我们知道java面试中,HashMap出现的频率是很高的。我们就来分析一下HashMap的常用知识点。
HashMap底层数据结构
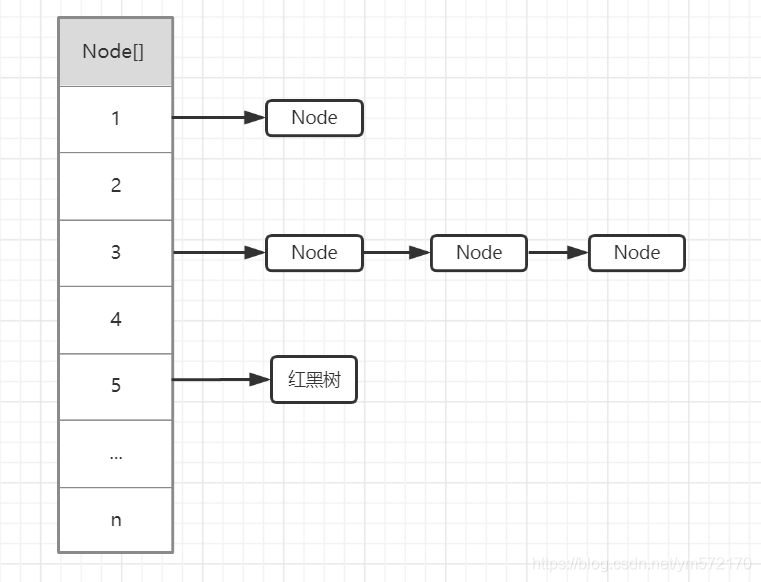
我们看到HashMap内部是使用数据+链表/红黑树的(jdk1.8之后加入了红黑树)结构存储的。
HashMap主要参数
- DEFAULT_INITIAL_CAPACITY:初始化容量,默认值16,容量大小需要是2的整数倍。
- MAXIMUM_CAPACITY:容量的最大值,默认值2的30次幂。
- DEFAULT_LOAD_FACTOR:加载因子,默认值0.75f,这个值和容量的乘积就是阈值,当达到阈值时候会产生扩容,扩容的大小大约为原来的二倍。
- TREEIFY_THRESHOLD:默认值8,jdk8以后,HashMap底层的存储结构改为了数组+链表+红黑树的存储结构,当链表长度大于这个参数时,链表就可能会转化为红黑树。
- UNTREEIFY_THRESHOLD: 默认值6,当链表元素等于这个值时,就会从红黑树再转为链表。
- MIN_TREEIFY_CAPACITY:默认值64,跟TREEIFY_THRESHOLD一起使用,当数组长度大于这个值且数组元素的链表长度大于8时会转为红黑树。
HashMap存取原理
下面流程图展示了往HashMap存放一个元素,经历了哪些操作:
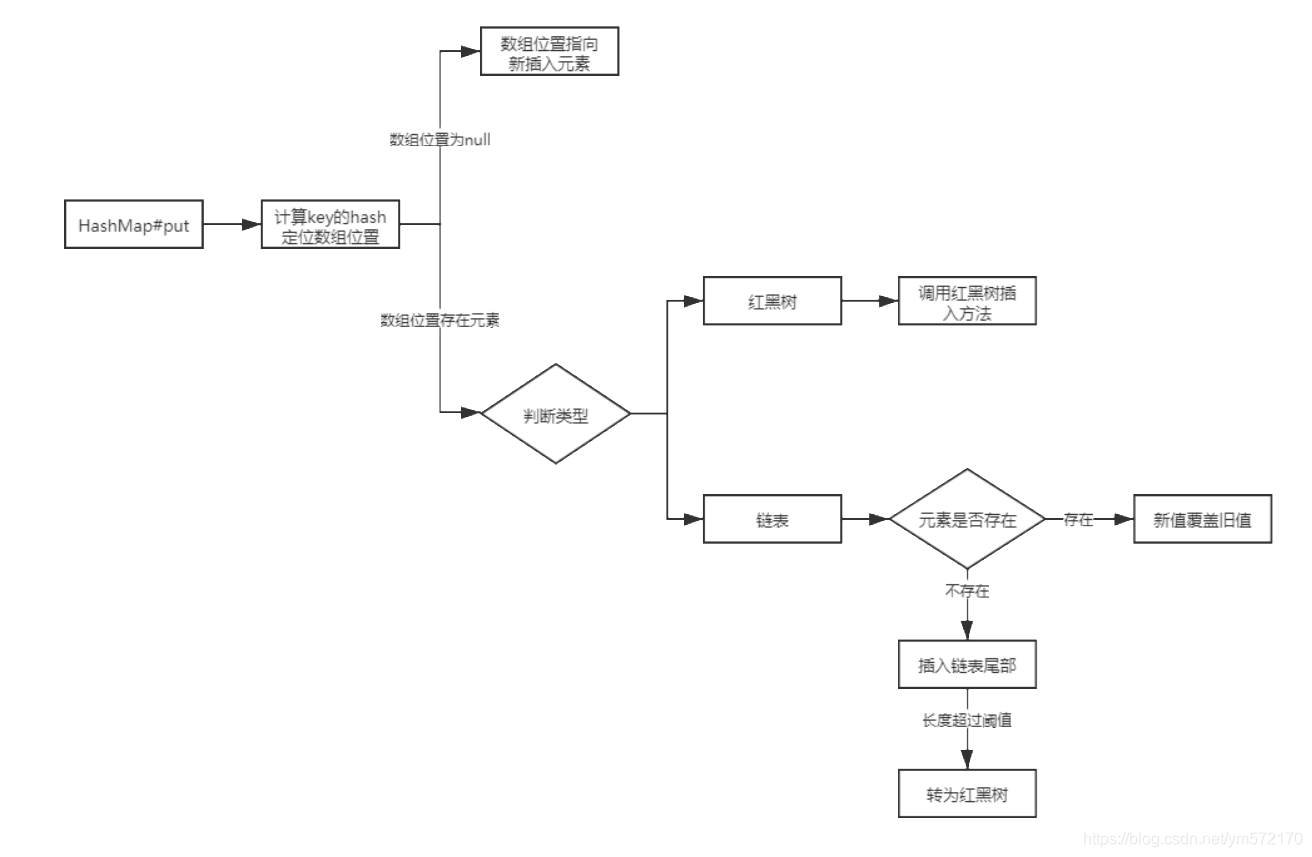
从上图可以看出,我们往HashMap存放一个值,主要经历了以下逻辑:
- 计算key的hash值,得出一个int整数值,主要确定元素应放在数组的哪个位置上
- 找到存放数组的位置后,查看数组位置是否已有元素存在,若没有其它元素,则将新插入的元素放入数组位置;若已存在其它元素,则判断数组元素是红黑树还是链表,从而做不同的处理:
1.数组元素是红黑树,则调用红黑树插入元素方法
