下图描述起来会更为直观:
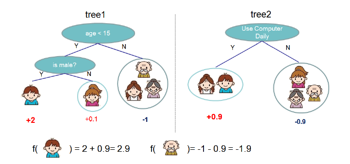
如果从形式化的角度来观察,则可以描述如下:

其中F代表一个泛函,表征决策树的函数空间,K表示构成GBDT模型的Tree的个数,T表示一个决策树的叶子结点的数目, w是一个向量。
看到上面X/Y的建模方式,也许我们会有一个疑问:上面的建模方式输出的会是一个浮点标量,这种建模方式,对于Regression Problem拟合得很自然,但是对于classification问题,怎样将浮点标量与离散分类问题联系起来呢?
理解这个问题,实际上,可以通过Logistic Regression分类模型来获得启发。
我们知道,LR模型的建模形式,输出的也会是一个浮点数,这个浮点数又是怎样跟离散分类问题(分类面)联系起来的呢?实际上,从广义线性模型[13]的角度,待学习的分类面建模的实际上是Logit[3],Logit本身是是由LR预测的浮点数结合建模目标满足Bernoulli分布来表征的,数学形式如下:
对上面这个式子做一下数学变换,能够得出下面的形式:
这样一来,我们实际上将模型的浮点预测值与离散分类问题建立起了联系。
相同的建模技巧套用到GBDT里,也就找到了树模型的浮点预测值与离散分类问题的联系:
考虑到GBDT应用于分类问题的建模更为tricky一些,所以后续关于loss function以及实现的讨论都会基于GBDT在分类问题上的展开,后续不再赘述。
2.2. Loss Function设计
分类问题的典型Loss建模方式是基于极大似然估计,具体到每个样本上,实际上就是典型的二项分布概率建模式[1]:
经典的极大似然估计是基于每个样本的概率连乘,这种形式不利于求解,所以,通常会通过取对数来将连乘变为连加,将指数变为乘法,所以会有下面的形式:
再考虑到loss function的数值含义是最优点对应于最小值点,所以,对似然估计取一下负数,即得到最终的loss形式,这也是经典的logistic loss[2]:
有了每个样本的Loss,样本全集上的Loss形式也就不难构造出来:
2.3. 求解算法
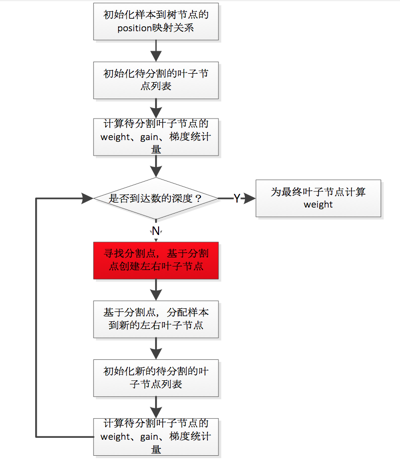
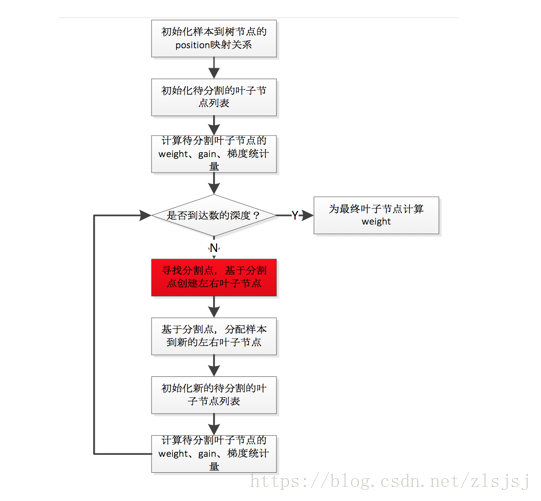
GBDT的求解算法,具体到每颗树来说,其实就是不断地寻找分割点(split point),将样本集进行分割,初始情况下,所有样本都处于一个结点(即根结点),随着树的分裂过程的展开,样本会分配到分裂开的子结点上。分割点的选择通过枚举训练样本集上的特征值来完成,分割点的选择依据则是减少Loss。
给定一组样本,实际上存在指数规模的分割方式,所以这是一个NP-Hard的问题,实际的求解算法也没有办法在多项式时间内完成求解,而是采用一种基于贪心原则的启发式方法来完成求解。 也就是说,在选取分割点的时候,只考虑当前树结构到下一步树结构的loss变化的最优值,不考虑树分裂的多个步骤之间的最优值,这是典型的greedy的策略。
在XGBoost的实现, 为了便于求解,对loss function基于Taylor Expansion进行了变换:
在变换完之后的形式里, 就是为了优化loss function,待更新优化的变量(这里的变量是一个广义的描述)。
上面的loss function是针对一个样本而言的,所以,对于样本全集来说,loss function的形式是:
对这个loss function进行优化的过程,实际上就是对第k个树结构进行分裂,找到启发式的最优树结构的过程。而每次分裂,对应于将属于一个叶结点(初始情况下只有一个叶结点,即根结点)下的训练样本分配到分裂出的两个新叶结点上(对应一阶导数和二阶导数),每个叶结点上的训练样本都会对应一个模型学出的概率值,而loss function本身满足样本之间的累加特性,所以,可以通过将分裂前的叶结点上样本的loss function和与分裂之后的两个新叶结点上的样本的loss function之和进行对比,从而找到可用的分裂特征以及特征分裂点。
