说到提高检索效率,就必然提到索引。今天就来为大家讲述搜索引擎中最常见的索引方式——倒排索引。
索引之所以快的原因,是因为有序(从计算机的角度讲,有序就可以使用二分查找,这是十分高效的)。
词汇文档矩阵
我们发现我们最终要做的其实是对词做索引。那么我们要怎么做呢?首先我们可以做一个“词汇-文档矩阵”,横坐标为文档id,纵坐标为具体词汇。
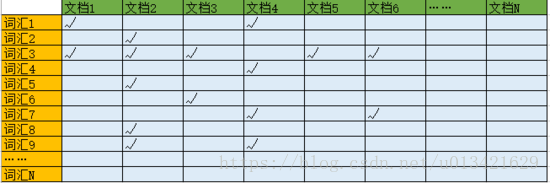
我们可以让纵坐标的词汇有序排列(比如按照字母/拼音顺序排列),这样我们就可以快速的定位到一个词汇。然后我们再去找都有哪些文档对应着这些词汇。但是“词汇-文档矩阵”只是一个概念模型,我们如何在计算机中使用数据结构实现这个概念呢?
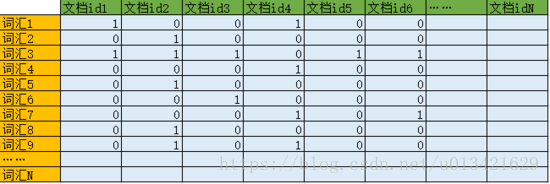
最简单的方法就是,直接这么存。先存储一个有序的文档id数组,然后在存储一个词汇数组。之后创建一个二维数组,数组的横坐标长度和文档id数组长度相同,纵坐标长度和词汇数组相同,然后在这个二维数组的元素中存储1或0。1代表对应位置的文档包含对应位置的词汇,0代表不包含。如图所示:
倒排索引
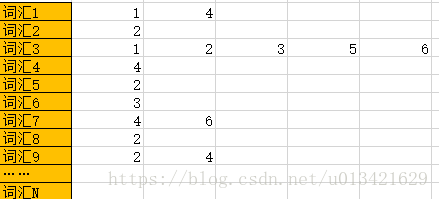
那么我们要如何优化这个结构呢?我们不难发现这个矩阵其实具有高度的稀疏性(大量的值为0)。毕竟不可能每本书都有50万个不同的词,如果考虑到大量的论文或者博客的话,可能平均一篇文献中能有1000个不一样的词都很不容易了。这就意味着这个矩阵中99%的元素都为0。这样我们很容易想到,那我们就只记录那些1不就可以了。也就是说我们只要根据词汇去记录那些包含这个词汇的文档就可以了。这样同样我们要维护一个词汇数组,然后词汇数组中的每个元素(也就是每个词汇)都会对应一个文档列表,这个文档列表中保存的是,具有这个词汇的文档的id。这样就极大的节省了存储空间。结构如下:
以上就是倒排索引的一些基本概念。