2.数组元素是链表,则遍历链表判断元素是否已存在,若已存在,则用新插入的元素替换旧的元素;若不存在,则新插入的元素插入链表的尾部,插入成功后,若长度超过阈值,则把链表转为红黑树。
3.插入元素后,判断集合数量是否超过了阈值,从而决定需不需要扩容。
上面就是HashMap存放一个元素的逻辑,若要获取一个元素则逻辑类似,主要经历以下步骤:
- 计算key的hash值,得出一个int整数值,判断元素存放的数组位置
- 查看数组位置的元素,若为null,则直接返回null;不为null则判断数组位置元素是红黑树还是链表:
1.数组元素是红黑树,则调用红黑树查找元素方法
2.数组元素是链表,则遍历链表查找元素。
HashMap扩容机制
HashMap在什么情况下会扩容呢?主要依赖于以下两个因素:
- HashMap当前容量
- 负载因子(默认值0.75f)
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就进行扩容。
那么是如何进行扩容的呢?主要经历以下两步:
- 创建一个新的Entry空数组,长度是原数组的2倍。
- 遍历原Entry数组,把所有的元素重新Hash到新数组。
这边为什么要重新Hash呢?
这是因为长度扩大以后,Hash的规则也随之改变。因为我们在计算Hash时,需要跟数组的长度做位运算,从而判断元素应该存取在数组的哪个位置上。
// Length 是数组的长度
index = HashCode(Key) & (Length - 1)
HashMap线程同步
我们都知道HashMap是非线程安全的,可以用以下方式实现线程安全:
- 使用Collections.synchronizedMap(Map)创建线程安全的map集合
- Hashtable
- ConcurrentHashMap
不过我们一般选择使用ConcurrentHashMap实现线程安全,它的性能和效率要高于前两者。