而每个叶结点上都会附著一个weight,这个weight会用于对落在这个叶结点上的样本打分使用,所以叶结点weight的赋值,也会影响到loss function的变化。基于这种考虑,也许将loss function从样本维度转移到叶结点维度也许更为自然,于是就有了下面的形式:
上面的loss function,本质上是一个包含T(T对应于Tree当前的叶子结点的个数)个自变量的二次函数,这也是一个convex function,所以,可以通过求函数极值点的方式获得最优解析解(偏导数为0的点对应于极值点),其形如下:
现在,我们可以把求解过程串接梳理一下:
I. 对loss function进行二阶Taylor Expansion,展开以后的形式里,当前待学习的Tree是变量,需要进行优化求解。
II. Tree的优化过程,包括两个环节:
I). 枚举每个叶结点上的特征潜在的分裂点
II). 对每个潜在的分裂点,计算如果以这个分裂点对叶结点进行分割以后,分割前和分割后的loss function的变化情况。
因为Loss Function满足累积性(对MLE取log的好处),并且每个叶结点对应的weight的求取是独立于其他叶结点的(只跟落在这个叶结点上的样本有关),所以,不同叶结点上的loss function满足单调累加性,只要保证每个叶结点上的样本累积loss function最小化,整体样本集的loss function也就最小化了。
而给定一个叶结点,可以通过求取解析解计算出这个叶结点上样本集的loss function最小值。
有了上面的两个环节,就可以找出基于当前树结构,最优的分裂点,完成Tree结构的优化。
这就是完整的求解思路。有了这个求解思路的介绍,我们就可以切入到具体实现细节了。
注意,实际的求解过程中,为了避免过拟合,会在Loss Function加入对叶结点weight以及叶结点个数的正则项,所以具体的优化细节会有微调,不过这已经不再影响问题的本质,所以此处不再展开介绍。
从上面的代码主流程可以看到,在XGBoost的实现中,对算法进行了模块化的拆解,几个重要的部分分别是:
I. ObjFunction:对应于不同的Loss Function,可以完成一阶和二阶导数的计算。
II. GradientBooster:用于管理Boost方法生成的Model,注意,这里的Booster Model既可以对应于线性Booster Model,也可以对应于Tree Booster Model。
III. Updater:用于建树,根据具体的建树策略不同,也会有多种Updater。比如,在XGBoost里为了性能优化,既提供了单机多线程并行加速,也支持多机分布式加速。也就提供了若干种不同的并行建树的updater实现,按并行策略的不同,包括:
I). inter-feature exact parallelism (特征级精确并行)
II). inter-feature approximate parallelism(特征级近似并行,基于特征分bin计算,减少了枚举所有特征分裂点的开销)
III). intra-feature parallelism (特征内并行)
IV). inter-node parallelism (多机并行)
此外,为了避免overfit,还提供了一个用于对树进行剪枝的updater(TreePruner),以及一个用于在分布式场景下完成结点模型参数信息通信的updater(TreeSyncher),这样设计,关于建树的主要操作都可以通过Updater链的方式串接起来,比较一致干净,算是Decorator设计模式[4]的一种应用。